大家好,我是辣条。?
今天主要分享一个粉丝朋友找我帮他爬一个妹子图网站,不过网站图片尺度比较大,所以也不留链接了,虽然比较简单,但还是很有学习意义的,我这绝不是水文章!学习的事当然要分享给大家。

?
?
效果展示

采集数据目标
网站:不提供(狗头保命,防止进小黑屋)

工具使用
开发工具:pycharm
开发环境:python3.7, Windows10
使用工具包:requests,lxml
重点学习内容
项目解析思路
获取到首页信息,通过requests请求网页数据,当前网页数据为动态加载数据。

url参数修改请求其他页面,通过xpath方式提取到进入详情页面的网址,详情页面的信息会更加的精彩。


提取到进入详情页面的a标签,再次请求网页数据,得到详情页面数据,再次通过xpath方式获取到图片的标签以及图片的名字,要注意的是img标签里的图片地址其实是动态图,我们需要获取的数据是div标签里的data-src。
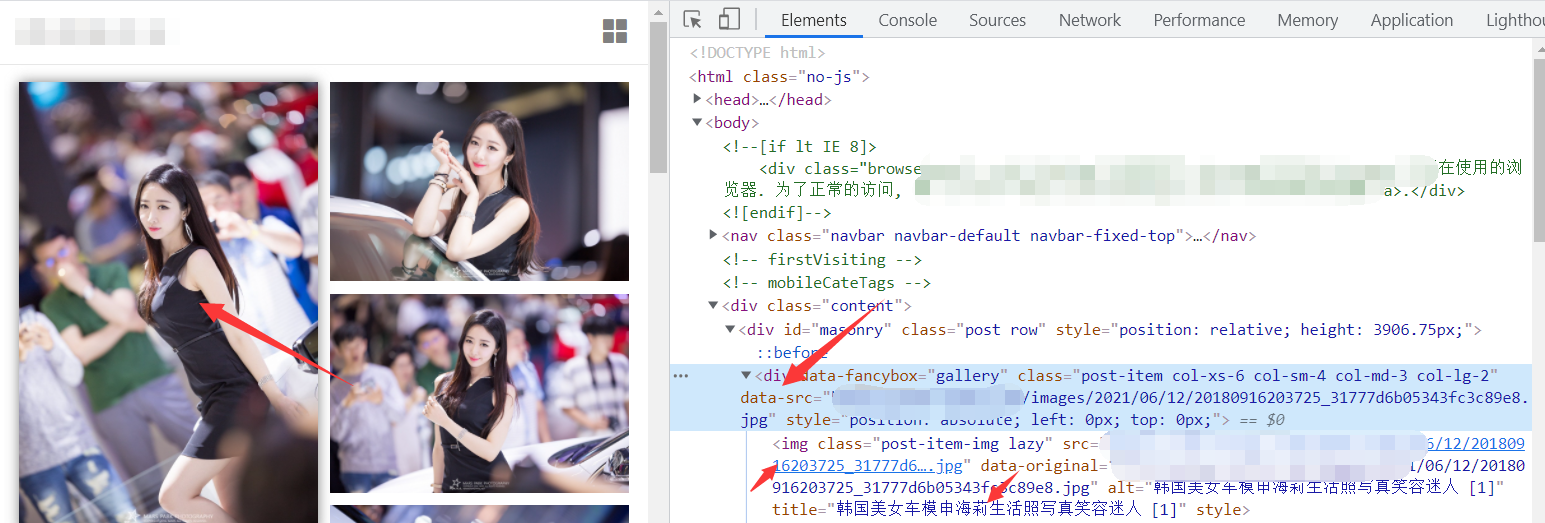
获取到对应图片标签,保存对应图片数据 大功告成!!!
需要网站地址关注三连+私?我获取【仅供学习交流,一定要三连收藏哦,不然容易找不着】
简易源码分享
import requests
from lxml import etree
?
?
?
url = 'https://www.xxxx.com/page/4/'
response = requests.get(url)
html = etree.HTML(response.text)
href_list = html.xpath('//div[@class="item-title"]/a/@href')
for href in href_list:
? ?res = requests.get(href)
? ?html_data = etree.HTML(res.text)
? ?img_url_list = html_data.xpath('//div[@data-fancybox="gallery"]/@data-src')
? ?img_name_list = html_data.xpath('//img/@alt')
? ?print(img_url_list)
? ?for img_url, img_name in zip(img_url_list, img_name_list):
? ? ? ?result = requests.get(img_url).content
? ? ? ?with open('图片/' + img_name + ".jpg", "wb")as f:
? ? ? ? ? ?f.write(result)
? ? ? ? ? ?print("正在下载:", img_name)
?
仅供学习交流!!侵删!

cs