第八章 数据结构:栈,队列,哈希表,堆
栈 Stack?
我们在前面的二叉树的学习中,已经学习了如何使用 Stack 来进行非递归的二叉树遍历。
这里我们来看看栈在面试中的其他一些考点和考题:
- 如果自己实现一个栈?
- 如何用两个队列实现一个栈?
- 用一个数组如何实现三个栈?
如何实现一个栈??
什么是栈(Stack)?
栈(stack)是一种采用后进先出(LIFO,last in first out)策略的抽象数据结构。比如物流装车,后装的货物先卸,先转的货物后卸。栈在数据结构中的地位很重要,在算法中的应用也很多,比如用于非递归的遍历二叉树,计算逆波兰表达式,等等。
栈一般用一个存储结构(常用数组,偶见链表),存储元素。并用一个指针记录栈顶位置。栈底位置则是指栈中元素数量为0时的栈顶位置,也即栈开始的位置。
栈的主要操作:
push(),将新的元素压入栈顶,同时栈顶上升。pop(),将新的元素弹出栈顶,同时栈顶下降, 返回值为空。empty(),栈是否为空。top(),返回栈顶元素。
栈在计算机内存当中的应用
我们在程序运行时,常说的内存中的堆栈,其实就是栈空间。这一段空间存放着程序运行时,产生的各种临时变量、函数调用,一旦这些内容失去其作用域,就会被自动销毁。
函数调用其实是栈的很好的例子,后调用的函数先结束,所以为了调用函数,所需要的内存结构,栈是再合适不过了。在内存当中,栈从高地址不断向低地址扩展,随着程序运行的层层深入,栈顶指针不断指向内存中更低的地址。
?
如何用两个队列实现一个栈??
算法步骤
两个队列实现一个栈,其实并没有什么优雅的办法。就看大家怎么去写这个东西了。
- 构造的时候,初始化两个队列,
queue1,queue2。queue1主要用来存储,queue2则主要用来帮助queue1弹出元素以及访问栈顶。 - push:将元素推入
queue1当中。 - pop:注意要弹出的元素在
queue1末端,故将queue1中元素弹出,并直接推入queue2,当queue1只剩一个元素时,把它pop出来,并作为结果。而后交换两个队列。 - top:类似pop,不过不扔掉
queue1中最后一个元素,而是把它也推入queue2当中。 - isEmpty:判断
queue1是否为空即可。
?
如何用一个数组实现三个栈??
算法描述
这道题的本质是把数组索引当作地址,用链表来实现栈。数组buffer中的每一个元素,并不能单单是简单的int类型,而是一个链表中的节点,它包含值value,栈中向栈底方向的之前元素索引prev,向栈顶方向的后来元素索引next。
在该三栈数据结构中,要记录三个栈顶指针stackPointer,也就是三个栈顶所在的数组索引,通过这三个栈顶节点,能够用prev找到整串栈。
此外还要用indexUsed记录整个数组中的所用的索引数。其实也就是下一次push的时候,向数组的indexUsed位置存储。
具体操作:
- 构造:要初始化
stackPointer为3个-1,表示没有;indexUsed=0;buffer为一个长度为三倍栈大小的数组。 - push:要把新结点new在
buffer[indexUsed],同时修改该栈的stackPointer,indexUsed自增。注意修改当前栈顶结点prev和之前栈顶结点的next索引。 - peek:只需要返回
buffer中对应的stackPointer即可。 - isEmpty:只需判断
stackPointer是否为-1。 - pop:pop的操作较为复杂,因为有三个栈,所以栈顶不一定在数组尾端,pop掉栈顶之后,数组中可能存在空洞。而这个空洞又很难
push入元素。所以,解决方法是,当要pop的元素不在数组尾端(即indexUsed-1)时,交换这两个元素。不过一定要注意,交换的时候,要注意修改这两个元素之前、之后结点的prev和next指针,使得链表仍然是正确的,事实上这就是结点中next的作用――为了找到之后结点并修改它的prev。在交换时,一种很特殊的情况是栈顶节点刚好是数组尾端元素的后继节点,这时需要做特殊处理。在交换完成后,就可以删掉数组尾端元素,并修改相应的stackPointer、indexUsed和新栈顶的next。
队列 Queue
如何用链表实现队列
定义
- 队列为一种先进先出的线性表
- 只允许在表的一端进行入队,在另一端进行出队操作。在队列中,允许插入的一端叫队尾,允许删除的一端叫队头,即入队只能从队尾入,出队只能从队头出
思路
- 需要两个节点,一个头部节点,也就是dummy节点,它是在加入的第一个元素的前面,也就是dummy.next=第一个元素,这样做是为了方便我们删除元素,还有一个尾部节点,也就是tail节点,表示的是最后一个元素的节点
- 初始时,tail节点跟dummy节点重合
- 当我们要加入一个元素时,也就是从队尾中加入一个元素,只需要新建一个值为val的node节点,然后tail.next=node,再移动tail节点到tail.next
- 当我们需要删除队头元素时,只需要将dummy.next变为dummy.next.next,这样就删掉了第一个元素,这里需要注意的是,如果删掉的是队列中唯一的一个元素,那么需要将tail重新与dummy节点重合
- 当我们需要得到队头元素而不删除这个元素时,只需要获得dummy.next.val就可以了
?
class QueueNode {
public:
int val;
QueueNode *next;
QueueNode(int value) {
val = value;
}
};
class Queue {
private:
QueueNode* dummy;
QueueNode* tail;
public:
Queue() {
dummy = new QueueNode(-1);
tail = dummy;
}
void push(int val) {
QueueNode *node = new QueueNode(val);
tail->next = node;
tail = node;
}
void pop() {
dummy->next = dummy->next->next;
if (dummy->next == null) {
tail = dummy;// reset
}
}
int peek() {
int ele = dummy->next->val;
return ele;
}
bool empty() {
return dummy->next == null;
}
};
?
如何用两个栈实现队列
思路:
现在我们已经有了两个栈stack1和stack2,最暴力的做法,当需要往队列中加入元素时,可以往其中一个栈stack2中加入元素,当需要得到队头元素时,只需要将stack2中的元素倒入到stack1中,再取stack1的头元素就可以了,如果是需要删掉队头元素,那么直接pop stack1的栈顶元素就可以了,其实当我们将stack2中的元素倒入到stack1中的时候,我们发现stack1中的元素的顺序就是按照队列的先进先出顺序,那么我们不再将stack1中的元素倒入到stack2中,在获取队头元素或者删除队头元素的时候,我们先判断stack1是否为空,如果不为空,从stack1中取即可,如果为空,那么将stack2中的元素倒入到stack1中,每次加入元素的时候都是往stack2中加入元素。
?
什么是循环数组,如何用循环数组实现队列??
什么是循环数组
Circular array = a data structure that used a array as if it were connected end-to-end
?
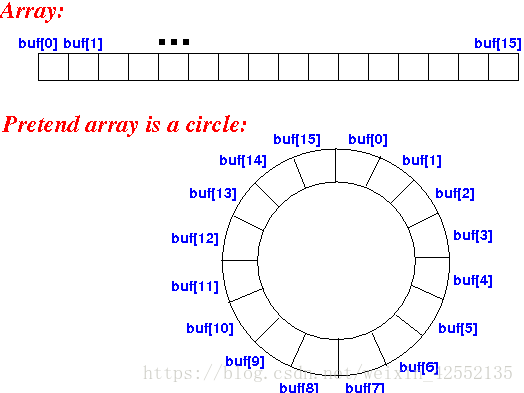
如何实现队列
- 我们需要知道队列的入队操作是只在队尾进行的,相对的出队操作是只在队头进行的,所以需要两个变量front与rear分别来指向队头与队尾
- 由于是循环队列,我们在增加元素时,如果此时 rear = array.length - 1 ,rear 需要更新为 0;同理,在元素出队时,如果 front = array.length - 1, front 需要更新为 0. 对此,我们可以通过对数组容量取模来更新。
?
哈希表 Hash
哈希表( unordered_map)是面试中非常常见的数据结构。它的主要考点有两个:
- 是否会灵活的使用哈希表解决问题
- 是否熟练掌握哈希表的基本原理
这一小节中,我们将介绍一下哈希表原理中的几个重要的知识点:
- 哈希表的工作原理
- 为什么 hash 上各种操作的时间复杂度不能单纯的认为是 O(1) 的
- 哈希函数(Hash Function)该如何实现
- 哈希冲突(Collision)该如何解决
- 如何让哈希表可以不断扩容?
?
哈希表的基本原理
O(size of key) = O(L)
class Solution {
public:
int hashCode(string &key, int HASH_SIZE) {
// write your code here
int n = key.size();
int hash_value = 0;
for (int i = 0; i < n; i++){
hash_value = (1LL * hash_value*33 + key[i]) % HASH_SIZE;
}
return hash_value;
}
};
冲突的解决办法
冲突(Collision),是说两个不同的 key 经过哈希函数的计算后,得到了两个相同的值。解决冲突的方法,主要有两种:
- 开散列法(Open Hashing)。是指哈希表所基于的数组中,每个位置是一个 Linked List 的头结点。这样冲突的 <key, value> 二元组,就都放在同一个链表中。
- 闭散列法(Closed Hashing)。是指在发生冲突的时候,后来的元素,往下一个位置去找空位。
?
?重哈希
?很慢的过程
?
堆 Heap?
Heap 的结构和原理?
logn => add(element)
logn => pop()
o(1) => min/max
min heap:父亲比儿子小
max heap: 父亲比儿子大
use array to implement the heap.
?0 1 2 3 4 5
[5,1,2,3,4,5,x,x,x,x,x,]
father: (k - 1)/2
left child: k * 2 + 1
right child: k * 2 + 2
?
堆化 Heapify?
sift-up:
算法思路:
- 对于每个元素A[i],比较A[i]和它的父亲结点的大小,如果小于父亲结点,则与父亲结点交换。
- 交换后再和新的父亲比较,重复上述操作,直至该点的值大于父亲。
时间复杂度分析:
- 对于每个元素都要遍历一遍,这部分是 O(n)。
- 每处理一个元素时,最多需要向根部方向交换 logn 次。
因此总的时间复杂度是 O(nlogn)
class Solution {
private:
void siftup(vector<int> A, int k) {
while (k != 0) {
int father = (k - 1) / 2;
if (A[k] > A[father]) {
break;
}
swap(A[k],A[father]);
k = father;
}
}
public:
void heapify(vector<int> A) {
for (int i = 0; i < A.size(); i++) {
siftup(A, i);
}
}
}
Sift-down:
算法思路:
- 初始选择最接近叶子的一个父结点,与其两个儿子中较小的一个比较,若大于儿子,则与儿子交换。
- 交换后再与新的儿子比较并交换,直至没有儿子。
- 再选择较浅深度的父亲结点,重复上述步骤。
时间复杂度分析
这个版本的算法,乍一看也是 O(nlogn), 但是我们仔细分析一下,算法从第 n/2 个数开始,倒过来进行 siftdown。也就是说,相当于从 heap 的倒数第二层开始进行 siftdown 操作,倒数第二层的节点大约有 n/4 个, 这 n/4 个数,最多 siftdown 1次就到底了,所以这一层的时间复杂度耗费是 O(n/4),然后倒数第三层差不多 n/8 个点,最多 siftdown 2次就到底了。所以这里的耗费是 O(n/8 * 2), 倒数第4层是 O(n/16 * 3),倒数第5层是 O(n/32 * 4) ... 因此累加所有的时间复杂度耗费为:O(n)
class Solution {
private:
void siftdown(vector<int> A, int k) {
while (k * 2 + 1 < A.size()) {
int son = k * 2 + 1; // A[i] 的左儿子下标。
if (k * 2 + 2 < A.size() && A[son] > A[k * 2 + 2])
son = k * 2 + 2; // 选择两个儿子中较小的。
if (A[son] >= A[k])
break;
swap(A[son], A[k]);
k = son;
}
}
public:
void heapify(vector<int> A) {
//从较浅深度的父节点开始
for (int i = (A.size()- 1) / 2; i >= 0; i--) {
siftdown(A, i);
}
}
}
红黑树 Red-black Tree?
红黑树(Red-black Tree)是一种平衡排序二叉树(Balanced Binary Search Tree),在它上面进行增删查改的平均时间复杂度都是 O(logn)
在C++当中,红黑树即是默认的set和map,其元素也是有序的。
cs