前言
本文隶属于专栏《1000个问题搞定大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见1000个问题搞定大数据技术体系
正文
假设 RDD 中的两行数据长这样

那么 DataFrame 中的数据长这样

Dataset 中的数据长这样
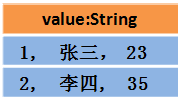
或者长这样(每行数据是个Object)

Dataset包含了DataFrame的功能,Spark2.0中两者统一,DataFrame表示为Dataset[Row],即Dataset的子集。
(1)Dataset可以在编译时检查类型
(2)并且是面向对象的编程接口
关于 DataFrame 请参考我的博客——DataFrame 是什么?
关于 RDD 和 DataFrame 的区别请参考我的博客——RDD 和 DataFrame 的区别是什么?
源码解读(3.3.0-SNAPSHOT)
@Stable
class Dataset[T] private[sql](
@DeveloperApi @Unstable @transient val queryExecution: QueryExecution,
@DeveloperApi @Unstable @transient val encoder: Encoder[T])
extends Serializable
Dataset 是什么?
Dataset 是特定域的对象的强类型集合,可以使用函数或关系操作进行并行转换。
每个 Dataset 还有一个称为 DataFrame 的非类型化视图,它是 Row 的数据集。
Dataset 的操作
Dataset 上可用的操作分为转换和动作。
转换是产生新 Dataset 的转换,动作是触发计算并返回结果的转换。
举例说明, 转换包括map、filter、select和aggregate(groupBy)。
动作包括count、show 或将数据写入文件系统。
Dataset 是“惰性”的,即只有在调用某个操作时才会触发计算。
在内部,Dataset 表示描述生成数据所需计算的逻辑计划。
当一个动作被调用时,Spark的查询优化器会优化逻辑计划并生成一个物理计划,以便以并行和分布式的方式高效地执行。
要探索逻辑计划以及优化的物理计划,请使用explain函数。
编码器(Encoder)
为了有效地支持特定领域的对象,需要一个编码器。
编码器将特定于域的类型T映射到Spark的内部类型系统。
例如,给定一个类Person,它有两个字段name(string)和age(int),编码器用来告诉Spark在运行时生成代码,将Person对象序列化为二进制结构。
这种二进制结构通常具有较低的内存占用,并针对数据处理的效率进行了优化(例如,以 Column 格式)。
要理解数据的内部二进制表示,请使用schema函数。
创建 Dataset
创建 Dataset 通常有两种方法。
最常见的方法是使用SparkSession上的read函数,将Spark指向存储系统上的某些文件。
val people = spark.read.parquet("...").as[Person]
Dataset<Person> people = spark.read().parquet("...").as(Encoders.bean(Person.class));
还可以通过现有 Dataset 上可用的转换来创建 Dataset。
例如,以下内容通过对现有数据集应用筛选器来创建新数据集:
val names = people.map(_.name)
Dataset<String> names = people.map((Person p) -> p.name, Encoders.STRING));
取消类型化(untyped)
Dataset 操作也可以通过在中定义的各种域特定语言(DSL)函数来取消类型化:
Dataset (当前类), [[Column]], and [[functions]]。
这些操作与R或Python中的数据帧抽象中可用的操作非常相似。
Column
要从 Dataset 中选择 column ,请使用Scala中的apply方法和Java中的col。
val ageCol = people("age")
Column ageCol = people.col("age");
请注意,[[Column]] 类型也可以通过其各种函数进行操作。
people("age") + 10
people.col("age").plus(10);
更具体的例子:
val people = spark.read.parquet("...")
val department = spark.read.parquet("...")
people.filter("age > 30")
.join(department, people("deptId") === department("id"))
.groupBy(department("name"), people("gender"))
.agg(avg(people("salary")), max(people("age")))
Dataset<Row> people = spark.read().parquet("...");
Dataset<Row> department = spark.read().parquet("...");
people.filter(people.col("age").gt(30))
.join(department, people.col("deptId").equalTo(department.col("id")))
.groupBy(department.col("name"), people.col("gender"))
.agg(avg(people.col("salary")), max(people.col("age")));
cs