前言
本文隶属于专栏《1000个问题搞定大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见1000个问题搞定大数据技术体系
正文
根据以下两种条件将集群部署模式分为三种类型:
- 集群的生命周期和资源隔离;
- 根据程序main()方法执行在 Client 还是 JobManager
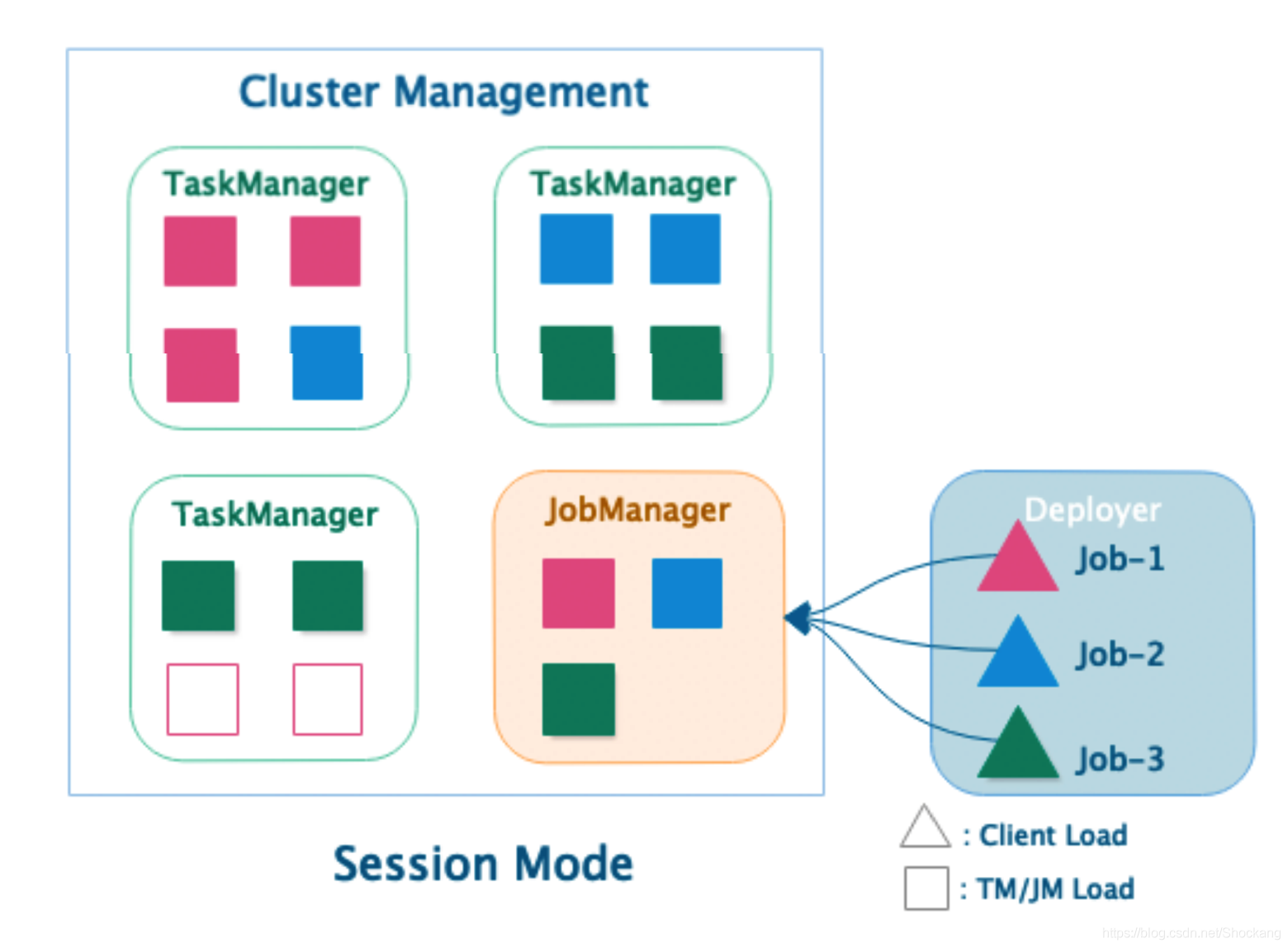
Session 集群运行模式(Session Mode)
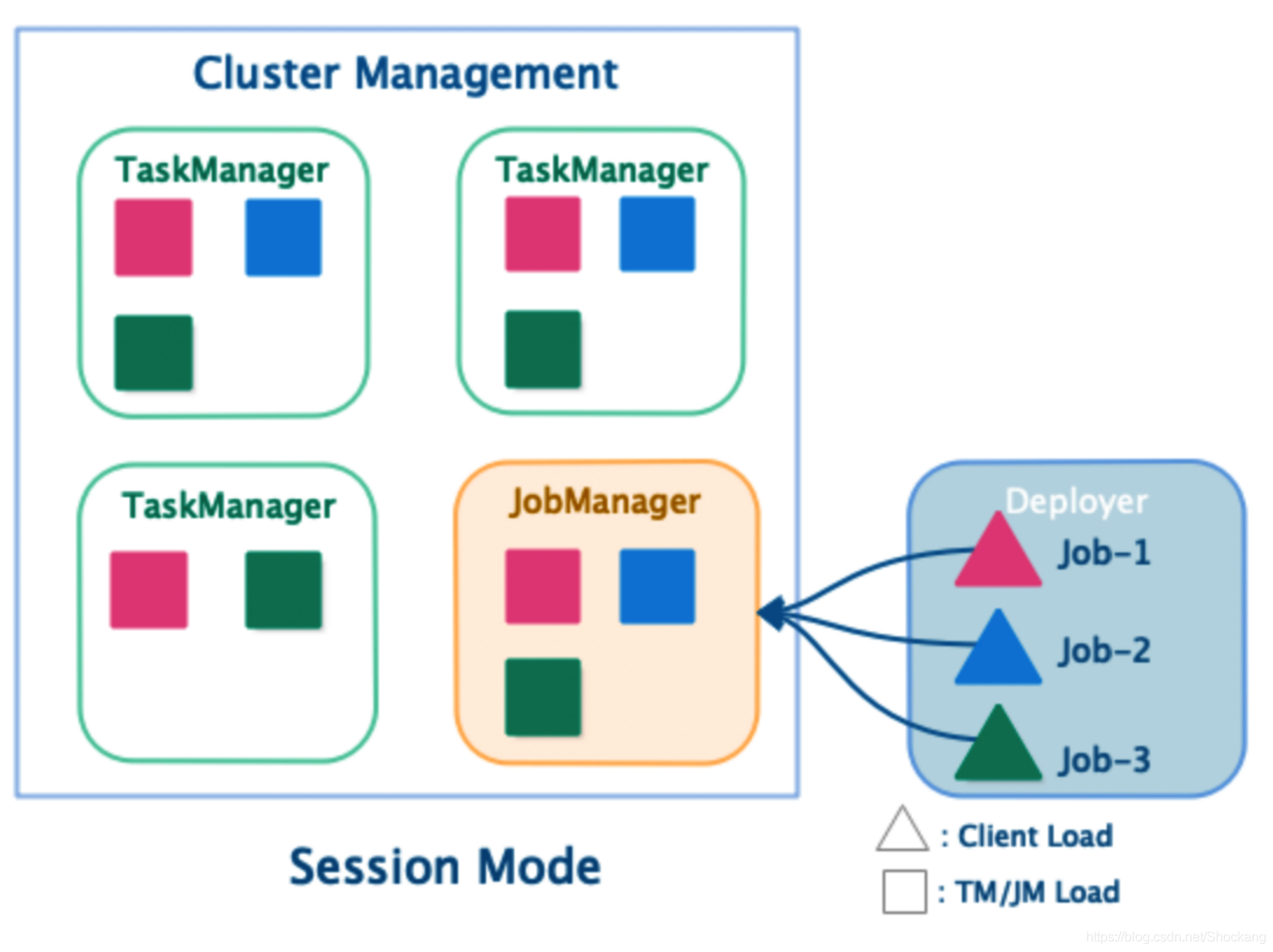
- JobManager 与 TaskManager 共享
- 客户端通过 RPC 或 Rest API 连接集群的管理节点
- Deployer 需要上传依赖的 Dependencies Jar
- Deployer 需要生成 JobGraph ,并提交到管理节点
- JobManager 的生命周期不受提交的 Job 影响,会长期运行
优点
- 资源充分共享,提升资源利用率
- Job 在 Flink Session 集群中管理,运维简单
缺点
- 资源隔离相对较差
- 非 Native 类型部署, TM 不易拓展, Slot 计算资源伸缩性较差。
Per-Job 运行模式(Per-job Mode)
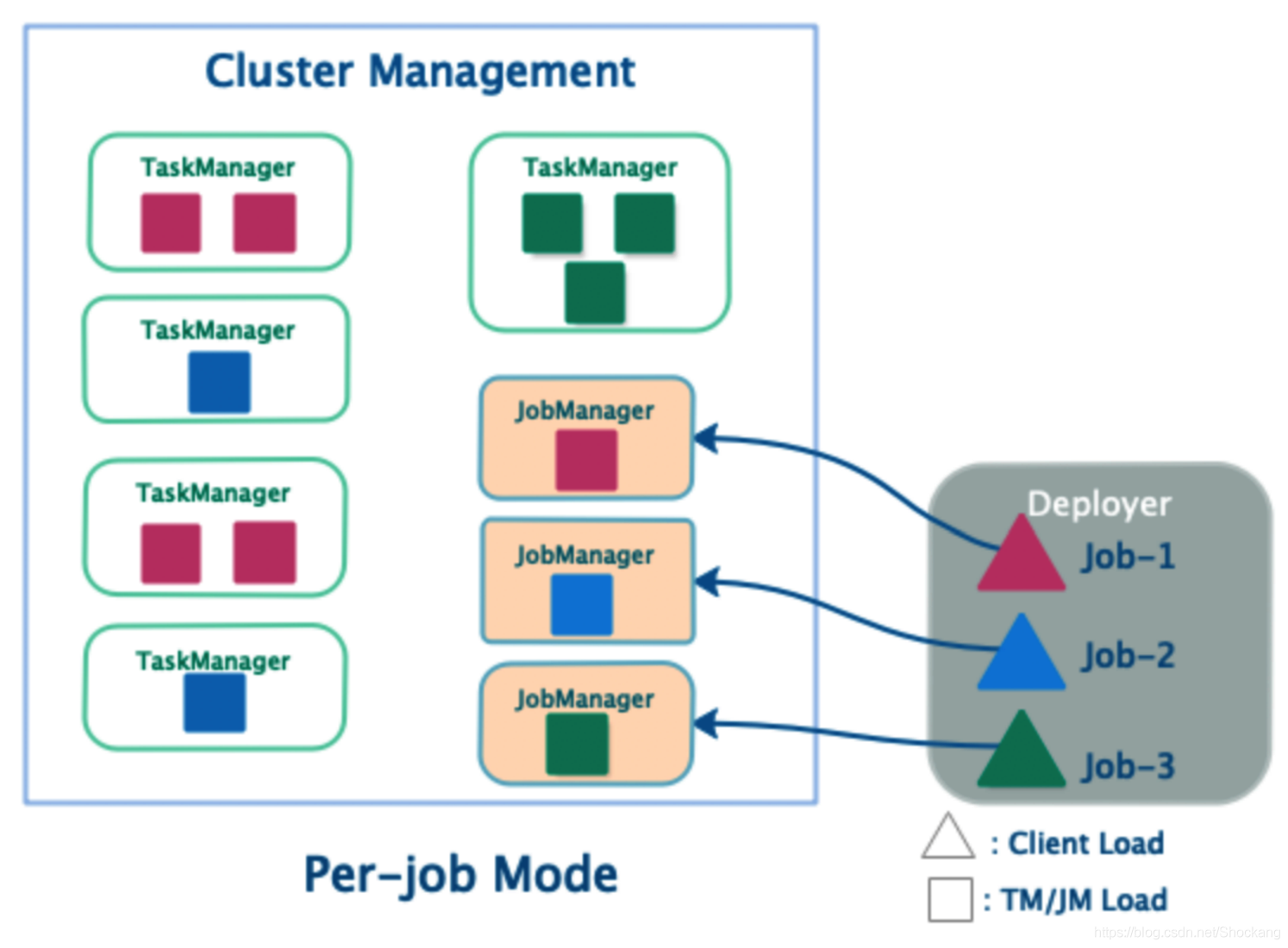
- 单个 Job 独享 JobManager 与 TaskManager
- TM 中 Slot 资源根据 Job 指定
- Deployer 需要上传依赖的 Dependencies Jar
- 客户端生成 JobGraph ,并提交到管理节点
- JobManager 的生命周期和 Job 生命周期绑定
优点
- Job 和 Job 之间资源隔离
- 充分源根据 Job 需要进行申请, TM Slots 数量可以不同
缺点
- 资源相对比较浪费, JobManager 需要消耗资源
- Job 管理完全交给 ClusterManagement ,管理复杂。
Application Mode 类型集群( 1.11 版本)
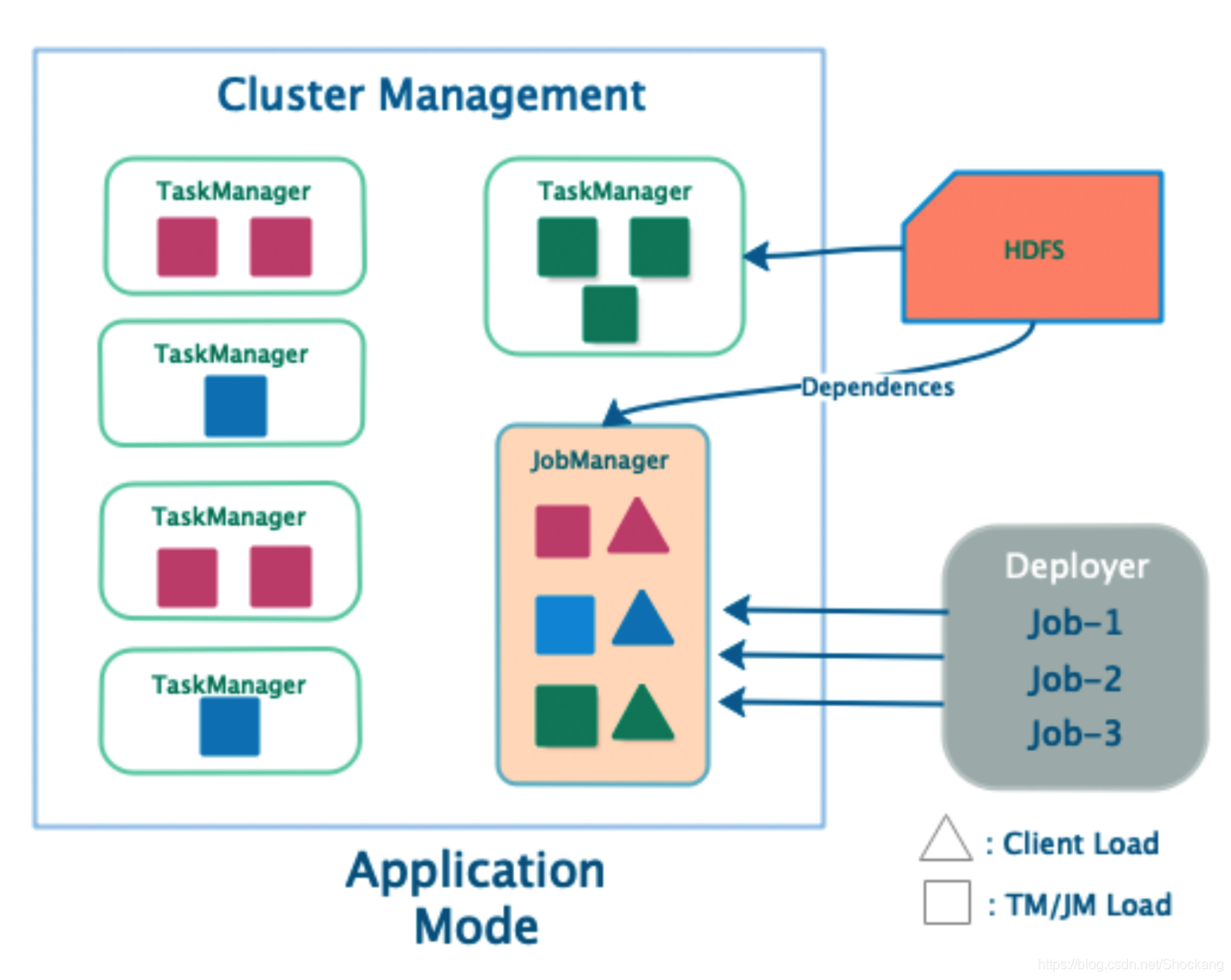
- 每个 Application 对应一个 JobManager ,且可以运行多个 Job
- 客户端无需将 Dependencies 上传到 JobManager ,仅负责管理 Job 的提交与管理
- main()方法运行 JobManager 中,将 JobGraph 的生成放在集群上运行,客户端压力降低
优点
- 有效降低带宽消耗和客户端负载
- Application 实现资源隔离, Application 中实现资源共享
缺点
- 功能太新,还未经过生产验证
- 仅支持 Yarn 和 Kubernetes
Flink 集群部署对比

什么是 Native 集群部署模式?
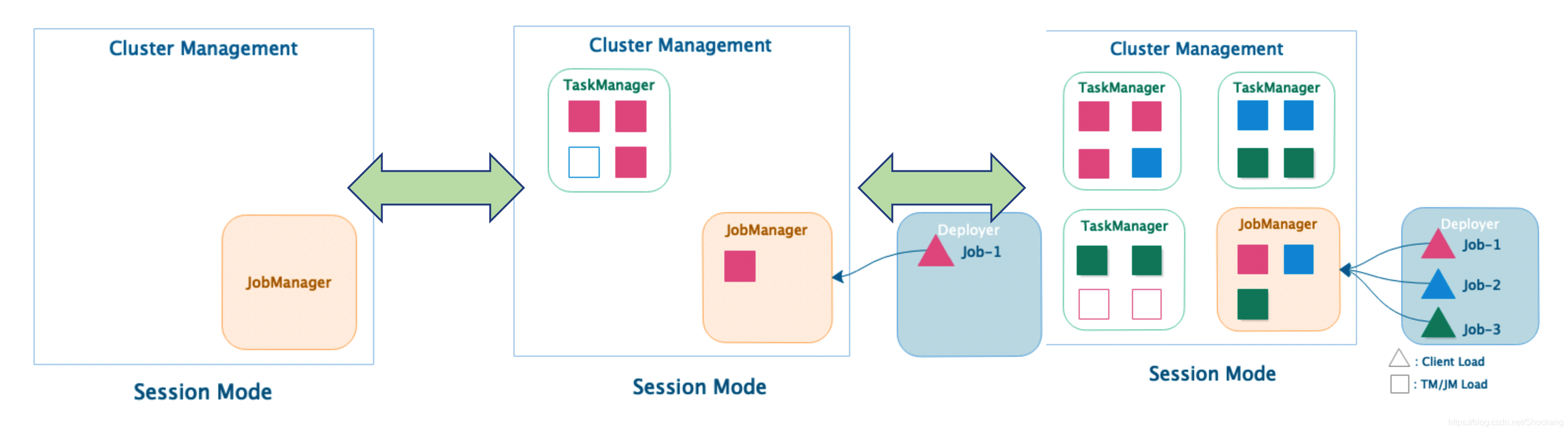
当在 ClusterManagerment 上启动 Session 集群时,只启动 JobManager 实例,不启动 TaskManager
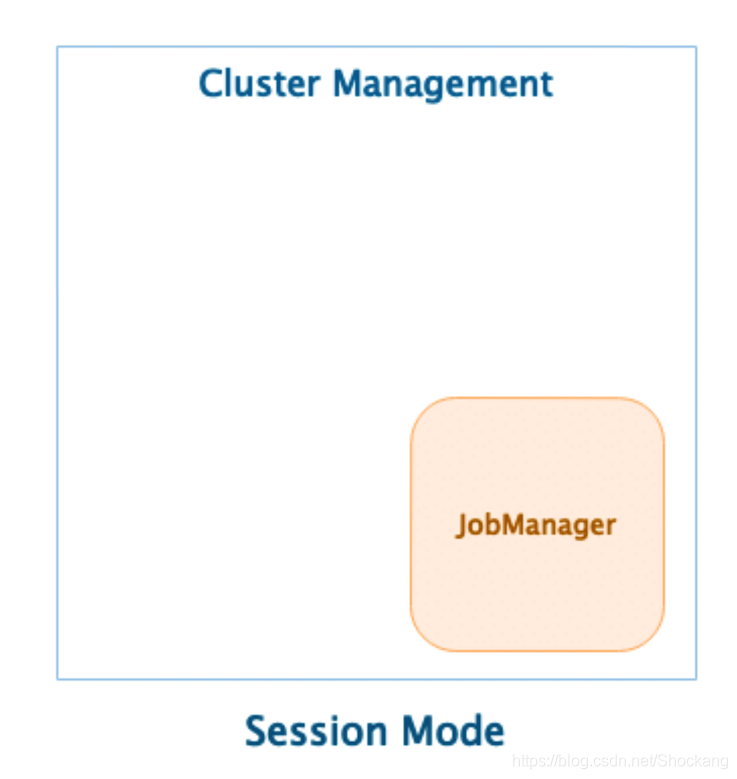
提交 Job-1 后根据 Job 的资源申请,动态启动 TaskManager 满足计算需求。

提交Job-2,Job-3后,再次向 ClusterManagement 中申请TM资源。
Session集群根据根据实际提交的job资源动态申请和启动 TaskManager计算资源。
支持 Native部署模式的有Yarn, Kubernetes, Mesos资源管理器。
Stand alone不支持 Native部署。
cs