目录
前言
一、CEEMDAN 算法
1 算法原理
2 MATLAB程序
二、CEEMDAN 算法的应用?
1?CEEMDAN―小波阈值联合去噪
2?CEEMDAN―小波包分析降噪
3?CEEMDAN―时频峰值滤波
结束语
参考文献
前言
针对EMD算法分解信号存在模态混叠的问题,EEMD和CEEMD分解算法通过在待分解信号中加入成对正负高斯白噪声来减轻EMD分解的模态混叠。但是这两种算法分解信号得到的本征模态分量中总会残留一定的白噪声,影响后续信号的分析和处理。
为了解决这些问题,TORRES 等提出了一种改进算法――完全自适应噪声集合经验模态分解(Complete EEMD with Adaptive Noise,CEEMDAN),又称完全集合经验模态分解。
CEEMDAN 分解从两个方面解决了上述问题:1)加入经 EMD 分解后含辅助噪声的 IMF 分量,而不是将高斯白噪声信号直接添加在原始信号中;2)?EEMD 分解和 CEEMD 分解是将经验模态分解后得到的模态分量进行总体平均,CEEMDAN 分解则在得到的第一阶 IMF分量后就进行总体平均计算,得到最终的第一阶 IMF分量,然后对残余部分重复进行如上操作,这样便有效地解决了白噪声从高频到低频的转移传递问题。
一、CEEMDAN 算法
1 算法原理
设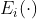 为经过 EMD 分解后得到的第?
为经过 EMD 分解后得到的第?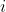 个本征模态分量,CEEMDAN 分解得到的第 ?个本征模态分量为
个本征模态分量,CEEMDAN 分解得到的第 ?个本征模态分量为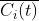 ,
,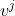 为满足标准正态分布的高斯白噪声信号,
为满足标准正态分布的高斯白噪声信号,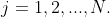 为加入白噪声的次数,
为加入白噪声的次数, 为白噪声的标准表,
为白噪声的标准表,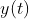 为待分解信号。CEEMDAN 分解步骤如下:
为待分解信号。CEEMDAN 分解步骤如下:
1)将正负成对高斯白噪声加入到待分解信号得到新信号 ,其中q=1,2. 对新信号进行EMD分解,得到第一阶本征模态分量
,其中q=1,2. 对新信号进行EMD分解,得到第一阶本征模态分量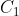 。
。
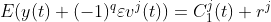
2)对产生的 N 个模态分量进行总体平均就得到CEEMDAN 分解的第 1个本征模态分量:
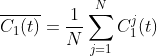
3)计算去除第一个模态分量后的残差:
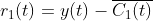
4)在  中加入正负成对高斯白噪声得到新信号,以新信号为载体进行 EMD 分解,得到第一阶模态分量
中加入正负成对高斯白噪声得到新信号,以新信号为载体进行 EMD 分解,得到第一阶模态分量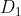 ,由此可以得到 CEEMDAN 分解的第 2个本征模态分量:
,由此可以得到 CEEMDAN 分解的第 2个本征模态分量:
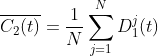
5)计算去除第二个模态分量后的残差:
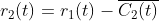
6)重复上述步骤,直到获得的残差信号为单调函数,不能继续分解,算法结束。此时得到的本征模态分量数量为 K,则原始信号被分解为:

2 MATLAB程序
clc;
clear;
close all;
fs=4000; % 采样频率为4000Hz
t=(0:1/fs:(2-1/fs))';
N=length(t);
x1=0.25*cos(0.875*pi*50*t);
x2=0.3*sin(2*pi*50*t).*(1+1.5*sin(0.5*pi*40*t));
x3=0.15*exp(-15*t).*sin(200*pi*t);
x=x1+x2+x3;
nt=0.2*randn(N,1);
y=x+nt;
%% CEEMDAN分解
Nstd = 0.2; % 正负高斯白噪声标准表
NR = 100; % 加入噪声的次数
MaxIter = 500; % 最大迭代次数
[imf, its]=ceemdan(y,Nstd,NR,MaxIter);
[m, n]=size(imf);
CC=zeros(1,m); % 相关系数
figure;
for i=1:m
subplot(m/2,2,i);plot(imf(i,:));ylabel(['IMF',num2str(i)]);
CC(i)=corr(imf(i,:)',y,'type','Pearson'); % 相关系数
end
 CEEMDAN分解的各个IMF分量
CEEMDAN分解的各个IMF分量
cs