������Դ:���������
ǰ��
֪ʶͼ��,��һ���������������,������ʵ������ϵ��������Щ������λ,�Է��ŵ���ʽ���������������в�ͬ�ĸ������֮������ϵ��Ϊʲô˵֪ʶͼ������Ϣ�������Ƽ�ϵͳ���ʴ�ϵͳ��������Ҫ,������һ��������˵��:������һ����������,������������������
�����ӿ���ϴ����?
���Կ������Query��һ���������ʾ�,����ڼ���ϵͳ����һ���ϴ���ʴ����Ͽ�(����FAQ����),����һ���㹻�Ӵ���������ݿ�(���µ�title�����ʸ�),ʹ������ƥ��������Query��FAQ�ʾ䡢����title�����ƶȼ�������Ǹ���Ϊ����ķ���(�ɲο���һ������[����])������,��ʵ���DZȽϹǸ�,��Ҫ�����������������Ա����Ϻ��걸�Ƿdz����ѵġ���ô�������case,������baseline����ô������?�ڴ�ͳ����������,�������Ȼ��Query�����ִ�,��ԭ��ͱ����
��,����,����,ϴ��,��,?
�������ݿ�������µ�����,��������������������������,�ٸ���BM25�㷨�Էִʽ���еĴ������µ��ٻء�����Ȼ,���ǿ��Ը���ҵ������Ҫ����ҵ��ʵ�,��һЩҵ��ؼ���,���������е���������һ���������;������������ʱ������һЩͣ�ô�,��������,���ȡ���֮���ݴ��Եȵ���һ��Ȩ��(���缲�������������ʵ�),���ڴ��������������������������������ǵ�ĿǰΪֹ,���ǿ��Կ������������Ķ��Ǹ����ؼ�������,Ҳ����˵���µ������б������������ ��ϴ����Щ�ʡ�ͬʱ,��Ϊȥ����ͣ�ôʡ�����,Ҳ�ᵼ��Query�����嶪ʧ,��������ϴ����Ϊ�˸��ѵ����������ô,��Ϊһ����Ȼ����,�����������������Query��:
������ �C> �����ڸ�Ů
ϴ�� �C> �ճ�����
���仰������������"�����ڸ�Ů�Ƿ������ϴ��֮����ճ�����",��������Ҳ���Ժ���Ȼ������,�������Query�ȽϺ��ʵķ���������"�����ڵ��ճ�����"���������¡����Է���,������˼����Ȼ���Եı�ʾʱ,�����ڼ���������Ϊ֧��,���Ҿ��������ĸ������¼�����,��Щ�����������������ϰ�õ�֪ʶ��ϵ,���ǿ��������е�֪ʶ�Ͻ�������������������,���Ǽ���������߱��ġ���ͳ����Corpus��NLP����,ϣ���Ӵ����ı������з���ӳ���������ʵ����,���ַ�������ʵ������,��һЩС�����п��Ի�ò�����Ч��,���ǻᱩ¶����ǰ������ĸ�������,ӳ�����֪ʶ��ʾ�����ܳ�������,����Ǩ��;ȱ����֪ʶ��ϵ����֯;Ч�����ɽ��͵�;Ϊ�˽����������,������Ϊ֪ʶͼ��������ͻΧ�Ĺؼ�������ڳ��ı�,֪ʶ��(ʵ�塢��ϵ)��������֯�����䡢���¡���Ȼ���Ա���������֪����ij���,��Ҫ�����������Ȼ����,Ҳ��Ҫװһ������֪ʶ�Ĵ��ԡ�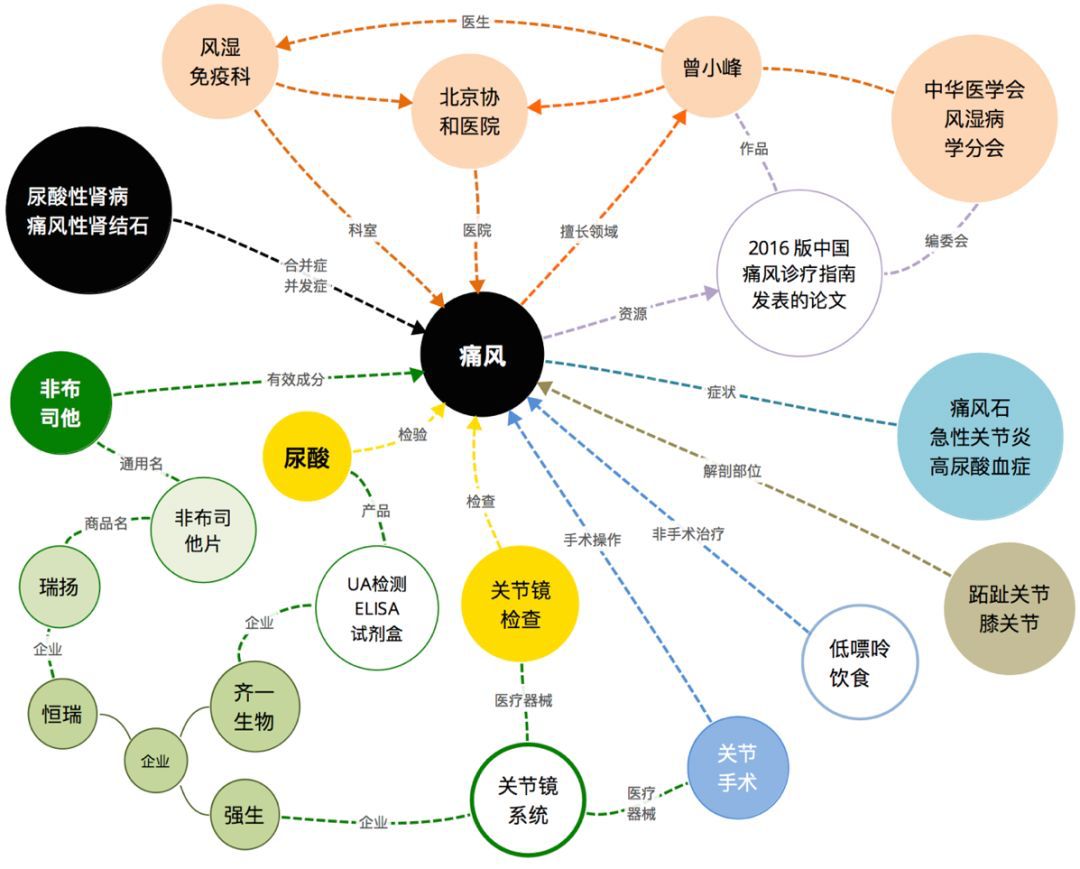 ����Ҳ�ڳ��Թ����Լ���ҽѧ����֪ʶͼ��,����Ҳ��½������֪ʶͼ����ص�֪ʶ��ȡ��֪ʶ��ʾ��֪ʶ�ںϡ�֪ʶ�����ȷ���ļ������бʼ�,�Լ��������Ƽ��ȳ��������ʵ����������ҪΪ������֪ʶͼ�����ļ������бʼǷ�����
����Ҳ�ڳ��Թ����Լ���ҽѧ����֪ʶͼ��,����Ҳ��½������֪ʶͼ����ص�֪ʶ��ȡ��֪ʶ��ʾ��֪ʶ�ںϡ�֪ʶ�����ȷ���ļ������бʼ�,�Լ��������Ƽ��ȳ��������ʵ����������ҪΪ������֪ʶͼ�����ļ������бʼǷ�����
����
�����Ѿ��ڸ�֪ʶͼ������֪��,֪ʶͼ�ױ�������һ����������,�ڵ����ʵ��(entity)��������(concept),�ߴ���ʵ��(�����)֮��ĸ��������ϵ����֪ʶͼ����֪ʶ��ϵ�IJ������������־������֯����,����Ontology��Taxonomy��Folksonomy��������������Լ�����Ϊ֪ʶͼ���㼶��ϵ�����ֲ�ͬ�ϸ�̶ȵ����֡�OntologyΪ��״�ṹ,�Բ�ͬ��ڵ�֮��������ϸ��IsA��ϵ(����ȷ�,Human activities -> sports -> football),����ͼ���ŵ��DZ���֪ʶ����,��������ʾ�����ϵ�Ķ�����;TaxonomyҲ����״�ṹ,���Dz㼶�ϸ�̶ȵ�һЩ,�ڵ������Hypernym-Hyponym��ϵ����,�����ĺô��ĸ����ϵ�ȽϷḻ,����Ҳ��������������,������Ч������;Folksonomy���ǷDz㼶�Ľṹ,ȫ���ڵ��Ա�ǩ����,�����������,����ľ�ȷ�ԡ���������Ҳȫ��ɥʧ�ˡ�Ŀǰ,Taxonomy����֯�ṹ�ǻ�������ҵ�ڽ�Ϊ���е�����,��Ϊ����һ���̶��ϼ�����²��ϵ�ͱ�ǩ��ϵ,�ڸ���Ӧ���ϵ���������,������Ҫ��עTaxonomy�Ĺ���������
����
�������ģ֪ʶ�������Դ����������һЩ�����İ�ṹ�����ǽṹ���͵������ṹ�����ݿ⡣�ӽṹ�����ݿ��л�ȡ������Ϊ��,��Ҫ���Ĵ��Ϊͳһ�������ʵ�����������;����ǴӰ�ṹ�������л�ȡ֪ʶ,�����ά���ٿ���: �ٿ��еĴ���������һ�ݺܺõ�������Դ,���ṩ��ʵ��ʷḻ��context,����ÿ��������������ϸ��Ŀ¼�Ͷ�������:
�ٿ��еĴ���������һ�ݺܺõ�������Դ,���ṩ��ʵ��ʷḻ��context,����ÿ��������������ϸ��Ŀ¼�Ͷ�������: ���ǴӲ�ͬ�Ķ�����Գ�ȡ��Ӧ�ṹ���ֶε���Ϣ,��Ȼ,��Щ�ʿ��ܲ������ĵ���,�����Ҫ����һЩNLP�㷨����ʶ��ͳ�ȡ,��������ʵ��ʶ������ϵ��ȡ�����Գ�ȡ��ָ�������ȵȡ���ؼ����Լ�ģ���Ż����ǻ��ں���������ϸչ��,���ﲻ��������ô,ǰ���ᵽTaxonomy���͵�֪ʶͼ����һ��IsA����״�ṹ,�ӽṹ�����ṹ��������Դ��,�������͵Ĺ�ϵ���Ժ������,�������¼��IJ㼶��ϵ���ݾ���Խ��١���Ҫ������һ��������,��������ԭ֪ʶͼ����û�еĹ�ϵ����,����Ҫ�ӷǽṹ���ı����߰�ṹ������Դ���ı������г�ȡ��
���ǴӲ�ͬ�Ķ�����Գ�ȡ��Ӧ�ṹ���ֶε���Ϣ,��Ȼ,��Щ�ʿ��ܲ������ĵ���,�����Ҫ����һЩNLP�㷨����ʶ��ͳ�ȡ,��������ʵ��ʶ������ϵ��ȡ�����Գ�ȡ��ָ�������ȵȡ���ؼ����Լ�ģ���Ż����ǻ��ں���������ϸչ��,���ﲻ��������ô,ǰ���ᵽTaxonomy���͵�֪ʶͼ����һ��IsA����״�ṹ,�ӽṹ�����ṹ��������Դ��,�������͵Ĺ�ϵ���Ժ������,�������¼��IJ㼶��ϵ���ݾ���Խ��١���Ҫ������һ��������,��������ԭ֪ʶͼ����û�еĹ�ϵ����,����Ҫ�ӷǽṹ���ı����߰�ṹ������Դ���ı������г�ȡ��
��������������п���ȡ��ʹ�� Is A ���ʴ�л����֢ ��,�������� Is A ϸ������ʡ�,����ԭ���� Is A ϸ������ʡ�,������������ Is A ϸ������ʡ��ȡ�����֪ʶͼ�����������,�ⷽ����о�Ҳ�ڽ�����������,Ҳ����������������Ĺ�������,�������Ƕ�Taxonomy�Ĺ����������˷�������,��չ������һ����Ӣ�������ļ������巽����
Taxonomy��������
��Ȼǰ�泩���˹���һ�����Ƶ�Taxonomy�Ժ���NLPӦ�õ����ô�,���ǻ���Ҫ�侲��֪��Ŀǰ���������о�����������,��Ҫ����������һ������ԭ��:��һ,�ı����ݴ���ƪ��������������ϵľ����,��ƺõij�ȡģ��(����ijЩ�������ʽ)���Լ����ڲ�ͬ��������Գ�����;���,�������Ա���Ķ�����,��ȡ���ݵ�������Ҳ����������,��Ҳ����Ӱ�������յ�ȷ��;����,ͬ��������IJ���,��ȡ����֪ʶ�����Ҳ�Ǹ�ͷ�۵����⡣�������ǻ����һЩ���е�ѧ���硢��ҵ����о��ɹ�,��Щ�����Ӳ�ͬ�Ƕ������㷨������ȷ��,ͬʱҲ����Taxonomy���������µļ���������,������λ�ʻ�ȡ(hyponym acquisition)����λ��Ԥ��(hypernym prediction)���ṹ����(taxonomy induction)����Ŀǰ����free text-based�ĸ�taxonomy����������,�������ܽ������������Ҫ����:i) ����ģ�巽ʽ(Pattern-based) �� �ֲ�ʽ��ʽ(Distributional) ���ı��г�ȡ?Is-A?�Ĺ�ϵ��;ii) ����ȡ�õ��Ĺ�ϵ������ induct ��������taxonomy�ṹ��
Pattern-based ����
ģ�巽��,����˼��������һЩ�̶�ģ��ȥԭ���н���ƥ��,��ֱ�۵ľ���д�������ʽȥץȡ����������������?Hearst?����˼�����ģ����� ��[C] such as [E]��,��[C] and [E]�� ,�Ӷ����Դӷ�����Щ����ʽ�ľ����еõ�����λ��ϵ�ʶԡ���Щģ�忴�Ƽ�,����Ҳ�в��ٻ������ǵijɹ�Ӧ��,����������������Probase���ݼ���Ҳ����Ϊ��,ģ�巽ʽ��Ȼ�������,������������ٻ��ʵ�,ԭ��Ҳ�ܼ�,��Ȼ���Ծ��и��ַḻ�ı��﷽ʽ,��ģ������������,���Ը������еľ�ʽ�ṹ�����,���Ե������Ҳ��Ӱ���ȡ��ȷ��,�����Ĵ������δ֪�������������ȡ��ȫ�������ȡ�ѧ�����в����о��ɹ��ڻ���ģ�巽ʽ��,��������ٻ��ʺ�ȷ�ʡ�
a). ��������ٻ�?
��������������ٻ���,��һ����Ƕ�ģ����и�����չ(Pattern Generalization),�������ͬ����ʵ��������Ӧ��ģ��;ģ���ڲ��ڴʡ�����������滻; Ҳ��һЩ�Զ�����ģ��Ĺ���,����Rion Snow��ġ�Learning syntactic patterns for automatic hypernym discovery���ɹ���,���þ䷨����path�Զ���ȡ�µ�ģ��
Ҳ��һЩ�Զ�����ģ��Ĺ���,����Rion Snow��ġ�Learning syntactic patterns for automatic hypernym discovery���ɹ���,���þ䷨����path�Զ���ȡ�µ�ģ�� ����,�����Զ�ģ�����ɷ���Ҳ������µ�����,������ǵ�ԭʼ���Ϸdz��Ӵ�Ļ�,����ģ��������Ƿdz�ϡ���(Feature sparsity problem),��һ��˼·����ȥ��עPattern������,�������ǵ�generality,�Ӷ�����ٻ��ʡ���ع�������Navigli�������_star pattern_�ĸ���:�滻�����еĵ�Ƶʵ���,��ͨ�������㷨������general��pattern��
����,�����Զ�ģ�����ɷ���Ҳ������µ�����,������ǵ�ԭʼ���Ϸdz��Ӵ�Ļ�,����ģ��������Ƿdz�ϡ���(Feature sparsity problem),��һ��˼·����ȥ��עPattern������,�������ǵ�generality,�Ӷ�����ٻ��ʡ���ع�������Navigli�������_star pattern_�ĸ���:�滻�����еĵ�Ƶʵ���,��ͨ�������㷨������general��pattern�� �䷨������Ϊ��������һ·��Ҳ�����Ƶ�˼·,��PATTYϵͳ��,����dependency path������滻pos tag,ontological type �� ʵ���,��������ѡpattern���ڶ������������ȡ,��Ҫ������˵ijЩ����Ĺ�ϵ������Ϊ���Ե������������Ư������(semantic drift)�ᱻһЩ����general��parttern�Ķ�γ�ȡ����ô������һ����֤����,�����Ϳ���������������������ڡ�Semantic Class Learning from the Web with Hyponym Pattern Linkage Graphs������ˡ�doubly-anchored����ģʽ,��һ��bootstrapping loop���г�ȡ�������������λ���ƶ�(Hypernym Inference),����ģ���ȡ��ϵ���ݵ���һ��Ӱ���ٻ��ʵ�������,ģ�����õ�Ŀ���������ľ���,Ҳ����Ϊ��ij����ϵ����λ�ʺ���λ�ʱ���ͬʱ�����ھ����С�һ������Ȼ���뷨�����Ƿ�������ôʵĴ�����,����˵y��x����λ��,��ͬʱx��x'�dz�����,����������λ��ϵ�Ϳ�����Ϊ����,���й����о���trainһ��HMM��������ӵ�Ԥ�⡣��������֮��,Ҳ��һЩ�о��Ǹ�����λ�ʵ����δ����䷨�ϵ��ƶ�,����˵��grizzly bear�� Ҳ��һ�� ��bear��
�䷨������Ϊ��������һ·��Ҳ�����Ƶ�˼·,��PATTYϵͳ��,����dependency path������滻pos tag,ontological type �� ʵ���,��������ѡpattern���ڶ������������ȡ,��Ҫ������˵ijЩ����Ĺ�ϵ������Ϊ���Ե������������Ư������(semantic drift)�ᱻһЩ����general��parttern�Ķ�γ�ȡ����ô������һ����֤����,�����Ϳ���������������������ڡ�Semantic Class Learning from the Web with Hyponym Pattern Linkage Graphs������ˡ�doubly-anchored����ģʽ,��һ��bootstrapping loop���г�ȡ�������������λ���ƶ�(Hypernym Inference),����ģ���ȡ��ϵ���ݵ���һ��Ӱ���ٻ��ʵ�������,ģ�����õ�Ŀ���������ľ���,Ҳ����Ϊ��ij����ϵ����λ�ʺ���λ�ʱ���ͬʱ�����ھ����С�һ������Ȼ���뷨�����Ƿ�������ôʵĴ�����,����˵y��x����λ��,��ͬʱx��x'�dz�����,����������λ��ϵ�Ϳ�����Ϊ����,���й����о���trainһ��HMM��������ӵ�Ԥ�⡣��������֮��,Ҳ��һЩ�о��Ǹ�����λ�ʵ����δ����䷨�ϵ��ƶ�,����˵��grizzly bear�� Ҳ��һ�� ��bear��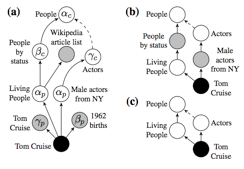 ��ͼ�ǡ�Revisiting Taxonomy Induction over Wikipedia���Ĺ���,ͨ�������е�ͷ������Ϊ����,����һ������ʽ��ȡ�����̡�
��ͼ�ǡ�Revisiting Taxonomy Induction over Wikipedia���Ĺ���,ͨ�������е�ͷ������Ϊ����,����һ������ʽ��ȡ�����̡�
b). �������ȷ��?
����ͼ������������,���������ȷ�ȵ���?�������һЩ����ͳ�Ƶķ�ʽ������ (x, y)?��һ�Ժ�ѡ�� is-a ��ϵ��,��KnowItAllϵͳ��,������������������ x �� y �ĵ㻥��Ϣ(PMI);��Probase��ʹ�õ�����Ȼ��������ʾ y �� x ����λ�ĸ���,ȡ����������Ϊ���;����Ҳ��ͨ����Ҷ˹��������Ԥ�������ⲿ������֤��ר��������֤�ȷ�������������ڳ�ȡ������������ȷ��,�����о���������ѡȡһ����ָ֤��,Ȼ��һ��������ȥ�����Ż�������,��������ģ���ȷ�ʻ����ձ�ƫ��,����������Ĺ�����������ģ��+�ֲ�ʽ�Ļ�Ϸ����б��ᵽ,����������һ�·ֲ�ʽ�ij�ȡ˼·��
Distributional ����
��NLP������,�ֲ�ʽ�������ǰ�������������������һЩ��ʾѧϰ�Ľ�����ֲ�ʽ��ʾ��һ���ŵ��ǽ�NLP������ԭ����ɢ������ת��Ϊ�����ġ��ɼ���ġ����ideaҲ�������뵽ͼ������,��Ϊ�ɼ������ζ�Ŵ��������̺���ijЩ��ϵ,��Щ��ϵҲ������ Is-A ���ݶԵ�����λ��ϵ���ֲ�ʽ������ȡ����һ���ŵ������ǿ��Զ� Is-A ��ϵ����ֱ��Ԥ��,������ͨ����ȡ�����������Ҫ��������ܽ�Ϊ:i) ��ȡ�������ݼ�(Key term); ii) ʹ���ල���мලģ�ͻ�ȡ����ĺ�ѡ Is-A ��ϵ�ԡ�
a). Key Terms ��ȡ
�������ݼ���ȡ�ķ����кܶ�,��ֱ�۾�������ϸ��pattern,�������ĺô��ǿ��Ա�֤Key term�нϸߵ�ȷ��,�ڴ������ϵ������Ч������,���ǵ��������ݽ��ٵ�ʱ��,���ܴ��ڳ�ȡ��������,���º���ģ��training����ϵ����������ʹ�� pattern ��ȡ,Ҳ���о�ʹ�����б�עģ������NER��������Ԥ��ȡ,����ʹ�����ɹ�����й��ˡ����ֻ��ڴ�ֱ����Toxonomy�������о���,�ḽ��ijЩ�����ض��ĺ���(domain filtering)�������Ǹ���һЩͳ��ֵ��һЩ��ֵ,����TF��TF-IDF������������صķ�ֵ��Ҳ���о�������ѡ���ӵ�ʱ������Ӵ���Ȩ��,������Ȩ�ظߵľ����г�ȡkey term����ȡkey term��,�������Ǻ��������Щ��������������µĹ�ϵ�ԡ�
b).Unsupervised ģ��
��һ������Ǿ���ķ���,���ھ���,�о��ĺ��ľ��Dz������־�������ָ��,��ָ�����?cosine��Jaccard��Jensen-Shannon divergence������Ϊ����,Ҳ��������һЩ����ʵ��� (x, y) ȡ����������Ȩ�����Ƚ�,����?LIN measure:?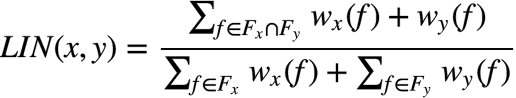 ���� Fx ,Fy ��ʾ��ȡ�� feature,w ��ʾfeature��Ȩ�ء�
���� Fx ,Fy ��ʾ��ȡ�� feature,w ��ʾfeature��Ȩ�ء�
����,���о���Ա��ע��,������ά���ٿƵĴ���ҳ����,��λ��ֻ�������������λ�ʵ�ijЩcontext�С�������λ�ʿ��ܻ��������λ�ʵ�����context��,���������IJ��Գ���,����������Ҳ������Ӧ����,����ʹ��WeedPrec:
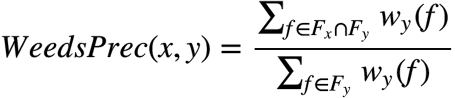 ������豻��Ϊ?Distributional Inclusion Hypothesis(DIH),���Ƶľ������ۻ���WeedRec��BalAPInc��ClarkeDE��cosWeeds��invCL�ȡ�
������豻��Ϊ?Distributional Inclusion Hypothesis(DIH),���Ƶľ������ۻ���WeedRec��BalAPInc��ClarkeDE��cosWeeds��invCL�ȡ�
���˾�������ָ��,��һ����Ҫ��ע�ľ���feature��ôȡ,��������??���ı������еĹ���Ƶ�����㻥��Ϣ��LMI�ȡ�
c). Supervised ģ��
��ӵ�� key term �;��������,��һ���������ȵķ����ǹ����мල��ģ��,����ʹ��Classification��Ranking�ķ�ʽ���ӷ������ĽǶ�,�����еķ�����������ǰѵ����һ������ģ��,����Word2Vec,��ѡ���ݶ� (x, y) ����Ӧӳ��Ϊ����,������������ƴ��,Ȼ��ʹ�ñ���SVM����һ��������ķ�����������취�ں��������о��ж���Ϊbaseline���Ƚϡ������������Ч,�����ڽ�����о���Ҳָ����Ҳ����һЩ�е����⡣ʵ������,���ַ�����ѧ�����������ϵ���ϵ,�����������ڴ�������λ��ϵ����ϵ,���仰˵���Ƿdz�������ϡ�����������Ƕ� (����x)?�� (����y) �� diff ����,���߽����ӡ���˵ȷ�ʽȡ�ۺϵ�feature�������о�����Ϊ,��������training�����ϻ���Ӱ��ܴ�,������λ��ϵҲһͬӳ�䵽�ʵ�embedding�бȽ����ѡ������ڴ������Ļ�����,Ϊx��y��������һ�� embedding ����ʾ��ϵ,ʵ�����������ַ�ʽ���ض������ͼ�����в�����ָ��������
���˷�����,��λ�����ɷ���(Hypernym Generation)Ҳ��һ��ѡ��,ͬʱ��Ҳ��ĿǰЧ����õ�һ�ַ���,�����ǹ���һ��piecewise linear projection model����ѡȡ�� (����x)����λ����ӽ��� (����y) ,�˴�Ҳʹ����Ranking�ļ��ɡ�����ѡȡ�������������ع������˳���,����չ�����Լ������������½ڡ�
Taxonomy Induction
��ǰ���½�,�����˸��ּ������ı��г�ȡ Is-A ��ϵ��,���һ���Ĺ���������ΰ���Щ��ϵ���������ϲ�,����������ͼ�ס�����������һ������ѧϰIncremental Learning��ģʽ,��ʼ��һ��seed taxonomy,Ȼ���µ� Is-A ������ͼ�ϲ��䡣�����������о�������ʹ�ú�������ָ����Ϊ���������ݵ����ݡ������ķ����ǰѹ�������һ����������,���Ƶ�����ͨ��������кϲ����硶Unsupervised Learning of an IS-A Taxonomy from a Limited Domain-Specific Corpus����ʹ��K-Medoids����ȥѰ����С�������ȽΡ�ͼ��ص��㷨Ҳ������Ϊһ������,��ΪTaxonomy��Ȼ���Ǹ�ͼ�Ľṹ,�����ڡ�A Semi-Supervised Method to Learn and Construct Taxonomies using the Web���ṩ��һ��˼·,�ҵ��������Ϊ0�Ľڵ�,���Ǵ������taxonomy�Ķ���,�ҵ����г���Ϊ0�Ľڵ�,���Ǵ�����ǵײ���instance,Ȼ����ͼ��Ѱ�Ҵ�root��instance���·��,�Ϳ��Եõ�һ����Ϊ�����Ľṹ��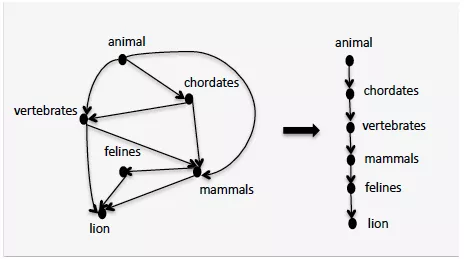
����Ҳ����ͼ��edge�ϸ��ϸ���������ص�Ȩ��ֵ,Ȼ���ö�̬�滮һ����㷨�����ŷָ�,����Optimal branching algorithm�����������һ������taxonomy����ϴ,�Ѵ���� Is-A ��ϵ������ȥ������һ���ؼ�������taxonomy�е����¼���ϵ�Dz����ڻ�״�ṹ��,Probase���ݿ��ڹ���ʱͨ��ȥ����״�ṹ,������Լ74K�Ĵ��� Is-A ��ϵ�ԡ���һ���Ƚϴ��������ʵ��ʵ�����,��������Ŀǰ����û���ر���Ч�Ľ����������������һЩ�Զ���ͼ������ϵͳ��,���������ᵽ�ġ������ԡ�����������������������������ݵķ��ա��ٸ�����,������ Is-A ��ϵ��:
(Albert Einstein, is-a, professor)
(professor, is-a, position)
�������Dz��������ô����Եõ�
(Albert Einstein, is-a, position)
��Ȼ����Ҳ��һЩ��������ͼѧϰһ��ʵ��ʵ�multiple senses,�����ж��ѡ������֪���ĸ�����ȷ��ѡ���������,ʵ��ʵ������Ҫ�и������֤,Ҳ����ζ����Ҫ�����Ⱦ�ӵ�зḻ��֪ʶ��������,�����������ľ��ǹ���ͼ��,���������������ǵ����������⡣��ѧ������,����һ��fully-disambiguated �� taxonomy���ص�Զ,����������Ӧ�ò�������кܶ�������trick,�����ռ��û��������������־,����UCG����,���л�ȡ��Ϣ�����������,���ҷ�����֪ʶͼ�ס�
�������Ƕ�Taxonomy�Ĺ����������˼�����,������Կ�������Ӣ������ͼ�����������������ġ�
Probase����
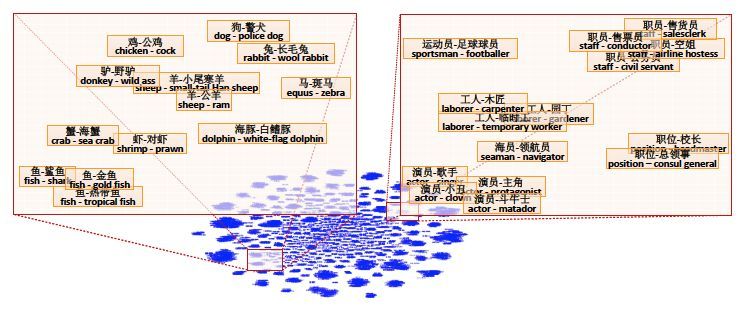
������Probase��ʼ,ͼ�Ĺ���ǿ����probabilistic taxonomy�ĸ���,֪ʶ�Ĵ��ڲ����ǡ��Ǻڼ��ס���,������һ���ĸ�����ʽ����,������һ����IJ�ȷ���Կ��Լ�������������������Ӱ��,�������ں�������֪ʶ���㡣��Probase��������,ÿһ��hypernym-hyponym�Ա������������е�����Ƶ������ʽ����Ӧȷ�Ŷ�,����: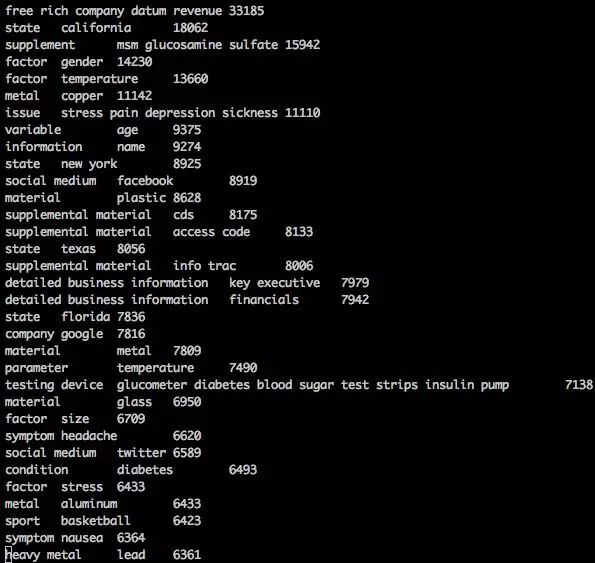 ���� company �� google ��ͼ�����б������� 7816 ��,�ں���Ӧ�ü�����Ŷ�ʱ�Ϳ����ø�ֵ����ô,Probase����Ĺ������̿�������Ϊ��������,����������Hearst Patterns(��ͼ)��ԭʼ�����л������λ���ʶ����ѡ�ԡ�
���� company �� google ��ͼ�����б������� 7816 ��,�ں���Ӧ�ü�����Ŷ�ʱ�Ϳ����ø�ֵ����ô,Probase����Ĺ������̿�������Ϊ��������,����������Hearst Patterns(��ͼ)��ԭʼ�����л������λ���ʶ����ѡ�ԡ�

�ڻ�ú�ѡ��֮��,�ٸ��ݸ��Ӽ���ϵ�ϲ�����״�����ݽṹ,�������̱Ƚϼ�,����: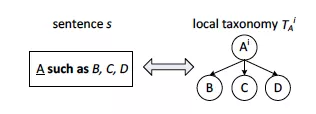
��ԭʼ��sentence�аѺ�ѡʵ���(��(company, IBM)��(company, Nokia)��)�ھ����,�γ�С������;
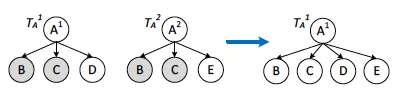 �������ɺ����������ϲ�ԭ���������ϲ���������ͼ��,���ĺ��������������Ĺ�������
�������ɺ����������ϲ�ԭ���������ϲ���������ͼ��,���ĺ��������������Ĺ������� ���Կ���,�ںϲ������Ĺ�����,�����Ǽ���ֱ�Ӻϲ�,����Ҫͨ��һ�����ƶȼ��� Sim(Child(T1), Child(T2))?����,������ƶȼ���Ҳ�Ƚϼ�,ʹ��
���Կ���,�ںϲ������Ĺ�����,�����Ǽ���ֱ�Ӻϲ�,����Ҫͨ��һ�����ƶȼ��� Sim(Child(T1), Child(T2))?����,������ƶȼ���Ҳ�Ƚϼ�,ʹ��Jaccard similarity����,
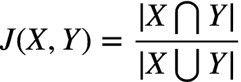
������������������:
A = {Microsoft, IBM, HP}
B = {Microsoft, IBM, Intel}
C = {Microsoft, IBM, HP, EMC, Intel, Google, Apple}����ɵ� J(A,B) = 2/4 = 0.5,J(A,C) = 3/7 = 0.43,�˴��ڹ���ʱ������һ����ֵ,����Ϊ0.5,��ô A �� B ����������ϲ�,�� A �� C ���ԡ�
����ͼ�������ڵ�����
�ܵ���˵,Probase�ķ������DZȽϼ�,�ڹ������ṩ��һ����Ŀ�ܲ����˼·,���Ǵ�ϸ���ϻ����ڲ������⡣�����ġ�Learning Semantic Hierarchies via Word Embeddings������ϸ̽�����������,�����������ķ���,��һ�����������ĵ����Ӣ����˵�������,ʹ�� Chinese Hearst-style lexical patterns ��Ȼȷ�ʻ�ܸ�,�����ٻ��ʽ������������Էdz���,��֮F1ֵҲ�ϲ��Ϊ�˹��������������еľ�ʽ�ṹ�ѶȽϴ�,ͬʱҲʮ�ֵ�Ч,�ɼ���ͼ�����жԼ��ַ������ıȽ�: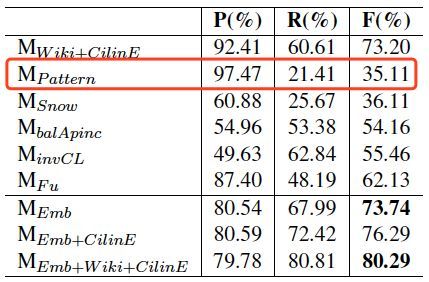
��һ����,����ʹ�� patterns �ķ���,������ṹ����(semantic hierarchy construction)���������Ҳ���ڲ���

��Probase���ּĹ��������������׳��ֹ�ϵȱʧ���ߴ���������
ӳ��ģ����ģ��Ļ�Ͽ��
Ŀǰ�о��Ƚ������Ĺ���������,����ʹ��?Hearst Pattern����,���õ��ֶξ��ǽ����ֲ�ʽ��ʾ���ֶ�,�����������λ�ʻ��PMI��Standard IR Average Precision,������������������offset�ȡ������������ŶӵĹ���,��ʦ���Ŷ������һ��ϴ�������ӳ��ģ���Լ�Hearst Pattern��Taxonomy��������,���ھ���Ҫ�ԡ�Predicting hypernym-hyponym relations for Chinese taxonomy learning�����ܵĹ���չ�����ۡ�
���ⶨ��
����,���ݴ�ֱ�����֪ʶ����������,�����ѹ�����һ��֪ʶͼ�Ļ������,��Ϊ?Taxonomy,?��Ϊ T = (V, R),���� V ��ʾʵ������,R ��ʾ��ϵ�����Ŵ�ͼ��T�в���������is-a��ϵ����,����R������������ȡ�����ݱհ��Ĺ�ϵ����,����R*,������������������еĹ�ϵ����Ϊ���ŶȽϸߵ����ݡ��ٶȰٿ�Ϊ��,���ⲿ����Դ��ȡ��ʵ�弯�ϼ�ΪE,�����е�ÿ��Ԫ��Ϊ,��Ԫ�صĸ�������Cat(x)?,��ô������ȡ�������ݼ��Ͽɱ�ʾΪ: ������������,����Զ���Ϊ:����?Rx?ѧϰ��һ���㷨 F,�ܹ��� _U_��unlabeled������ɸѡ����,�����뵽?T?�С�
������������,����Զ���Ϊ:����?Rx?ѧϰ��һ���㷨 F,�ܹ��� _U_��unlabeled������ɸѡ����,�����뵽?T?�С�
�������
�����¡�Learning Semantic Hierarchies via Word Embeddings�����Ѿ����ܹ���ʹ��������������v(king) - v(queen) = v(man) - v(woman)?�����Կ���������������Ԥ��ʵ������λ��ϵhypernym-hyponym relations(����,�������Ǵ�л�쳣�༲��,θ������θ������)������������ʹ�ô�����,���ڴ������ռ���ѵ��ӳ��ģ�͵�˼·,����������: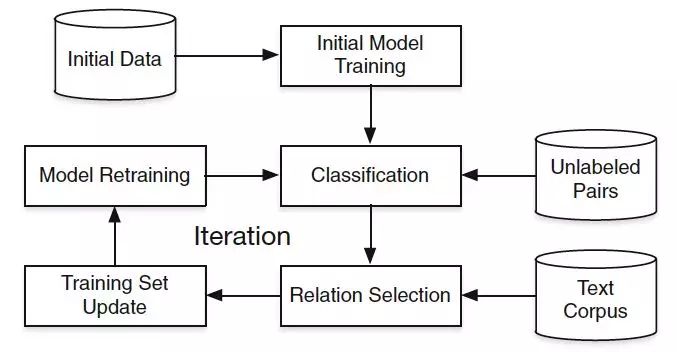
���̿��Ա���Ϊ:���ȴ����е� Taxonomy����ȡ���ֳ�ʼ������,������ӳ�䵽�������ռ�(embedding space),����������ռ���ѵ������ӳ��ģ��(piecewise linear projection model),�Ӷ����������ռ�������ʾ��Ȼ��,������Դ��ȡ�µĹ�ϵ��,ͨ��ģ�͵�Ԥ���Լ����������ɸѡ,��ȡ���µ�һ����ϵ������������ training set,�����µ������ֿ�������У�� projection model,�Դ�ѭ����
ģ�Ͷ���
����ǰ������,��һ����������һ��������trainһ�����Ĵ�����,����ʹ����Skip-gram��ģ��,��10�ڸ�words�������ϻ���˴�����,�����˴����������õ��˴�������,���ڸ����ʻ�x ,��ȡ�ʻ�u���������ʾͿ��Ա�ʾΪ:?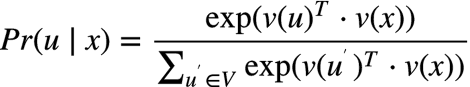 �˴� v(x)��ʾȡ����������,V��ʾ�������ϻ�õĴʵ�
�˴� v(x)��ʾȡ����������,V��ʾ�������ϻ�õĴʵ�
�ڶ���,����ӳ��ģ��,������ģ��Ҳ�dz���,����ij����ϵ������ (xi, yi)?,?ģ�ͼ���������ͨ��һ��ת������M��һ��ƫ���������ת��: ����,����Ҳ��ȡǰ�˵ľ���,��ʵ���з��ֵ���ӳ��ģ�Ͳ����ܺܺõ�ѧ������ռ��ӳ���ϵ,����ȷ�,�ڿ���������ݼ���,���ܱ�ʾ��Ȼ�����������֪ʶ �� ��ʾ���ھ���������֪ʶ �Ŀռ��ʾ�������,�õ���ģ��cover��ס����ô��?�ǾͶ�㼸��ģ�ͷֱ�����,��������û������������֪ʶ�ķ�ʽ,������
����,����Ҳ��ȡǰ�˵ľ���,��ʵ���з��ֵ���ӳ��ģ�Ͳ����ܺܺõ�ѧ������ռ��ӳ���ϵ,����ȷ�,�ڿ���������ݼ���,���ܱ�ʾ��Ȼ�����������֪ʶ �� ��ʾ���ھ���������֪ʶ �Ŀռ��ʾ�������,�õ���ģ��cover��ס����ô��?�ǾͶ�㼸��ģ�ͷֱ�����,��������û������������֪ʶ�ķ�ʽ,������K-meansֱ���ҳ����:
 ���Կ���,���������㷨��,�����ְҵ���ֵ��˲�ͬ�Ĵ���,���Ϳ��Զ�ÿ���طֱ�ӳ��ģ�͡�����ģ�͵��Ż�Ŀ��Ҳ�ܺ�����,��ʵ�� x����������ת����,Ҫ�����ܽӽ�ʵ�� y ����,Ŀ�꺯������:
���Կ���,���������㷨��,�����ְҵ���ֵ��˲�ͬ�Ĵ���,���Ϳ��Զ�ÿ���طֱ�ӳ��ģ�͡�����ģ�͵��Ż�Ŀ��Ҳ�ܺ�����,��ʵ�� x����������ת����,Ҫ�����ܽӽ�ʵ�� y ����,Ŀ�꺯������: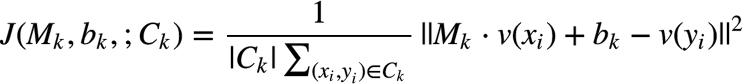 ���� , k?��ʾ�����ĵ� k ����, Ck��ʾ�������µĹ�ϵ���ݼ���,�Ż�����ʹ��
���� , k?��ʾ�����ĵ� k ����, Ck��ʾ�������µĹ�ϵ���ݼ���,�Ż�����ʹ������ݶ��½�(Stochastic Gradient Descent)
ѵ������
ϵͳ����һ��ѭ���ķ�ʽ����ѵ��,����˼����ͨ�������ӳ��ģ�Ͳ��϶�̬������ѵ����_R(t)(t = 1, 2, ..., T) , �ڲ�������ѵ��ģ�ͺ�,����ǿ��Ŀ������Դ�ķ��������������ڳ�ʼ���IJ���Լ��һЩ������:
����Ϊѭ������:
Step 1.

Step 2.
�ھ���ģ��Ԥ���,��Ҫ�پ���ģ��ɸѡ,���õ�����ģ������: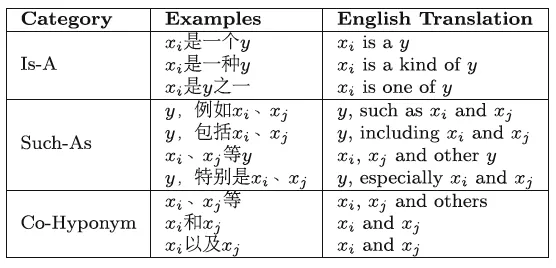 ɸѡ��,���յõ��߿��ŶȵĹ�ϵ����:?
ɸѡ��,���յõ��߿��ŶȵĹ�ϵ����:?
 �ر����,�˴��� f?���Ǽ�ͨ��ģ�弴��,�������ϡ�Is-A������Such-As���͡�Co-Hyponym������ģ�����˷ֱ����:
�ر����,�˴��� f?���Ǽ�ͨ��ģ�弴��,�������ϡ�Is-A������Such-As���͡�Co-Hyponym������ģ�����˷ֱ����:
 �������Ϸ���,���������һ���㷨��������ΰ� U(t)- �еĹ�ϵ����ɸѡ���� U(t)+ ,�Ժ�ѡ���ݼ� U(t)- �еĵĹ�ϵ����,���ݿ��Ŷȶ���positive��negative������,positive���嶨��Ϊ:
�������Ϸ���,���������һ���㷨��������ΰ� U(t)- �еĹ�ϵ����ɸѡ���� U(t)+ ,�Ժ�ѡ���ݼ� U(t)- �еĵĹ�ϵ����,���ݿ��Ŷȶ���positive��negative������,positive���嶨��Ϊ: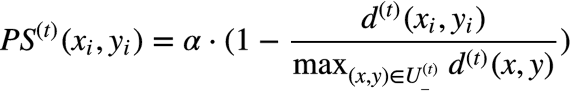
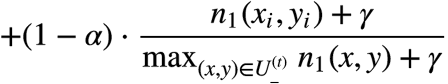
����,a�ķ�Χ��(0,1),��һ������ϵ��,gamma��ƽ��ϵ��,���������˾���ֵa = 0.5, gamma = 1��
negative���嶨��Ϊ:
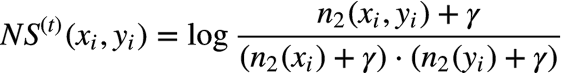 ��� NS(t) ������,���� xi �� yi �������ǡ�co-hyponyms����ϵ,���ǡ�Is-A����ϵ�Ŀ�����Խ�͡�����,�˴��漰���㷨����Ҫ���ͬʱ��С��,��ʽ����ʾ��������:
��� NS(t) ������,���� xi �� yi �������ǡ�co-hyponyms����ϵ,���ǡ�Is-A����ϵ�Ŀ�����Խ�͡�����,�˴��漰���㷨����Ҫ���ͬʱ��С��,��ʽ����ʾ��������: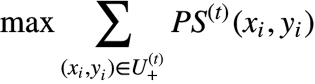
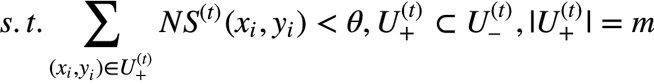
����,m ��ʾ U(t)+ ��size,theta ��һ��Լ����ֵ�����Ƿ������������Ԥ���������(budgeted maximum coverage proplem)��һ������,�Ǹ�NP-hard����,��Ҫ����̰���㷨�����:
 ���,���˸��� U(t)+ ,��һ���ǰ� U(t)+ ��ԭtraining���ݺϲ�:
���,���˸��� U(t)+ ,��һ���ǰ� U(t)+ ��ԭtraining���ݺϲ�: Step 3.
Step 3.
 Sep 4.
Sep 4.
ģ��Ԥ��

�ܽ�
���ĵ��е�֪ʶͼ����������Ϊ������������������еĹ���,���Ӣ��,������pattern����ơ�����Դ�ȶ��зdz���IJ��졣���ĵĺ���Ҳ����������������з��ֵ�����:
-
��������ϵͳ�����˾���ķ���,���ڵ��ι�����,����Ч�����ھ������ĸ��� K ��������,�� K ��С�������Ч�����Ǻܶ�,����� K = 10 �����Ч����ѡ�����������õĹ���Ļ�,����Ч����ܲ����������������ǿ��������֪ʶͼ��,������������ֱ����(ҽ��)��֪ʶͼ��,��ʵ�������dz��Ը�������֪ʶ����Ϊ���������ݼ�,�Ӷ��ֱ�ѵ��ӳ��ģ�͡�
-
���,�ھ��������,����ijЩ����λ���������,����˵��ҩ��ʶ�����ҩ�ĸ���,��Ȼ��ҩ�е�ȷ�����ɲ�ҩ����,���Ǵӷ���ĽǶȿ��Ļ��Dz������ġ����������������Ϊ����Դ�����ı��������,ͬʱ���û���ⲿ֪ʶ�����Ļ�Ҳ�����״��������ⲿ��������ʵ�ʵ�ʵ���л���ݾ�������Դ��һЩ�����pattern���,�����ڡ�ʵ�����ѧ��һ����,�������Է��ೣ�þ�ʽ��
���� * ��ͬ,��Ϊ a1, a2, a3
x �� * ������:y1, y2, y3 �� �˹���ǰ�ڹ۲������������Ϣ��ȡ���ٻ��ʺ�ȷ�ʡ�

cs