ǰ�����ҷ�����pandas.merge�÷���⣬��ڷ���pandas���ݺϲ����������ƪ��pandas.concat�÷���⣬�ο�����Python�������ݷ�����pandas��������������
pandas.merge�����б�����ͼ������ֻ��objs�DZ���ò��������ⳣ�ò�������objs��axis��join��keys��ignore_index��

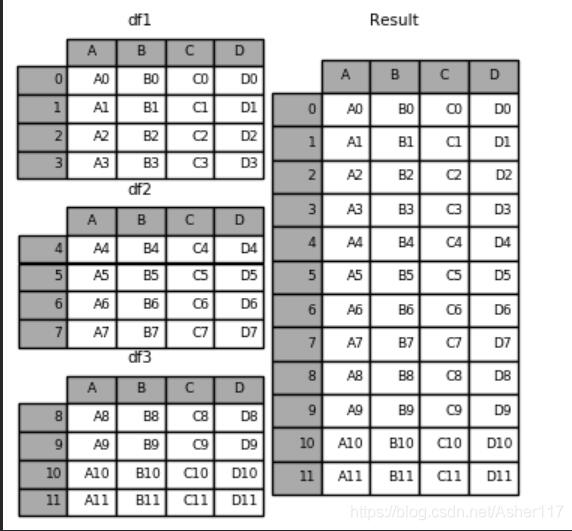
1.pd.concat([df1,df2,df3]), Ĭ��axis=0����0���Ϻϲ���
2.pd.concat([df1,df4],axis=1)�C��1���Ϻϲ�

3.pd.concat([df1,df2,df3],keys=[��x', ��y', ��z'])�C�ϲ�ʱ�������ֽ�����λ�������

4.pd.concat([df1, df4], axis=1, join=��inner')�C���������Ӻϲ���joinĬ��Ϊouter�����ӡ�

5.pd.concat([df1, df4], ignore_index=True)�C��ԭ��DataFrame������û�������ʱ��concat֮����Բ���Ҫԭ����������

���ƪ��pandas.merge�÷���⣡����
���䣺python3��pandas���ϲ�concat��merge��
pandas�����������ݵ�ʱ��������Ҫ�õ����ݵĺϲ����������������ַ�ʽ��concat��append��merge��
1��concat
��concat��һ�ֻ����ĺϲ���ʽ������concat���кܶ�������Ե������ϲ�������Ҫ��������ʽ��axis��ָ���ϲ�����axis=0��Ԥ��ֵ�����δ�趨�κβ���ʱ������Ĭ��axis=0����0��ʾ���ºϲ���1��ʾ���Һϲ���
import pandas as pd
import numpy as np
#�������ϼ�
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*2, columns=['a','b','c','d'])
#concat����ϲ�
res = pd.concat([df1, df2, df3], axis=0)
#��ӡ���
print(res)
'''
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
0 1.0 1.0 1.0 1.0
1 1.0 1.0 1.0 1.0
2 1.0 1.0 1.0 1.0
0 2.0 2.0 2.0 2.0
1 2.0 2.0 2.0 2.0
2 2.0 2.0 2.0 2.0
'''
����indexΪ0��1��2��0��1��2��ʽ��Ϊʲô������������������ʵ����Ȼ���պϲ�ǰ��index��������ġ���ϣ���������뿴����ʾ����
ignore_index (���� index)
���ú��indexΪ0��1������8
res = pd.concat([df1, df2, df3], axis=0, ignore_index=True)# ��ignore_index����ΪTrue
print(res) #��ӡ���
'''
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
5 1.0 1.0 1.0 1.0
6 2.0 2.0 2.0 2.0
7 2.0 2.0 2.0 2.0
8 2.0 2.0 2.0 2.0
'''
join ���ϲ���ʽ��
join='outer'ΪԤ��ֵ�����δ�趨�κβ���ʱ������Ĭ��join='outer'���˷�ʽ������column��������ϲ�������ͬ��column���ºϲ���һ���������Ե�column���Գ��У�ԭ��û��ֵ��λ�ý���NaN��䡣
import pandas as pd
import numpy as np
#�������ϼ�
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'], index=[1,2,3])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['b','c','d','e'], index=[2,3,4])
res = pd.concat([df1, df2], axis=0, join='outer') #����"��"�ϲ�df1��df2
print(res)
'''
a b c d e
1 0.0 0.0 0.0 0.0 NaN
2 0.0 0.0 0.0 0.0 NaN
3 0.0 0.0 0.0 0.0 NaN
2 NaN 1.0 1.0 1.0 1.0
3 NaN 1.0 1.0 1.0 1.0
4 NaN 1.0 1.0 1.0 1.0
'''
res = pd.concat([df1, df2], axis=0, join='inner') #����"��"�ϲ�df1��df2
#��ӡ���
print(res)
'''
b c d
1 0.0 0.0 0.0
2 0.0 0.0 0.0
3 0.0 0.0 0.0
2 1.0 1.0 1.0
3 1.0 1.0 1.0
4 1.0 1.0 1.0
'''
join_axes (���� axes �ϲ�)
import pandas as pd
import numpy as np
#�������ϼ�
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'], index=[1,2,3])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['b','c','d','e'], index=[2,3,4])
#����`df1.index`���к���ϲ�
res = pd.concat([df1, df2], axis=1, join_axes=[df1.index])
#��ӡ���
print(res)
# a b c d b c d e
# 1 0.0 0.0 0.0 0.0 NaN NaN NaN NaN
# 2 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0
# 3 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0
�����ű��У�join_axes=[df1.index]��������df1��index���ϲ������Կ��������ȥ����df2�г��ֵ�df1��û�е�index=4��һ�С�
2��append (��������)
appendֻ������ϲ���û�к���ϲ���
import pandas as pd
import numpy as np
#�������ϼ�
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*1, columns=['a','b','c','d'])
s1 = pd.Series([1,2,3,4], index=['a','b','c','d'])
#��df2�ϲ���df1�����棬�Լ�����index������ӡ�����
res = df1.append(df2, ignore_index=True)
print(res)
# a b c d
# 0 0.0 0.0 0.0 0.0
# 1 0.0 0.0 0.0 0.0
# 2 0.0 0.0 0.0 0.0
# 3 1.0 1.0 1.0 1.0
# 4 1.0 1.0 1.0 1.0
# 5 1.0 1.0 1.0 1.0
#�ϲ����df����df2��df3�ϲ���df1�����棬�Լ�����index������ӡ�����
res = df1.append([df2, df3], ignore_index=True)
print(res)
# a b c d
# 0 0.0 0.0 0.0 0.0
# 1 0.0 0.0 0.0 0.0
# 2 0.0 0.0 0.0 0.0
# 3 1.0 1.0 1.0 1.0
# 4 1.0 1.0 1.0 1.0
# 5 1.0 1.0 1.0 1.0
# 6 1.0 1.0 1.0 1.0
# 7 1.0 1.0 1.0 1.0
# 8 1.0 1.0 1.0 1.0
#�ϲ�series����s1�ϲ���df1���Լ�����index������ӡ�����
res = df1.append(s1, ignore_index=True)
print(res)
# a b c d
# 0 0.0 0.0 0.0 0.0
# 1 0.0 0.0 0.0 0.0
# 2 0.0 0.0 0.0 0.0
# 3 1.0 2.0 3.0 4.0
3��merge
�������������еĹؼ���key���ϲ���key����������������ȫһ�µģ���
3.1����һ��key�ϲ�
import pandas as pd
#�������ϼ�����ӡ��
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
print(left)
# A B key
# 0 A0 B0 K0
# 1 A1 B1 K1
# 2 A2 B2 K2
# 3 A3 B3 K3
print(right)
# C D key
# 0 C0 D0 K0
# 1 C1 D1 K1
# 2 C2 D2 K2
# 3 C3 D3 K3
#����key column�ϲ�������ӡ��
res = pd.merge(left, right, on='key')
print(res)
A B key C D
# 0 A0 B0 K0 C0 D0
# 1 A1 B1 K1 C1 D1
# 2 A2 B2 K2 C2 D2
# 3 A3 B3 K3 C3 D3
3.2 ��������key�ϲ�
�ϲ�ʱ��4�ַ���how = ['left', 'right', 'outer', 'inner']��Ԥ��ֵhow='inner'��
inner�����չؼ������֮��ȥ��������кϲ���ΪNaN���С�
outer �������������
left����������ߺϲ���ΪNaN����
right���������ұߺϲ���ΪNaN����
import pandas as pd
import numpy as np
#�������ϼ�����ӡ��
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
print(left)
'''
key1 key2 A B
0 K0 K0 A0 B0
1 K0 K1 A1 B1
2 K1 K0 A2 B2
3 K2 K1 A3 B3
'''
print(right)
'''
key1 key2 C D
0 K0 K0 C0 D0
1 K1 K0 C1 D1
2 K1 K0 C2 D2
3 K2 K0 C3 D3
'''
#����key1��key2 columns���кϲ�������ӡ�����ֽ��['left', 'right', 'outer', 'inner']
res = pd.merge(left, right, on=['key1', 'key2'], how='inner')
print(res)
'''
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
'''
res = pd.merge(left, right, on=['key1', 'key2'], how='outer')
print(res)
'''
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K0 K1 A1 B1 NaN NaN
2 K1 K0 A2 B2 C1 D1
3 K1 K0 A2 B2 C2 D2
4 K2 K1 A3 B3 NaN NaN
5 K2 K0 NaN NaN C3 D3
'''
res = pd.merge(left, right, on=['key1', 'key2'], how='left')
print(res)
'''
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K0 K1 A1 B1 NaN NaN
2 K1 K0 A2 B2 C1 D1
3 K1 K0 A2 B2 C2 D2
4 K2 K1 A3 B3 NaN NaN
'''
res = pd.merge(left, right, on=['key1', 'key2'], how='right')
print(res)
'''
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
3 K2 K0 NaN NaN C3 D3
'''
3.3 Indicator
indicator=True�Ὣ�ϲ��ļ�¼�����µ�һ�С�
import pandas as pd
#�������ϼ�����ӡ��
df1 = pd.DataFrame({'col1':[0,1], 'col_left':['a','b']})
df2 = pd.DataFrame({'col1':[1,2,2],'col_right':[2,2,2]})
print(df1)
# col1 col_left
# 0 0 a
# 1 1 b
print(df2)
# col1 col_right
# 0 1 2
# 1 2 2
# 2 2 2
# ����col1���кϲ���������indicator=True������ӡ��
res = pd.merge(df1, df2, on='col1', how='outer', indicator=True)
print(res)
# col1 col_left col_right _merge
# 0 0.0 a NaN left_only
# 1 1.0 b 2.0 both
# 2 2.0 NaN 2.0 right_only
# 3 2.0 NaN 2.0 right_only
# �Զ�indicator column�����ƣ�����ӡ��
res = pd.merge(df1, df2, on='col1', how='outer', indicator='indicator_column')
print(res)
# col1 col_left col_right indicator_column
# 0 0.0 a NaN left_only
# 1 1.0 b 2.0 both
# 2 2.0 NaN 2.0 right_only
# 3 2.0 NaN 2.0 right_only
3.4 ����index�ϲ�
import pandas as pd
#�������ϼ�����ӡ��
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=['K0', 'K1', 'K2'])
right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=['K0', 'K2', 'K3'])
print(left)
# A B
# K0 A0 B0
# K1 A1 B1
# K2 A2 B2
print(right)
# C D
# K0 C0 D0
# K2 C2 D2
# K3 C3 D3
#�����������ϼ���index���кϲ���how='outer',����ӡ��
res = pd.merge(left, right, left_index=True, right_index=True, how='outer')
print(res)
# A B C D
# K0 A0 B0 C0 D0
# K1 A1 B1 NaN NaN
# K2 A2 B2 C2 D2
# K3 NaN NaN C3 D3
#�����������ϼ���index���кϲ���how='inner',����ӡ��
res = pd.merge(left, right, left_index=True, right_index=True, how='inner')
print(res)
# A B C D
# K0 A0 B0 C0 D0
# K2 A2 B2 C2 D2
3.5 ���overlapping������
����ű��У�boys��girls��������age����������ֵ��ͬ�������Ҫ�ںϲ�ʱ���Ϻ�suffixes����ʾ���֡�
import pandas as pd
#�������ϼ�
boys = pd.DataFrame({'k': ['K0', 'K1', 'K2'], 'age': [1, 2, 3]})
girls = pd.DataFrame({'k': ['K0', 'K0', 'K3'], 'age': [4, 5, 6]})
#ʹ��suffixes���overlapping������
res = pd.merge(boys, girls, on='k', suffixes=['_boy', '_girl'], how='inner')
print(res)
# age_boy k age_girl
# 0 1 K0 4
# 1 1 K0 5
������pandas���й��ںϲ���һЩ��������Ȼ�������ϰ�Ķ��ˣ���������Ҳ�Ǵ�ͬС�졣ϣ����Ҷ��֧��վ�����͡����д����δ������ȫ�ĵط��������ߴͽ̡�
jsjbwy