前言
这篇博文接上一篇“使用requests和re模块爬取i春秋论坛的精品贴(小爬虫)”。
这一次学习的是爬取某个学习站点的所有用户头像。这个网站是我个人认为挺好的一个学习网站(没有做广告,全程马赛克),整好今天有空就爬下这个网站所有的用户的头像,并且使用用户名作为文件名。仅供学习。
正文
首先分析用户个人空间的url,发现用户空间的url的结构是这样的,可以使用for循环遍历用户id。
https://www.马赛克.com/user/用户id/
接着分析用户名和用户头像在哪些固定的html标签中,这里可以使用浏览器自带的调试器。
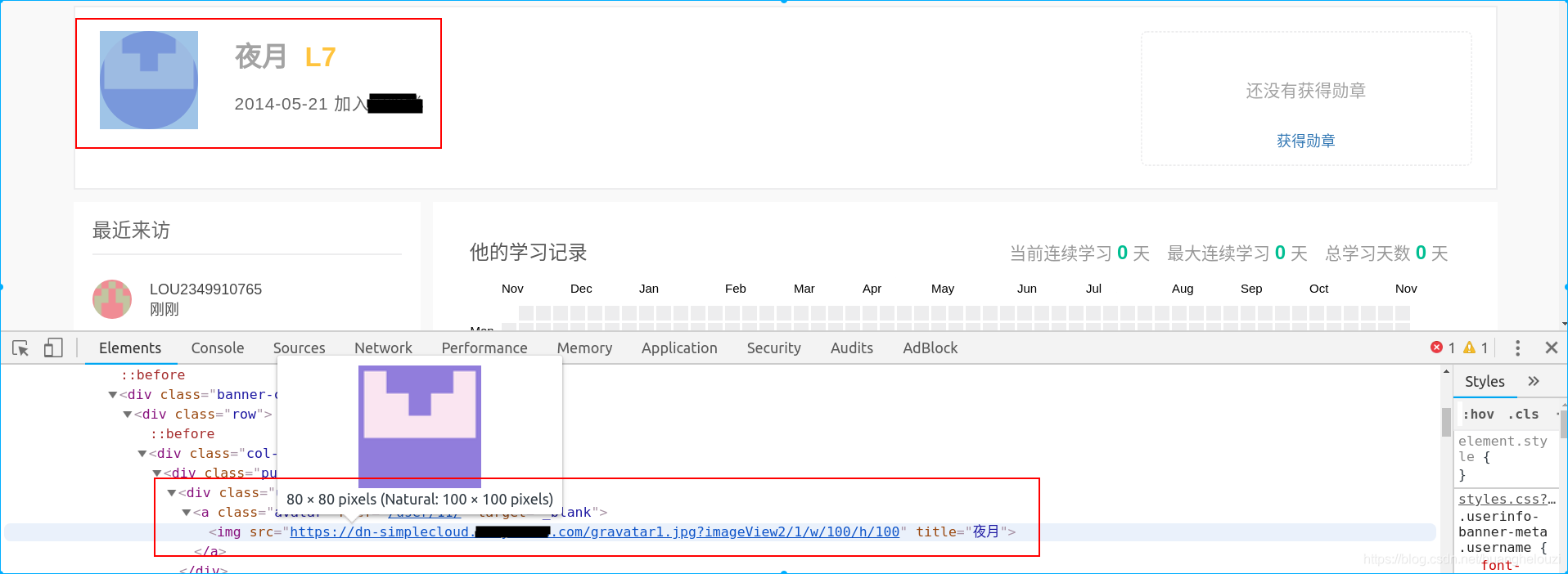
大概在源代码的第206-211行中,找到头像地址和对应的用户名。不过为了方便处理,用户将取第216行的用户名。


按照上一篇的思路就可以写出下面的爬取用户头像最原始的Python脚本。
'''picture
<a class="avatar" href="/user/11/" target="_blank">
<img src="https://dn-simplecloud.马赛克.com/gravatar1.jpg?imageView2/1/w/100/h/100" title="夜月">
</a>
'''
import requests
import urllib
import re
import os
url = "https://www.马赛克.com/user/%s/"
headers = {
'Host': 'www.马赛克.com',
'Connection': 'close',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8',
}
users = []
def get_picture_and_username(url, users):
'''
返回的user是一个list,内容为list(id, username, picture)
'''
for i in range(11, 1000):
user = []
re_picture = '<a class="avatar" href="/user/'+str(i)+'/" target="_blank">\s*<img src="(.+?)"'
re_username = '<span class="username">(.+?)</span>'
url = "https://www.马赛克.com/user/%s/"%i
try:
response = requests.get(url, headers=headers, timeout=5)
html = response.text
if(re.findall(re_username, html)==list()):
continue
user.append(i)
user.extend(re.findall(re_username, html))
user.append(re.findall(re_picture, html).pop())
users.append(user)
except Exception as e:
print(e)
print("正在遍历id为%s的用户"%i)
return users
def download_picture(users, dir="/tmp/download_dir/"):
'''
下载用户的头像
'''
get_picture_and_username(url, users)
if not (len(users)):
print("获取用户数据失败!")
return
if not os.path.exists(dir):
os.mkdir(dir)
for user in users:
print("正在下载%s的头像..."%user[1])
urllib.request.urlretrieve(user[2], dir+"%04d%s.png"%(user[0],user[1]))
if __name__ == '__main__':
download_picture(users)
正则表达式中的
re_picture = '<a class="avatar" href="/user/'+str(i)+'/" target="_blank">\s*<img src="(.+?)"'
匹配的是下面html代码中的图片地址
<a class="avatar" href="/user/11/" target="_blank">
<img src="https://dn-simplecloud.马赛克.com/gravatar1.jpg?imageView2/1/w/100/h/100"
因为需要匹配多行html代码所以使用\s*来匹配空字符(换行之类的)。
下载图片使用python3标准库urllib的request.urlretrieve,在python2中对应的是urllib.urlretrieve。
运行结果:

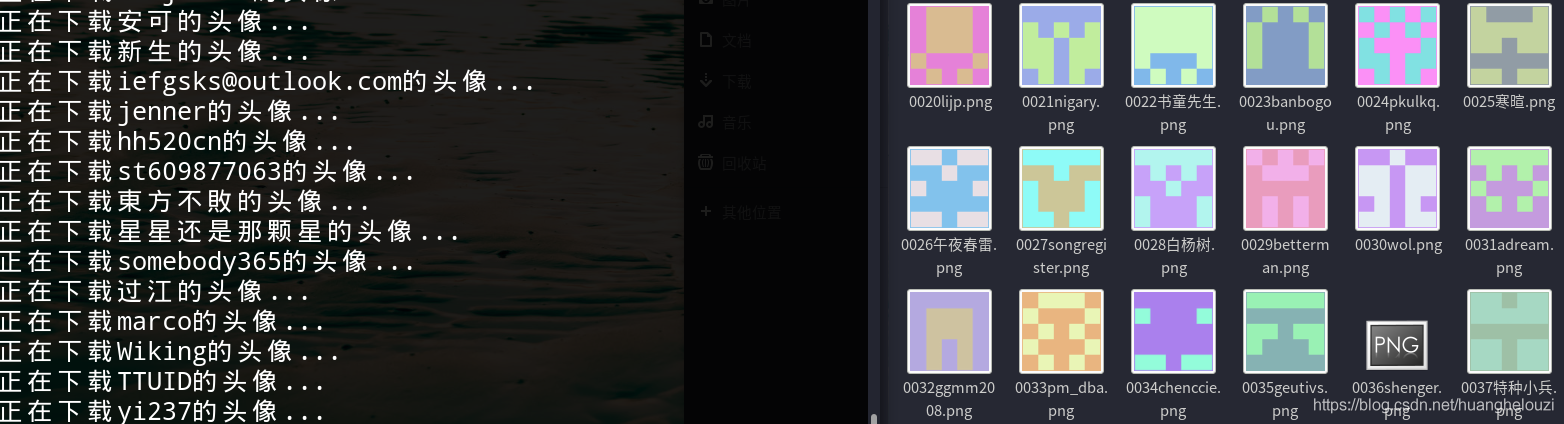
需要主要注意的是该站点大概有一百万的用户,按照上面的脚本去跑肯定是不行的,需要用到多线程或者其他的技术,这里只是提供一个思路。
后言
共勉。
cs