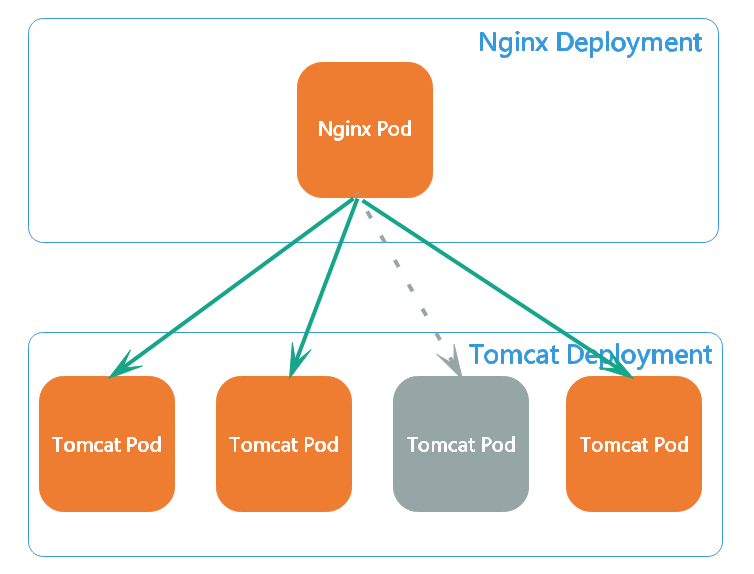
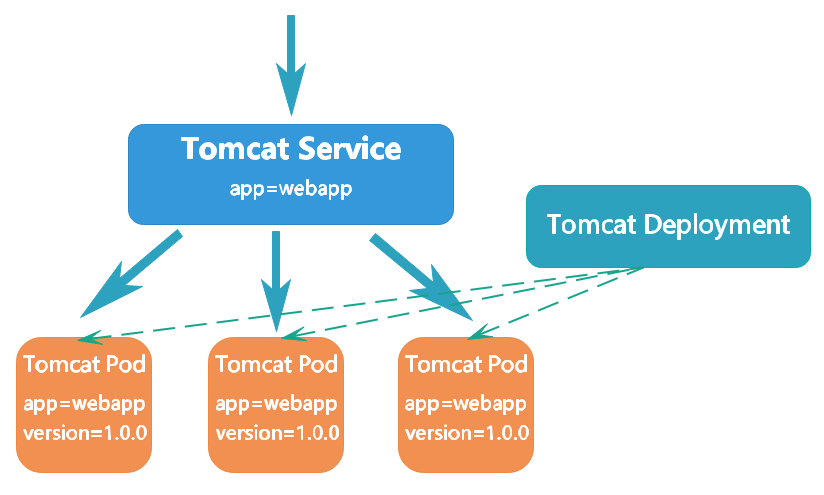
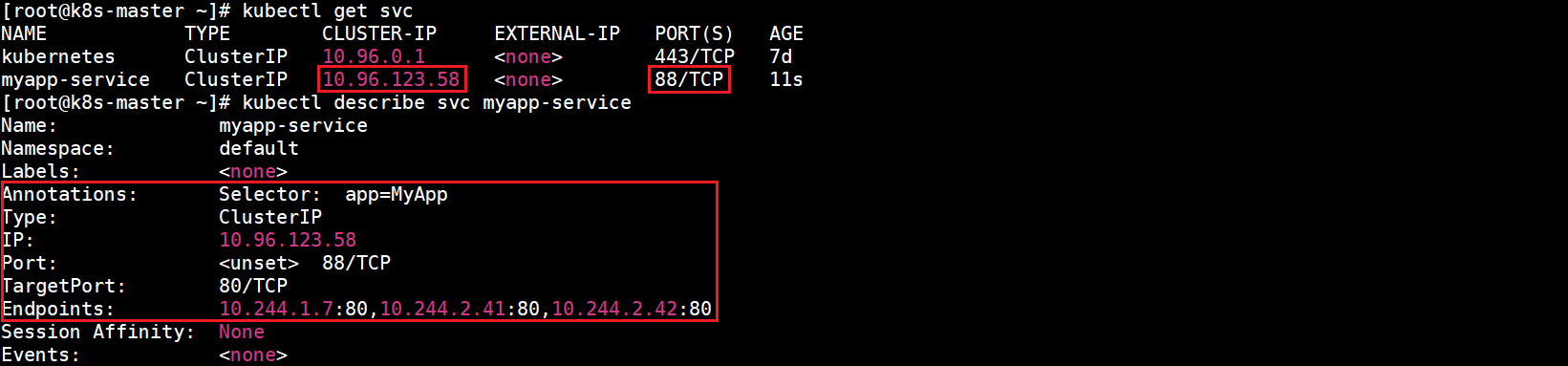
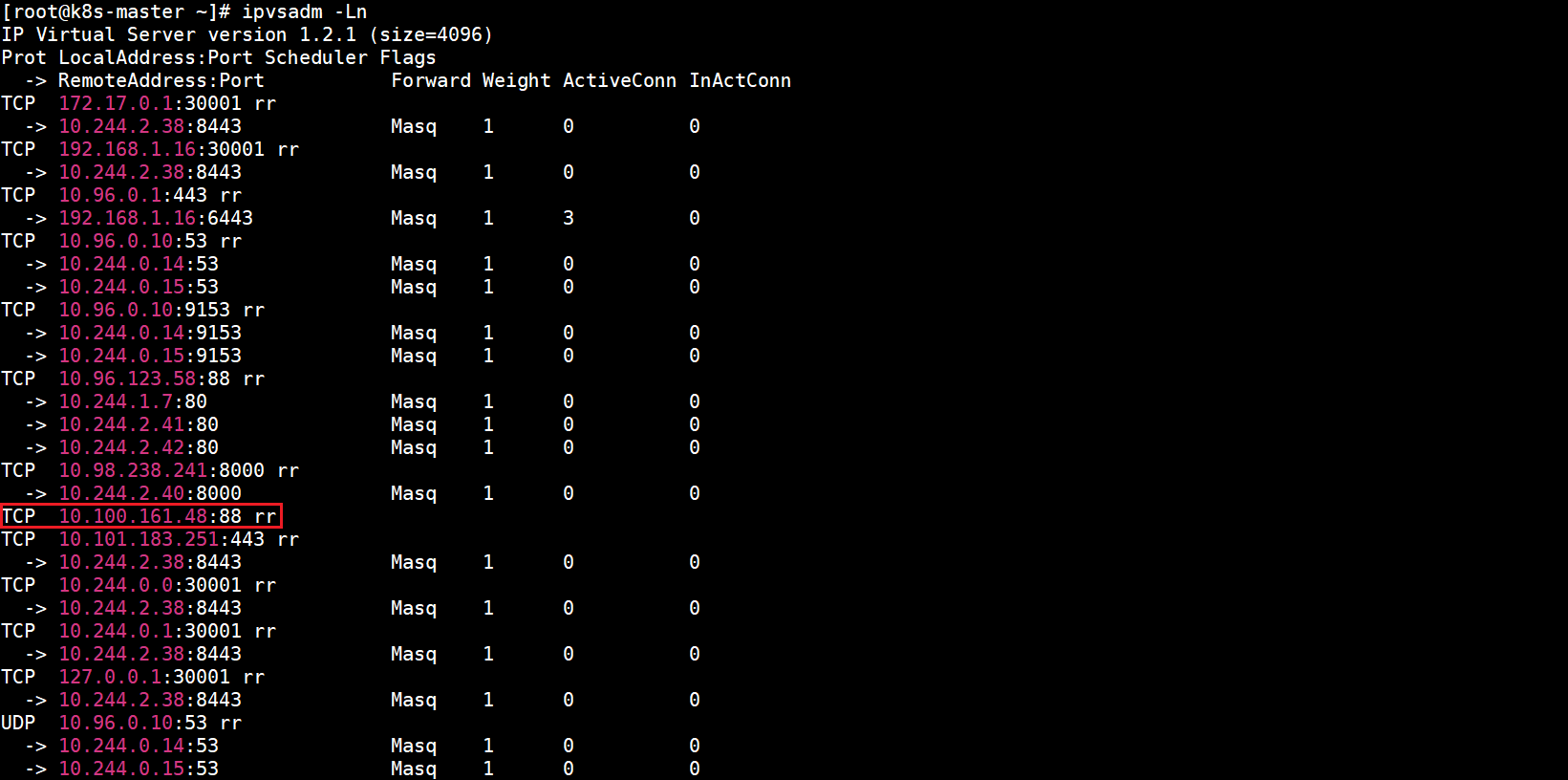
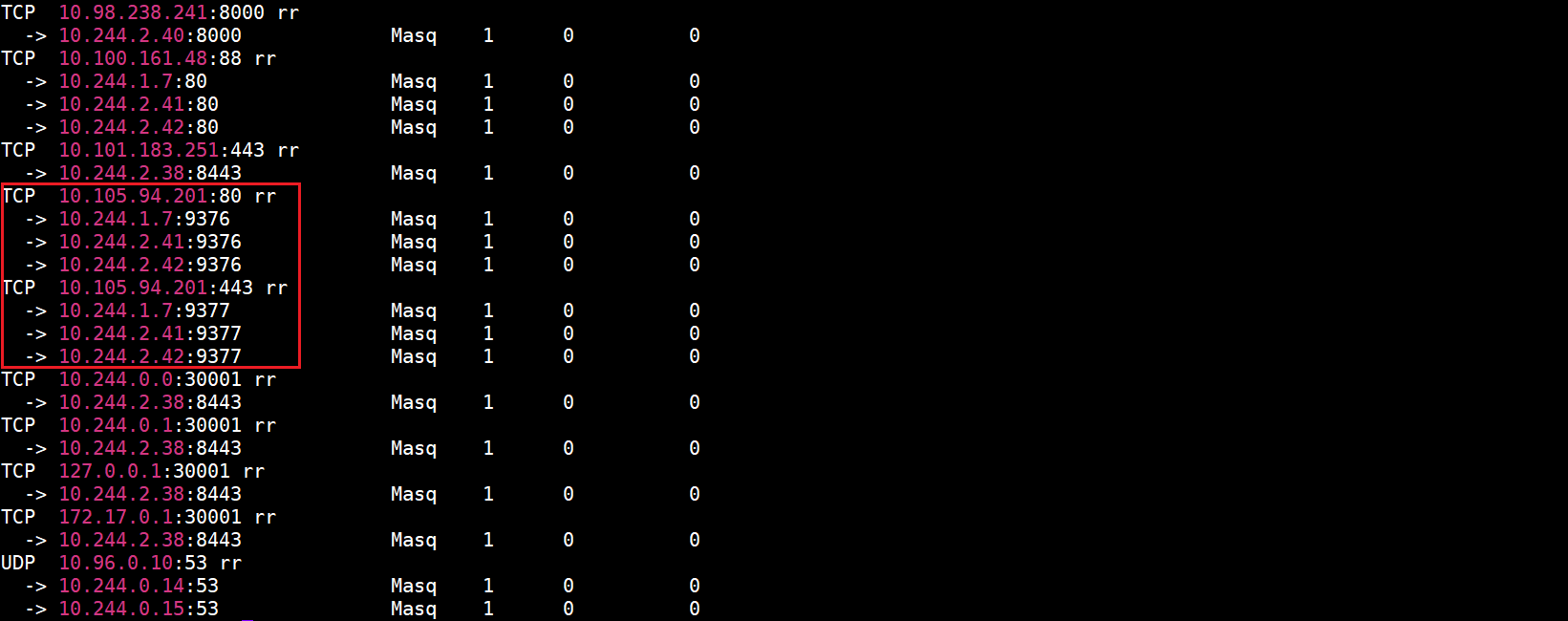
kubectl apply -f myapp-specify-cluster-ip-service.yaml
查看所有Service和myapp-specify-cluster-ip-service详细信息:

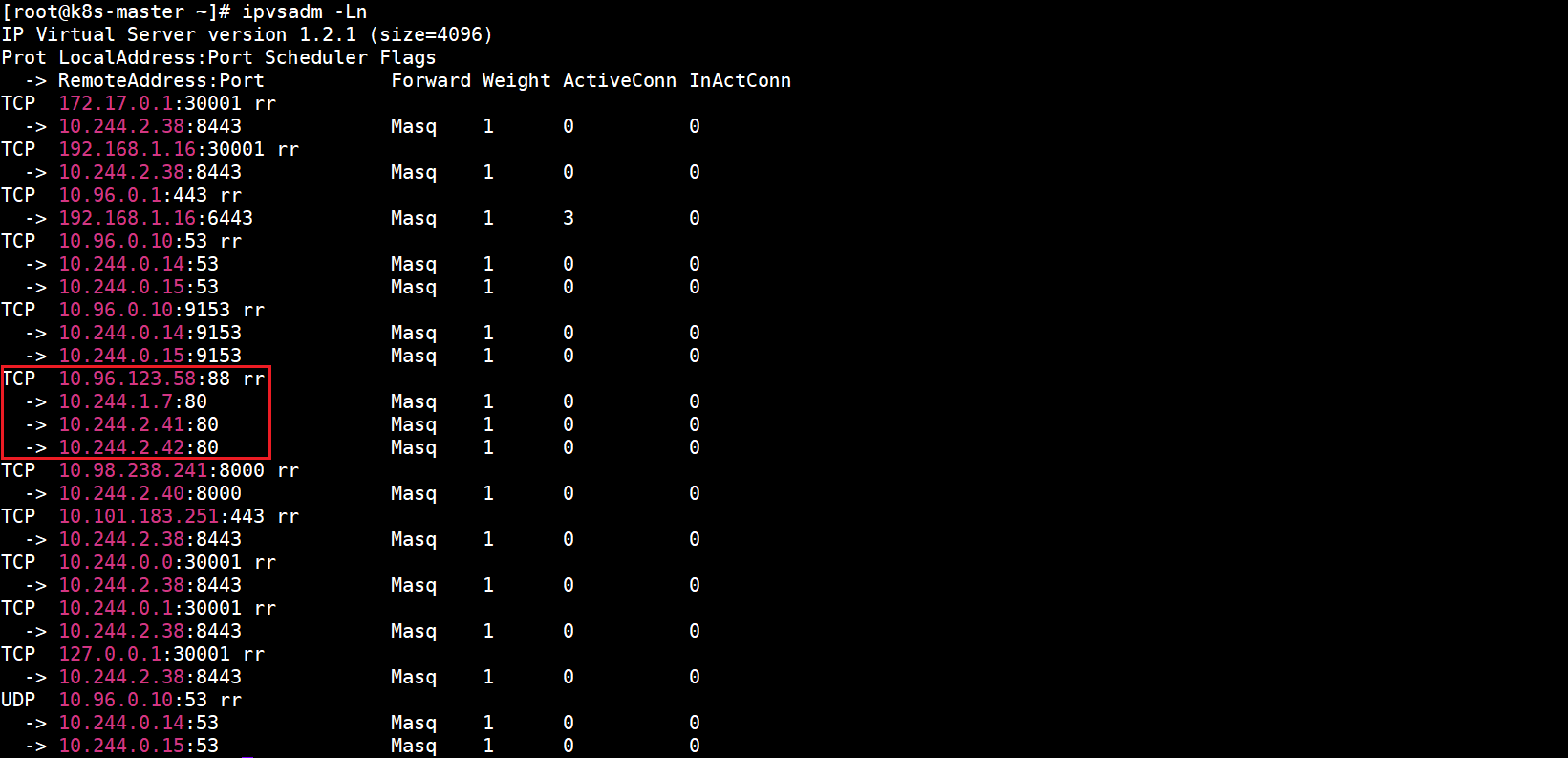
查看当前虚拟服务列表(只截取了部分内容):

五、VIP和Service代理
在Kubernetes集群中,每个Node运行一个kube-proxy进程。kube-proxy负责为Service实现了一种VIP(虚拟 IP)的形式,而不是ExternalName的形式。
1.不使用DNS轮询的原因
- DNS实现的历史由来已久,它不遵守记录TTL,并且在名称查找结果到期后对其进行缓存。
- 有些应用程序仅执行一次DNS查找,并无限期地缓存结果。
- 即使应用和库进行了适当的重新解析,DNS记录上的TTL值低或为零也可能会给DNS带来高负载,从而使管理变得困难。
2.userspace代理模式
Kubernetes v1.0开始至Kubernetes v1.1(包括v1.1),默认使用userspace模式。
这种模式,kube-proxy会监视Kubernetes控制节点对Service和Endpoint对象的添加和移除。对每个Service,它会在在本地Node上随机打开一个端口(代理端口)。任何连接到代理端口的请求,都会被代理到Service后端中的某个Pod上面,至于被代理到当前Service后端的哪个Pod对象取决于当前Service的调度方式,是kube-proxy基于SessionAffinity确定的。默认的调度策略是kube-proxy在userspace模式下通过轮询(round-robin)算法来选择后端的Pod。最后,它会配置iptables规则,捕获到达该Service的clusterIP和port的请求并重定向到代理端口,代理端口再代理请求到后端的Pod。
userspace代理的过程为:请求到达service后,其被转发至内核空间,经由套接字送往用户空间的kube-proxy,然后再由它送回内核空间,并调度至后端Pod。传输效率较低。
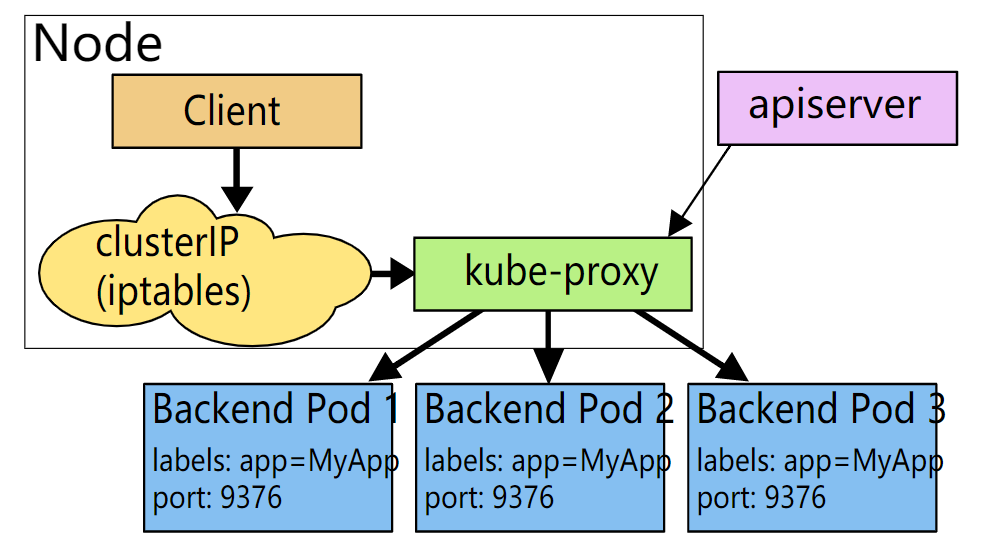
3.iptables代理模式
Kubernetes v1.1添加了iptables代理模式,从Kubernetes v1.2开始,默认使用iptables模式。
这种模式,kube-proxy会监视Kubernetes控制节点对Service和Endpoint对象的添加和移除。对每个Service,它会配置iptables规则,从而捕获到达该Service 的clusterIP和port的请求并将请求重定向到Service的后端中的某个Pod上面。对于每个Endpoint对象,它也会配置选择一个后端Pod的iptables规则。默认的调度策略是kube-proxy在iptables模式下通过随机(random)算法来选择一个后端的Pod。
iptables代理过程为:请求到达service后,其被相关service上的iptables规则进行调度和目标地址转换后再转发至集群内的Pod对象之上。使用iptables处理流量具有较低的系统开销,因为流量由Linux netfilter处理,而无需在用户空间和内核空间之间切换。
如果kube-proxy在iptables模式下运行,并且所选的第一个Pod没有响应,则连接失败。而userspace模式在这种情况下,kube-proxy将检测到与第一个Pod的连接已失败,并会自动使用后端的其他Pod重试。可以使用Pod的readiness探测器验证后端Pod可以正常工作,以便iptables模式下的kube-proxy仅看到测试正常的后端Pod。这样可以避免将流量通过kube-proxy发送到已知已失败的Pod上。
4.IPVS代理模式
Kubernetes v1.8添加了ipvs代理模式。
在ipvs模式下,kube-proxy监视Kubernetes的Service和Endpoint,调用netlink接口相应地创建IPVS规则,并定期将IPVS规则与Kubernetes的Service和Endpoint同步。该控制循环可确保IPVS状态与所需状态匹配。访问服务时,IPVS将流量定向到其中一个后端Pod。
IPVS代理模式基于类似于iptables模式的netfilter挂钩函数,但使用哈希表作为基础数据结构并在内核空间中工作。这意味着,与iptables模式下的kube-proxy相比,IPVS模式下的kube-proxy重定向通信的延迟更短,并且在同步代理规则时具有更好的性能。与其他代理模式相比,IPVS模式还支持更高的网络流量吞吐量。IPVS还为负载均衡提供了更多选项。这些选项如下:
rr:轮询(round-robin)lc:最小连接数(least connection)dh:目标哈希(destination hashing)sh:源哈希(source hashing)sed:最短期望延迟(shortest expected delay)nq:永不排队(never queue)
注意:要在IPVS模式下运行kube-proxy,必须在启动kube-proxy之前使IPVS Linux在节点上可用。当 kube-proxy以IPVS代理模式启动时,它将验证IPVS内核模块是否可用。如果未检测到IPVS内核模块,则kube-proxy将退回到以iptables代理模式运行。

如果要确保每次都将来自特定客户端的连接传递到同一Pod,可以通过将service.spec.sessionAffinity设置为"ClientIP",默认值是 “None”,来基于客户端的IP地址选择会话关联。可以通过service.spec.sessionAffinityConfig.clientIP.timeoutSeconds来设置最大会话停留时间,默认值为10800秒,即3小时。
5.避免冲突
为了使用户能够为他们的Service选择一个端口号,必须确保不能有2个Service发生冲突。Kubernetes通过为每个Service分配它们自己的 IP地址来实现。为了保证每个Service被分配到一个唯一的IP,需要一个内部的分配器能够原子地更新etcd中的一个全局分配映射表,这个更新操作要先于创建每一个Service。为了使Service能够获取到IP,这个映射表对象必须在注册中心存在,否则Service创建将会失败并显示一条指示一个IP不能被分配的消息。
在控制平面中,一个后台Controller负责创建映射表(需要支持从使用了内存锁的Kubernetes的旧版本迁移过来)。同时Kubernetes会通过控制器检查不合理的分配(如管理员干预导致的)以及清理已被分配但不再被任何Service使用的IP地址。
6.Service IP地址
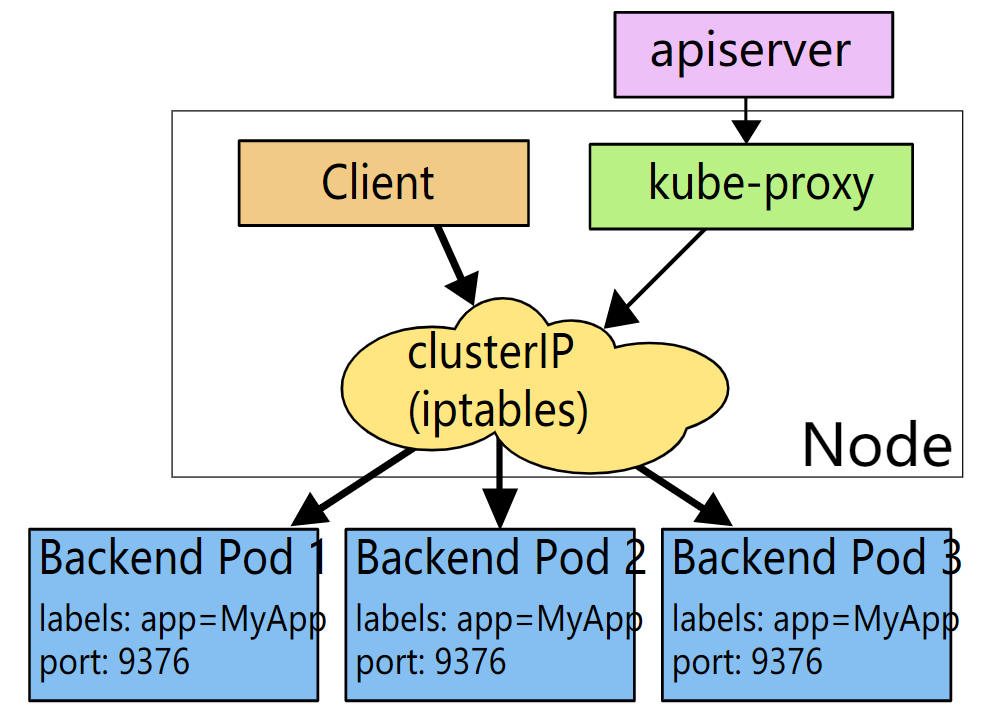
Service的IP不像Pod的IP地址实际路由到一个固定的目的地,它实际上不能通过单个主机来进行应答。所以使用iptables来定义一个虚拟IP地址(VIP),它可以根据需要透明地进行重定向。当客户端连接到VIP时,它们的流量会自动地传输到一个合适的Endpoint。Service的环境变量和DNS实际上会根据Service的虚拟IP地址和端口来进行填充。kube-proxy支持三种代理模式各自的操作略有不同。
userspace模式,创建Service时,Kubernetes master会给它分配一个虚拟IP地址,该Service会被集群中所有的kube-proxy实例观察到。当代理看到一个新的Service时,它会打开一个新的随机端口(代理端口),建立一个从该虚拟IP地址重定向到新端口的iptables,并开始接收请求连接。当一个客户端连接到一个Service的虚拟IP地址时,iptables规则开始起作用,它会重定向该数据包到Service的代理端口。Service代理选择一个后端的Pod并将客户端的流量代理到该后端Pod上。这意味着Service的所有者能够选择他们想使用的任何端口而不会发生冲突。客户端可以简单地连接到一个IP和端口,而不需要知道实际访问了哪些Pod。
iptables模式,创建Service时,Kubernetes控制面板会给它分配一个虚拟IP地址,该Service会被集群中所有的kube-proxy实例观察到。当代理看到一个新的Service时, 它会配置一系列从虚拟IP地址重定向per-Service规则的iptables规则。该per-Service规则链接到重定向(使用目标NAT)到后端的Pod的per-Endpoint规则。当一个客户端连接到一个Service的虚拟IP地址时,iptables规则开始起作用。一个后端Pod会被选择(或者根据会话亲和性或者随机)并且数据包被重定向到该后端Pod。与userspace代理不同,数据包从来不会拷贝到用户空间,kube-proxy不是必须为该虚拟IP工作而运行,并且节点会看到来自未更改的客户端IP地址的流量。当流量通过节点端口或负载均衡器进入时,尽管在这种情况下,客户端IP发生更改,也会执行相同的基本流程。
IPVS模式,专为负载均衡设计,并基于内核中的哈希表。在大规模集群中,iptables操作会显着降低速度时。可以通过基于IPVS的kube-proxy在大量服务中实现性能一致性。 同时,基于IPVS的kube-proxy具有更复杂的负载均衡算法。
六、服务发现
Kubernetes支持2种基本的服务发现模式——环境变量和DNS。
1.环境变量
当Pod运行在 Node 上,kubelet会为每个活跃的Service添加一组环境变量。它同时支持Docker links兼容变量、简单的{SVCNAME}_SERVICE_HOST和{SVCNAME}_SERVICE_PORT变量,这里Service的名称需大写,横线被转换成下划线。举个例子,一个名为redis-master的Service暴露了TCP端口6379,同时给它分配了Cluster IP地址10.0.0.11,这个Service生成了如下环境变量:
REDIS_MASTER_SERVICE_HOST=10.0.0.11
REDIS_MASTER_SERVICE_PORT=6379
REDIS_MASTER_PORT=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
REDIS_MASTER_PORT_6379_TCP_PORT=6379
REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.11
注意:当有需要访问服务的Pod时,并且正在使用环境变量方法将端口和群集IP发布到客户端Pod时,必须在客户端Pod出现之前创建服务。 否则,这些客户端Pod将不会设定其环境变量。如果仅使用DNS查找服务的群集IP,则无需担心此设定问题。
2.DNS
可以使用附加组件为Kubernetes集群设置DNS服务。支持群集的DNS服务器(例如CoreDNS)监视Kubernetes API中的新服务,并为每个服务创建一组DNS记录。如果在整个群集中都启用了DNS,则所有Pod都应该能够通过其DNS名称自动解析服务。例如,如果在 Kubernetes命名空间my-ns中有一个名为my-service"的服务,则控制平面和DNS服务共同为my-service.my-ns创建DNS记录。my-ns命名空间中的Pod应该能够通过简单地对my-service进行名称查找来找到它( my-service.my-ns 也可以)。其他命名空间中的Pod必须将名称限定为my-service.my-ns。这些名称将解析为为服务分配的群集IP。
Kubernetes还支持命名端口的DNS SRV(服务)记录。如果my-service.my-ns服务具有名为http的端口,且协议设置为TCP,则可以对_http._tcp.my-service.my-ns执行DNS SRV查询查询以发现该端口号,http以及IP地址。Kubernetes DNS服务器是唯一的一种能够访问ExternalName类型的Service的方式。
七、发布Service和Service类型
对于应用的某些部分,比如前端,可能希望暴露一个服务到Kubernetes集群外部的一个外部IP地址上。Kubernetes的ServiceTypes允许指定Service的类型,Service有