һ��Redis���
1.ʲô��Redis
Redis��һ��ʹ��C���Կ��������ݿ�,�봫ͳ���ݿⲻͬ����Redis�����ݴ����ڴ��� ,���ڴ����ݿ�,���Զ�д�ٶȷdz���,���Redis���㷺Ӧ���ڻ��档����,redisҲ�����������ֲ�ʽ������Ϣ���С�redis�ṩ�˶�������������֧�ֲ�ͬ��ҵ����redis��֧�����־û���LUA�ű���LRU�����¼������ּ�Ⱥ������
2.ΪʲôҪ��Redis(����)
�û����Ŀ����Ҫ��Ϊ�˸����߲ܺ���:
- ������:ֱ�ӷ������ݿ��е�����,������̱Ƚ���,��Ϊ�Ǵ�Ӳ�̶�ȡ,�������ʵ����ݴ浽������,��һ���ٷ�����Щ���ݵ�ʱ��Ϳ���ֱ�Ӵӻ����л�ȡ�ˡ������������ֱ�Ӳ����ڴ�,�����ٶ��൱�졣������ݿ��еĶ�Ӧ���ݸı��֮��,ͬ���ı仺������Ӧ�����ݼ��ɡ�
- �߲���:ֱ�Ӳ��������ܹ����ܵ�������ԶԶ����ֱ�ӷ������ݿ��,�������ݿ��еIJ�������ת�Ƶ�������ȥ,�����û���һ���������ֱ�ӵ�������������þ������ݿ�,Ҳ�������ϵͳ����IJ�����
3.Ϊʲô��Redis������map/guava������
�����Ϊ���ػ���ͷֲ�ʽ���档��JavaΪ��,ʹ���Դ���map����guavaʵ�ֵ��DZ��ػ���,����Ҫ���ص��������Լ�����,������������jvm�����ٶ�����,�����ڶ�ʵ���������,ÿ��ʵ������Ҫ���Ա���һ�ݻ���,���治����һ���ԡ�
ʹ��redis��memcached֮��ij�Ϊ�ֲ�ʽ����,�ڶ�ʵ���������,��ʵ������һ�ݻ�������,�������һ���ԡ�ȱ������Ҫ����redis��memcached����ĸ߿���,��������ܹ��Ͻ�Ϊ���ӡ�
����Redis��Memcached��ͬ
�ֲ�ʽ����ʹ�õıȽ϶����Ҫ��Memcached��Redis,�������ڻ����϶���Redis��ʵ�ֻ��档
1.��ͬ��
- ���ǻ����ڴ�����ݿ�,һ�㶼������������ʹ�á�
- ���й��ڲ��ԡ�
- ���ߵ����ܶ��dz��ߡ�
2.����
- ��������:Redis����֧�ּ�k/v(string)���͵�����,ͬʱ��֧��list,set,sorted set,hash����������;��Memcachedֻ֧�ּ���������(�ı��͡�����������)��
- �־û�:Redis���Խ��ڴ��е����ݱ����ڴ�����,������ʱ������ٴμ��ؽ���ʹ��,֧��RDB��AOF���ֳ־û���ʽ;��Memecacheֻ�ܰ�����ȫ�������ڴ���,��֧�ֳ־û���
- ���ѻָ�:Redis�����ѻָ�����,����ΪRedis֧�����ݳ־û�;Memcachedû�����ѻָ����ơ�
- �ڴ����:Redis�ڷ������ڴ�ʹ����֮��,���Խ����õ����ݷŵ�������;Memcached�ڷ������ڴ�ʹ����֮��,��ֱ�ӱ��쳣���ڴ滹û����ʱRedisҲ���Խ��ܾ�û�õ����ݽ���������;Memcached���������ڴ����ڴ�,Memcached���ڴ�ָ���ض����ȵĿ����洢����,����ȫ����ڴ���Ƭ������,�������ַ�ʽ��ʹ���ڴ�������ʲ��ߡ�
- ��Ⱥģʽ:Redisԭ??��clusterģʽ,����ʵ�����Ӹ���,��д����;memcachedû��ԭ���ļ�Ⱥģʽ,��Ҫ�����ͻ�����ʵ������Ⱥ�з�Ƭд�����ݡ�
- �߳�ģ��:Redisʹ�õ��̵߳Ķ�·IO����ģ��(Redis6.0�����˶��߳�IO);Memcached�Ƕ��߳�,������IO���õ�����ģ�͡�
- ���ӹ���:Redis֧�ַ�������ģ�͡����ӷ��������л���Lua�ű�������ȹ���;��Memcached��֧�֡�����Redis֧�ָ���ı�����ԡ�
- �������ݵ�ɾ������:Redisͬʱʹ�ö���ɾ���붨��ɾ��;��Memcachedֻ���˶���ɾ����
- �¼���:Redisʹ���Է�װ�����¼���AeEvent;��Memcachedʹ�ù���Ѫͳ��LibEvent�¼��⡣
- ��ѯ����:Redis֧����������,����,��ͬ�����в�ͬ��CRUD;Memcachedֻ֧�ֳ��õ�CRUD�������������
- ���ó���:Redis�����ڴ洢�������ݽṹ,��Ҫ�־û��߿��õij���,value�洢����Ҳ�ϴ�;Memcached�����ڴ洢��k/v����,�������dz���,�������dz��ߵij�����
����Redis�����������ͼ�ʹ�ó���
Redis�����Ǽ�key-value�洢,ʵ��������һ�����ݽṹ������,���м������ַ���,ֵ֧�ֶ��ֲ�ͬ����(��5�ֻ�������),��ͬ�������ݽṹ�IJ��������ֵ�Ľṹ��һ����
1.��������
Redis��5�ֻ�����������:
- string(�ַ���):��Redis�����������,һ�����ļ�ֵ�Ի��档
- ����������:
SET key value:Ϊkey���ñ���һ���ַ���ֵvalue�����key�Ѿ�������һ��ֵ,��ô�ò�����ֱ�Ӹ���ԭ����ֵ,���Һ���ԭʼ���͡���set����ִ�гɹ�֮��,֮ǰ���õĹ���ʱ�䶼��ʧЧ��GET key:��ȡkey��Ӧ��ֵ�����key������,��������ֵnil,���key��ֵ�����ַ���,�ͷ��ش���STRLEN key:����key��������ַ���ֵ�ij��ȡ���key������Ƿ��ַ���ֵʱ�����ش���APPEND key value:�����key�Ѵ��ڲ�������ֵ��һ���ַ���,����value�ӵ��ַ���ĩβ�����key������,��ᴴ�������Ƚ���ֵ��Ϊ���ַ�����ִ���Ӳ�����INCR key:��key�д��������ֵ��1��DECR key:��key�д��������ֵ��1��MSET key value [key value ��]:ͬʱΪ���������ֵ��MGET key [key ��]:���ظ�����һ�������ַ�������ֵ��
- list(�б�):������,������һ�ַdz����������ݽṹ,����Ԫ�صIJ����ɾ���dz��첢�ҿ�����������������,��������������ѡ�Redis��list��ʵ��Ϊһ��˫������,����֧�ַ�����Һͱ���,���������˲��ֶ�����ڴ濪��������ͨ��list�洢һЩ�б��͵����ݽṹ,�����˿�б��ȡ�
- ����������:
LPUSH key value [value ��]:������ָ����ֵ����洢��key���б��Ŀ�ͷ(�����,���ж��ֵ���������β���)��RPUSH key value [value ��]:������ָ����ֵ����洢��key���б���ĩβ(���ұ�)��LPOP key:ɾ�������ش洢��key���б��еĵ�һ��Ԫ�ء�RPOP key:ɾ�������ش洢��key���б��е����һ��Ԫ�ء�LRANGE key start stop:���ش洢��key���б���ָ����Χ��Ԫ�ء� ƫ����start��stop�ǻ����㿪ʼ��������LINDEX key index:���ش洢��key���б�������index����Ԫ�ء��������㿪ʼ,������������ָ�����б�ĩβ��ʼ��Ԫ�ء�LLEN key:���ش洢��key���б��ij��ȡ����key������,�������Ϊ���б�������0, ���洢��key��ֵ�����б�ʱ�����ش���
- hash(��ϣ):������JDK1.8ǰ��HashMap,�ڲ�ʵ��Ҳ���,����,Redis��hash���˸����Ż���hash��һ��string���͵�field��value��ӳ���,�ʺ����ڴ洢�ṹ��������,�������(ǰ�����������ûǶ�������Ķ���),������д����ʱ���Բ���hash�ṹ��ĵ����ֶ�,��hash�ṹ�Ĵ洢����ҲҪ���ڵ����ַ�����
- ����������:
HSET key field value [field value ...]:���洢��key���Ĺ�ϣ���е�field��ֵ����Ϊvalue��HGET key field:���ش洢��key���Ĺ�ϣ����field��ֵ��HEXISTS key field:�鿴�洢��key���Ĺ�ϣ���е�field�Ƿ���ڡ�HGETALL key:���ش洢��key���Ĺ�ϣ���������ֶκ�ֵ��HKEYS key:���ش洢��key���Ĺ�ϣ���е������ֶ����ơ�HVALS key:���ش洢��key���Ĺ�ϣ���е�����ֵ��HLEN key:�ش洢��key���Ĺ�ϣ���а������ֶ�����HDEL key field [field ...]:�Ӵ洢��key���Ĺ�ϣ����ɾ��ָ�����ֶΡ�
- set(����):������Java�е�HashSet ,����Ψһ������set��������ʵ�ֽ�������������IJ����� ��������Ҫ��ŵIJ��ظ������Լ���ȡ�������Դ�����Ͳ����ȳ�����
- ����������:
SADD key member [member ...]:��ָ��Ԫ�����ӵ��洢��key�ļ�����,��ָ��Ԫ���ڸü��ϴ��ڽ������ԡ�SPOP key [count]:�Ӵ洢��key�ļ�����ɾ��������һ���������Ԫ�ء�SMEMBERS key:���ش洢��key�ļ����е�����Ԫ�ء�SCARD key:���ش洢��key�ļ��ϵ�Ԫ��������SISMEMBER key member:���member�Ƿ�洢��key�ļ����е�Ԫ�ء�SINTER key [key ...]:�������и������ϵĽ��������ļ���Ԫ�ء�SINTERSTORE destination key [key ...]:��������SINTER����,������������ֱ�ӷ��ؽ����,���ǽ����������destination������,���destination���ϴ���,��ᱻ���ǡ�SREM key member [member ...]:�ڴ洢��key�ļ������Ƴ�ָ����Ԫ�ء�ָ��Ԫ�ز��Ǽ���Ԫ�ؽ�������,���ϲ����ڻ᷵��0,key�����Ͳ��Ǽ��ϻ᷵�ش���SUNION key [key ...]:�������и������ϵIJ��������ļ���Ԫ�ء�SUNIONSTORE destination key [key ...]:��������SUNION����,������������ֱ�ӷ��ؽ����,���ǽ����������destination������,���destination���ϴ���,��ᱻ���ǡ�
- sorted set(����):��set���,sorted set������һ��Ȩ�ز���score,ʹ�ü����е�Ԫ���ܹ���score������������,������ͨ��score�ķ�Χ����ȡԪ�ص��б���������Java��TreeSet��HashMap�Ľ���塣��������Ҫ����ij��Ȩ�ض���������ij���,����ֱ�����������а�ȡ�
- ����������:
ZADD key score member [score member ...]:��������ָ����score��ָ��Ԫ�ص��洢��key�������С����ָ��Ԫ���Ѿ���������Ԫ��,����score������ȷ��λ�����²���Ԫ��,��ȷ����ȷ�������key������,��ᴴ��һ����ָ��Ԫ��ΪΨһԪ�ص������� ��������ڵ�����������,�ش���ZCARD key:���ش洢��key������Ԫ��������ZRANGE key min max:���ش洢��key�������е�ָ����Χ��Ԫ�ء�ZRANK key member:���ش洢��key�������е�Ԫ��member������,��������Ԫ�ذ�score�ӵ͵�������,scoreֵ��С��Ԫ������Ϊ0��ZREM key member [member ...]:�Ӵ洢��key��������ɾ��ָ����Ԫ�ء� �����ڵ�Ԫ�ؽ�������,��key�����Ҳ���������ʱ�����ش���ZSCORE key member:���ش洢��key�������е�Ԫ��member��score�����Ԫ�ز������������л���key������,��nil��
2.ʹ�ó���
�Ƚϳ����ļ���ʹ�ó�������:
- ������:���Զ�string���������Լ�����,�Ӷ�ʵ�ּ��������ܡ�Redis�����ڴ������ݿ�Ķ�д���ܷdz���,���ʺϴ洢Ƶ����д�ļ�������
- ����:���ȵ����ݷŵ��ڴ���,�����ڴ�����ʹ�����Լ���̭��������֤����������ʡ�
- ���ұ�:���ұ��ͻ�������,Ҳ��������Redis���ٵIJ������ԡ����Dz��ұ������ݲ���ʧЧ,����������ݿ���ʧЧ,��Ϊ���治��Ϊ�ɿ���������Դ������DNS��¼�ͺ��ʺ�ʹ��Redis���д洢��
- ��Ϣ����:List��һ��˫������,����ͨ��
lpush��rpopд��Ͷ�ȡ��Ϣ���������ʹ��Kafka��RabbitMQ����Ϣ�м���� - �Ự����:����ʹ�� Redis ��ͳһ�洢��̨Ӧ�÷������ĻỰ��Ϣ����Ӧ�÷��������ٴ洢�û��ĻỰ��Ϣ,Ҳ�Ͳ��پ���״̬,һ���û�������������һ��Ӧ�÷�����,�Ӷ�������ʵ�ָ߿������Լ��������ԡ�
- �ֲ�ʽ��:�ڷֲ�ʽ������,��ʹ�õ��������µ������Զ���ڵ��ϵĽ��̽���ͬ��������ʹ��Redis�Դ���
SETNX����ʵ�ֲַ�ʽ��,����֮��,������ʹ�ùٷ��ṩ��RedLock�ֲ�ʽ��ʵ�֡� - ����:set����ʵ�ֽ����������Ȳ���,�Ӷ�ʵ�ֹ�ͬ��ע�ȹ��ܡ�sorted set����ʵ�������Բ���,�Ӷ�ʵ�����а�ȹ��ܡ�
�ġ�Redis���߳�ģ��
1.�ļ��¼�������
Redis����Reactorģʽ�������Լ��������¼�������,�������������Ϊ�ļ��¼�������(file event handler)�������ļ��¼����������Ե��̷߳�ʽ���е�,���Բ�˵Redis�ǵ��߳�ģ�͡�����?IO��·��?����ͬʱ�������socket,����socket�ϵ��¼�
��ѡ���Ӧ���¼���������?������
- �ļ��¼���������?IO��·��?����ͬʱ�������socket,������socketĿǰִ�е�������Ϊ���ֹ�����ͬ���¼���������
- ������������������ִ������Ӧ��(accept)����ȡ(read)��д��(write)���ر�(close)�Ȳ���ʱ,��������Ӧ���ļ��¼��ͻ����,��ʱ�ļ��¼��������ͻ��������֮ǰ�����õ��¼���������������Щ�¼���
��Ȼ�ļ��¼��������Ե��̷߳�ʽ����,��ͨ��ʹ��I/O��·���ó������������socket,�ļ��¼���������ʵ���˸����ܵ�����ͨ��ģ��,�ֿ��Ժܺõ���Redis������������ͬ���Ե��̷߳�ʽ���е�ģ����жԽ�,�Ᵽ����Redis�ڲ����߳���Ƶļ��ԡ�����Redis����Ҫ���ⴴ��������߳��������ͻ��˵Ĵ�������,��������Դ�����ġ�
2.�ļ��¼��������Ĺ���
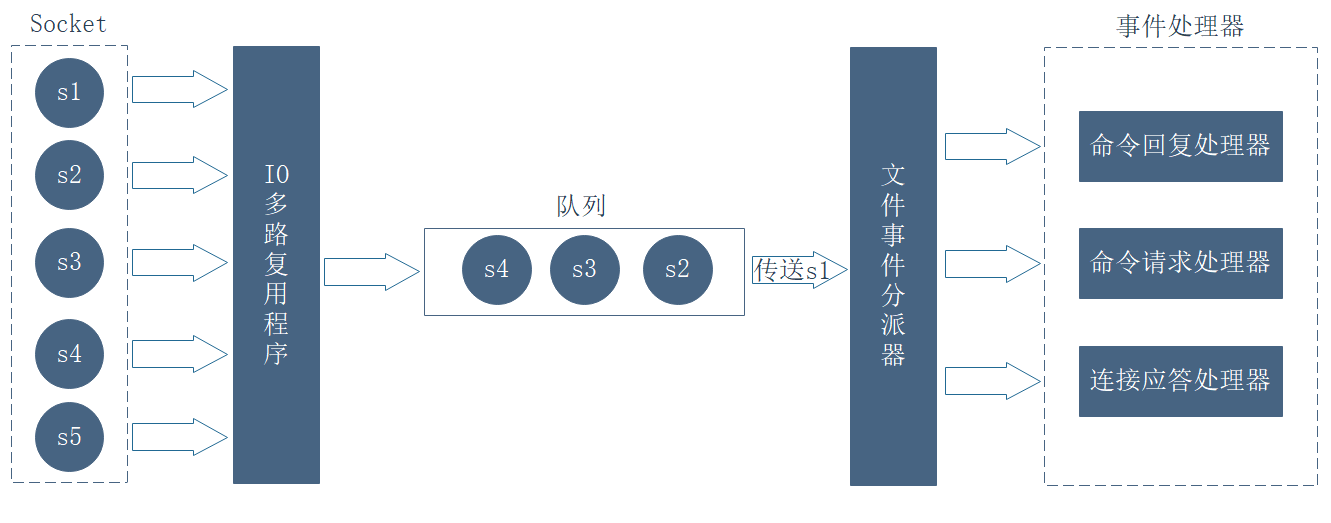
�ļ��¼�����������4����ɲ���:
- socket
- IO��·���ó���
- �ļ��¼�������
- �¼�������(����Ӧ��������������������������ظ�������)
�ļ��¼��Ƕ����ֲ����ij���,��һ��������ִ������Ӧ�𡢶�ȡ��д�롢�رյȲ���ʱ,�����һ���������Ӧ���ļ��¼���һ��������ͨ�������Ӷ������,���Զ���ļ��¼����ܲ������֡���IO��·���ó���Ḻ������������,�������Բ����¼������ֶ��ŵ�һ��������,Ȼ��ͨ���ö���,������ͬ����ÿ��һ�����ֵķ�ʽ�����ִ����ļ��¼�������,����һ�����ֲ������¼����������֮��(������Ϊ�¼����������¼�������ִ�����),I/O��·���ó���Ż�������ļ��¼�������������һ�����֡��ļ��¼�����������I/O��·���ó�����������,���������ֲ������¼����͵�����Ӧ���¼����������д������ļ��¼�����������ɲ��ּ�����ԭ������ͼ:
3.�¼�����
I/O��·���ó�����Լ���������ֵ�ae.h/AE_READABIE�¼���ae.h/AE_WRITABLE�¼���
AE_READABIE�¼�:�����ֱ�ÿɶ�ʱ(�ͻ��˶�����ִ��write��close����),�������µĿ�Ӧ�����ֳ���ʱ(�ͻ��˶Է������ļ�������ִ��connect����),���ֲ���AE_READABLE�¼���AE_WRITABLE�¼�:�����ֱ�ÿ�дʱ(�ͻ��˶�����ִ��read����),���ֲ���AE_WRITABLE�¼���
I/O��·���ó�������������ͬʱ�������ֵ�AE_READABLE�¼���AE_WRITABLE�¼�,���һ������ͬʱ�������������¼�,��ô�ļ��¼������������ȴ���AE_READABLE�¼�,�ȵ�AE_READABLE�¼�������֮��,�Ŵ���AE_WRITABLE�¼�����һ�������ֿɶ��ֿ�д,���������ȶ�����,��д���֡�
4.�¼�������
�¼�����������õľ�����ͻ��˽���ͨ�ŵ�����Ӧ��������������������������ظ���������
- ����Ӧ������:Ϊ
networking.c/acceptTcpHandler����,���ڶ����ӷ������������ֵĿͻ��˽���Ӧ�𡣵�Redis���������г�ʼ��ʱ,����Ὣ����Ӧ�������ͷ������������ֵ�AE_READABLE�¼�����,���пͻ������ӷ������������ֵ�ʱ��,���־ͻ����AE_READABLE�¼�,��������Ӧ������ִ��,��ִ����Ӧ������Ӧ������� - ������������:Ϊ
networking.c/readQueryFromClient����,����������ж���ͻ��˷��͵������������ݡ���һ���ͻ���ͨ������Ӧ�������ɹ����ӵ�������֮��,�������Ὣ�ͻ������ֵ�AE_READABLE�¼�������������������,���ͻ�����������������������ʱ��,���־ͻ����AE_READABLE�¼�,����������������ִ��,��ִ����Ӧ�����ֶ�������� - ����ظ�������:Ϊ
networking.c/sendReplyToClient����,��������ִ�������õ�������ظ�ͨ�����ַ��ظ��ͻ��ˡ���������������ظ���Ҫ�����ͻ���ʱ,�������Ὣ�ͻ������ֵ�AE_WRITABLE�¼�������ظ�����������,���ͻ������ý��շ��������ص�����ظ�ʱ,�ͻ����AE_WRITABLE�¼�,��������ظ�������ִ��,��ִ����Ӧ������д�������������ظ�������Ϻ�,�������ͻ�������ظ���������ͻ������ֵ�AE_WRITABLE�¼�֮��Ĺ�����
5.�ͻ�����Redis��һ��ͨ������
��ͼ�ǿͻ�����Redis��һ��ͨ������ʾ��ͼ:
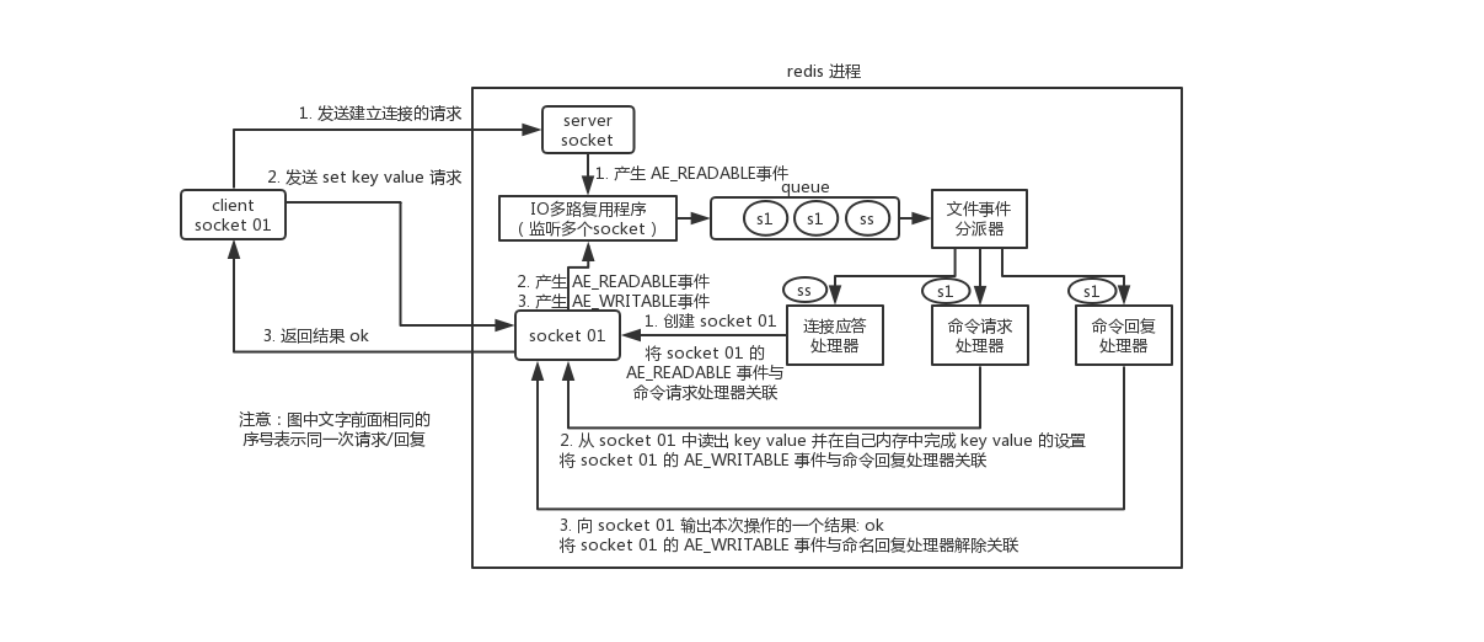
�ͻ�����Redis��һ��ͨ����������:
- Redis����˽��̳�ʼ����ʱ��,�Ὣ��������������(server socket)��
AE_READABLE�¼�������Ӧ������������ - �ͻ�����Redis�ķ�����������������������,�������������ֻ����
AE_READABLE�¼��� - IO��·���ó���������������������ֲ�����
AE_READABLE�¼���,��������ѹ�������,Ȼ��ͨ���ö��н������ִ����ļ��¼��������� - �ļ��¼�����������I/O��·���ó������ķ�������������,����������ֵ�
AE_READABLE�¼�����������Ӧ���������д����� - ����Ӧ�������ᴴ��һ������ͻ���ͨ�ŵĿͻ�������(socket01),���������ֵ�
AE_READABLE�¼��������������������� - �ͻ�����redis����һ����������,��ʱ�ͻ������ֻ����
AE_READABLE�¼��� - IO��·���ó���������ͻ������ֲ�����
AE_READABLE�¼���,��������ѹ�������,Ȼ��ͨ���ö��н������ִ����ļ��¼��������� - �ļ��¼�����������I/O��·���ó������Ŀͻ�������,����������ֵ�
AE_READABLE�¼����������������������д����� - ��������������ȡ�ͻ��˵���������,Ȼ����س���ȥִ�С�
- Ϊ�˽�ִ���������������ظ����ؿͻ���,�������Ὣ�ͻ������ֵ�
AE_WRITABLE�¼�������ظ������������� - ���ͻ������ý�������ظ�ʱ,�ͻ������ֽ�����
AE_WRITABLE�¼��� - IO��·���ó���������ͻ������ֲ�����
AE_WRITABLE�¼���,��������ѹ�������,Ȼ��ͨ���ö��н������ִ����ļ��¼��������� - �ļ��¼�����������I/O��·���ó������Ŀͻ�������,����������ֵ�
AE_WRITABLE�¼�����������ظ����������д����� - ����ظ�������������ظ�ȫ��д�뵽�ͻ������֡�
- ����������ͻ������ֵ�
AE_WRITABLE�¼�������ظ�������֮��Ĺ�����
6.Redis���߳�ģ��Ч�ʸߵ�ԭ��
- ���ڴ������
- �����ǻ��ڷ�������IO��·���û��ơ�
- C����ʵ��,һ��C����ʵ�ֵij����롱����ϵͳ����,ִ���ٶ���Ի���졣
- ���̷߳��������˶��̵߳�Ƶ���������л������������������,Ԥ���˶��߳̿��ܲ����ľ������⡣
7.Redis6.0��ʼ������߳�
Redis6.0֮ǰΪʲô��ʹ�ö��߳�:
- ���̱߳�����ײ��Ҹ�����ά����
- Redis������ƿ������CPU,��Ҫ���ڴ�����硣
- ���߳̾ͻ�����������߳��������л�������,������Ӱ�����ܡ�
Redis6.0֮��Ϊ��������߳�:
Redis6.0������߳���Ҫ��Ϊ���������IO��д����,����������д���ɶ��̵߳ķ�ʽ�����ܻ��кܴ���������ȻRedis6.0�����˶��߳�,����Redis�Ķ��߳�ֻ�����������������ݵĶ�д�������ʱ�IJ���,ִ��������Ȼ�ǵ��̡߳�
�塢���ݿ���ռ�
Redis��һ����ֵ�����ݿ������,�������е�ÿ�����ݿⶼ��һ��redis.h/redisDb�ṹ��ʾ,����,redisDb�ṹ��dict�ֵ䱻��Ϊ���ռ�(key space),�����������ݿ��е����м�ֵ�ԡ�
typedef struct redisDb {
...
dict *dict;
...
} redisDb;
���ռ�ļ�Ҳ�������ݿ�ļ�,ÿ��������һ��string����;���ռ��ֵҲ�������ݿ��ֵ,ÿ��ֵ������string����list����hash����set�����sorted set�����е�����һ��Redis����һ�����ݿ���ռ��ʾ��ͼ����:
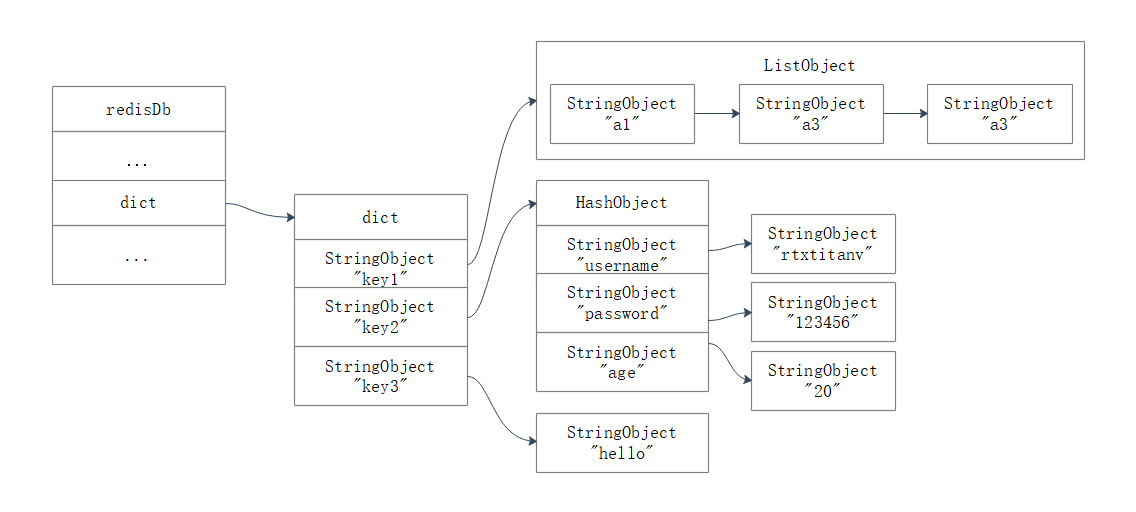
��Ϊ���ݿ�ļ��ռ���һ���ֵ�,��������������ݿ�IJ���,ʵ���϶���ͨ���Լ��ռ��ֵ���в�����ʵ�ֵġ����ֳ��������ݿ����ʵ��ԭ������:
- ���Ӽ�:ʵ���ǽ��¼�ֵ�����ӵ����ռ���,���м�Ϊstring����,ֵΪ����һ��Redis����
- ɾ����:ʵ�����ڼ��ռ�ɾ������Ӧ�ļ�ֵ�Զ���
- ���¼�:ʵ���ǶԼ��ռ������Ӧ��ֵ������и��¡�
- �Լ�ȡֵ:ʵ�����ڼ��ռ���ȡ������Ӧ��ֵ����
�ڶ����ݿ���ж�д,������Լ��ռ�ִ��ָ���Ķ�д����,����ִ��һЩ�����ά������:
- �ڶ�ȡһ����֮��(����д������Ҫ�Լ����ж�ȡ),����������ݼ��Ƿ���������·������ļ��ռ�����(hit)��������ռ䲻����(miss)����,������ֵ������
INFO stats�����keyspace_hits���Ժ�keyspace_misses�����в鿴�� - �ڶ�ȡһ����֮��,����������¼���LRU(���һ��ʹ��)ʱ��,���ֵ�������ڼ����������ʱ��,ʹ��
OBJECTidletime <key>������Բ鿴��������ʱ�䡣 - �ڶ�ȡһ����ʱ���ָü��ѹ���,����ɾ��������ڼ��ٽ������²�����
- ����пͻ���ʹ��
WATCH���������ij����,��ô���������ı����ӵļ�֮��,�Ὣ��������Ϊ��(dirty),�Ӷ����������ע�������Ѿ����Ĺ��� - ������ÿ����һ����֮��,�������(dirty)����������ֵ��1,����������ᴥ���������ij־û��Լ����Ʋ�����������������������ݿ�֪ͨ����,��ô�ڶԼ�������֮��,�������������÷�����Ӧ�����ݿ�֪ͨ��
�������ü��Ĺ���ʱ�������ʱ��
��Redis��ͨ��EXPIRE��EXPIREAT��PEXPIRE��PEXPIREAT����������ü��Ĺ���ʱ��(��ʲôʱ��ᱻɾ��)������ʱ��(�����Դ��ڶ��),��������ʱ���,���ᱻ�Զ�ɾ����
ע��:SETEX�������������һ���ַ�������ͬʱΪ�����ù���ʱ��,����һ��������������,ֻ�������ַ�����,��SETEX�������ù���ʱ���ԭ����EXPIRE������ȫһ����
���ù���ʱ�������:
- ���ù���ʱ�������ڻ�����ڴ������,��Ϊ�ڴ�����,��������ù���ʱ��,�������ڴ������
- ���ù���ʱ����Խ���ijЩҵ��ĸ��ӳ̶�,������֤��ֻ��Ҫ��һ��������Ч,����ô�ͳ���ݿ��һ����Ҫ�Լ��ж��Ƿ����,������ҵ��ĸ��ӶȲ������ܲ��ߡ�
1.���ù���ʱ��(����ʱ��)
EXPIRE key seconds
��ʼ�汾:1.0.0
ʱ�临�Ӷ�:O(1)
��key���ù���ʱ��,��������ʱ���,���ᱻ�Զ�ɾ�������Ѿ��й���ʱ���keyִ��EXPIRE����,����������Ĺ���ʱ�䡣������ù���ʱ��ɹ�,��1,���key������,��0��
ע��:
- ����ʱ��ֻ��ͨ��ɾ���ǵ�key�����ݵ����������,��Щ�������
DEL,SET,GETSET�����е�*STORE�������ζ�������ڸ������Ĵ洢�ڼ��ϵ�ֵ�������¼��滻�IJ����������ֹ���ʱ�䲻�䡣 - ����ʹ��
PERSIST�����������ʱ��,ʹkey���һ�����õ�key�� - ���ʹ��
RENAME������������key,����صĹ�������ʱ�佫ת�Ƶ���key�ϡ�����ԭ������key_A,ʹ��RENAME Key_B Key_A����,�ɵ�key_A��ֵ��������,���Ҳ���ԭ��Key_A�����õĻ����й���ʱ���,���ᱻKey_B����Ч��״̬���ǡ� - ��Redis 2.1.3֮ǰ�İ汾��,ʹ����key��ֵ�������ľ��й���ʱ���key��ֵ��ɾ������key,��һ��Ϊ���ܵ�ʱ����(replication)������ƶ�������,������һ�����Ѿ�������
EXPIREAT key timestamp
��ʼ�汾:1.2.0
ʱ�临�Ӷ�:O(1)
EXPIREAT�����ú�������EXPIRE����,������û��ָ����ʾTTL(����ʱ��)������,����ʹ���˾��Ե�Unixʱ���(��1970��1��1������������)�������ڹ�ȥ��ʱ���������ɾ��key��������ù���ʱ��ɹ�,��1,���key������,��0������EXPIREAT��Ϊ�˽�AOF�־���ģʽ����Գ�ʱת��Ϊ���Գ�ʱ,������ֱ������ָ������keyδ����ij������ʱ�䵽�ڡ�
PEXPIRE key milliseconds
��ʼ�汾:2.6.0
ʱ�临�Ӷ�:O(1)
������Ĺ���ԭ����EXPIRE��ȫ��ͬ,����key������ʱ���Ժ���Ϊ��λ�������롣������ù���ʱ��ɹ�,��1,���key������,��0��
PEXPIREAT key milliseconds-timestamp
��ʼ�汾:2.6.0
ʱ�临�Ӷ�:O(1)
PEXPIREAT�����ú�������EXPIREAT����,�����Ժ���Ϊ��λ����key�Ĺ���unixʱ���,����������Ϊ��λ��������ù���ʱ��ɹ�,��1,���key������,��0��
��Ȼ�⼸�������Բ�ͬ��λ�Ͳ�ͬ��ʽ�����ù���ʱ��,��ʵ����EXPIRE��PEXPIRE��EXPIREAT���������ʹ��PEXPIREAT������ʵ�ֵ�:���ۿͻ���ִ�е��������ĸ������е���һ��,����ת��֮��,���յ�ִ��Ч������ִ��PEXPIREAT����һ��,�����ն���ת����PEXPIREATִ�С��⼸�������ת������,EXPIRE----->PEXPIRE----->PEXPIREAT<-----EXPIREAT��
2.�������ʱ��
Redisͨ�������ֵ伴redisDb�ṹ��expires�ֵ����������ݿ������м��Ĺ���ʱ�䡣�����ֵ�ļ���һ��ָ��,ָ����ռ��е�ij��������(���ݿ��),�����ֵ��ֵ��һ��long long���͵�����,������������˼���ָ������ݿ���Ĺ���ʱ�䡪��һ�����뾫�ȵ�UNIXʱ�����
typedef struct redisDb {
...
dict *dict;
dict *expires
...
} redisDb;
һ�����й����ֵ��ʾ��ͼ����:
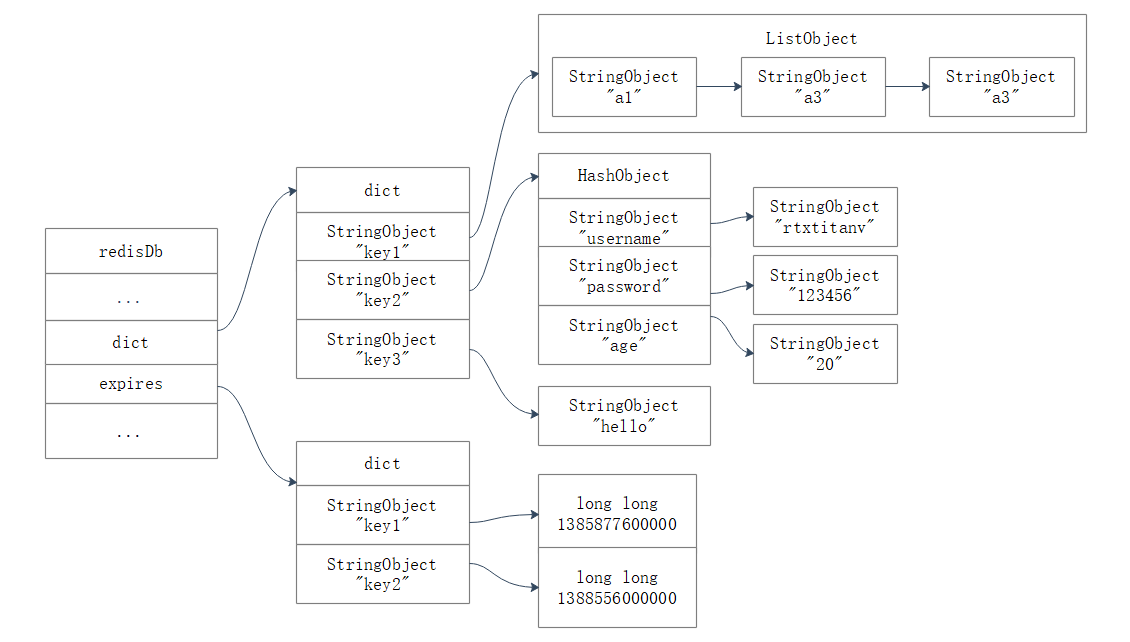
ע��:ͼ�м��ռ�����ֵ����ظ����������μ�������ʵ����,���ռ�ļ������ֵ�ļ���ָ��ͬһ��������,���Բ�������κ��ظ�����,Ҳ�����˷��κοռ䡣
��ִ��PEXPIREAT��������������ת����PEXPIREAT������Ϊһ�����ݿ�����ù���ʱ��ʱ,�������������ݿ�Ĺ����ֵ��й������������ݿ������ʱ�䡣ͨ�������ֵ�,Redis�����ж��������Ƿ����,���ȼ��������Ƿ�����ڹ����ֵ�,�������,ȡ�ü��Ĺ���ʱ��,Ȼ���鵱ǰUNIXʱ����Ƿ���ڼ��Ĺ���ʱ��,��������ѹ���,����,��δ���ڡ�
3.�Ƴ�����ʱ��
PERSIST key
��ʼ�汾:2.2.0
ʱ�临�Ӷ�:O(1)
�Ƴ�����key�Ĺ���ʱ��,�����key�ӡ���ʧ�ġ�(�����й���ʱ���key)ת���ɡ��־õġ�(��������ʱ�䡢�������ڵ�key)������Ƴ�����ʱ��ɹ�,��1,���key�����ڻ�û�����ù���ʱ��,��0��
PERSIST�������PEXPIREAT����ķ�����:PERSIST�����ڹ����ֵ��в��Ҹ����ļ�,���������ֵ(����ʱ��)�ڹ����ֵ��еĹ�����
4.����ʣ������ʱ��
TTL key
��ʼ�汾:1.0.0
ʱ�临�Ӷ�:O(1)
����Ϊ��λ���ؾ��й���ʱ���key��ʣ������ʱ�䡣��Redis 2.6��֮ǰ�汾,���key�����ڻ���key���ڵ�δ���ù���ʱ��ʱ����-1��
��Redis2.8��ʼ,key�����ڷ���-2,key���ڵ�δ���ù���ʱ�䷵��-1��
PTTL key
��ʼ�汾:2.6.0
ʱ�临�Ӷ�:O(1)
�Ժ���Ϊ��λ���ؾ��й���ʱ���key��ʣ������ʱ�䡣��Redis 2.6��֮ǰ�汾,���key�����ڻ���key���ڵ�δ���ù���ʱ��ʱ����-1����Redis2.8��ʼ,key�����ڷ���-2,key���ڵ�δ���ù���ʱ�䷵��-1��
TTL��PTTL���������ͨ��������Ĺ���ʱ��(���ᱻɾ����ʱ��)�͵�ǰʱ��֮��IJ���ʵ�ֵġ�
�ߡ�Redis�Ĺ��ڲ���
һ����������,��ʲôʱ��ᱻɾ��ȡ���ڹ��ڼ���ɾ������,�����ڼ���ɾ����������������: