13.1 ЭМЛљБОНщЩм
13.1.1 ЮЊЪВУДвЊгаЭМ
- ЧАУцЮвУЧбЇСЫЯпадБэКЭЪї
- ЯпадБэОжЯогквЛИіжБНгЧАЧ§КЭвЛИіжБНгКѓМЬЕФЙиЯЕ
- ЪївВжЛФмгавЛИіжБНгЧАЧ§вВОЭЪЧИИНкЕу
- ЕБЮвУЧашвЊБэЪОЖрЖдЖрЕФЙиЯЕЪБ, етРяЮвУЧОЭгУЕНСЫЭМЁЃ
13.1.2 ЭМЕФОйР§ЫЕУї
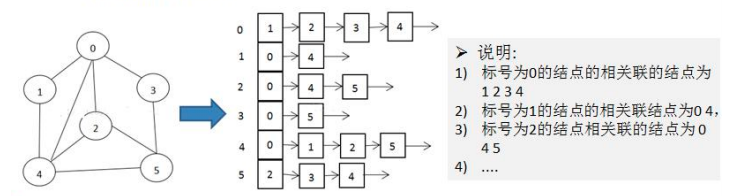
ЭМЪЧвЛжжЪ§ОнНсЙЙ,ЦфжаНсЕуПЩвдОпгаСуИіЛђЖрИіЯрСкдЊЫиЁЃСНИіНсЕужЎМфЕФСЌНгГЦЮЊБпЁЃ НсЕувВПЩвдГЦЮЊЖЅЕуЁЃШчЭМ:
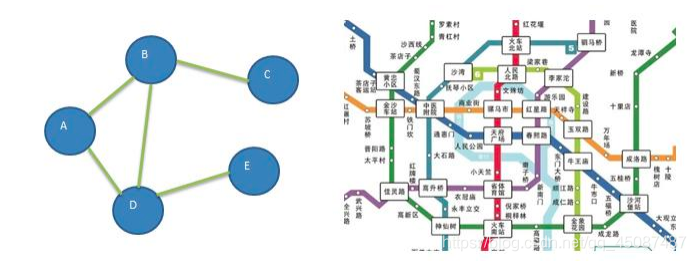
13.1.3 ЭМЕФГЃгУИХФю
- ЖЅЕу(vertex)
- Бп(edge)
- ТЗОЖ
- ЮоЯђЭМ(гвЭМ
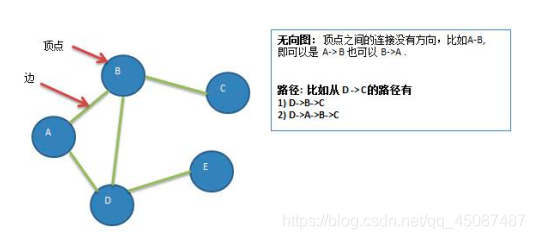
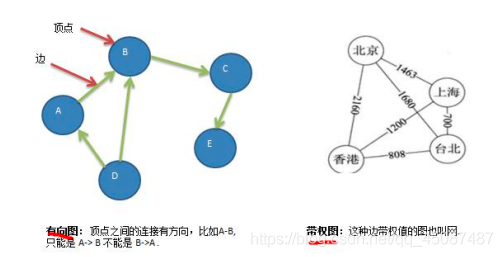
- гаЯђЭМ
- ДјШЈЭМ
13.2 ЭМЕФБэЪОЗНЪН
ЭМЕФБэЪОЗНЪНгаСНжж:ЖўЮЌЪ§зщБэЪО(СкНгОиеѓ);СДБэБэЪО(СкНгБэ)ЁЃ
13.2.1 СкНгОиеѓ
СкНгОиеѓЪЧБэЪОЭМаЮжаЖЅЕужЎМфЯрСкЙиЯЕЕФОиеѓ,Ждгк n ИіЖЅЕуЕФЭМЖјбд,ОиеѓЪЧЕФ row КЭ col БэЪОЕФЪЧ 1ЁnИіЕуЁЃ
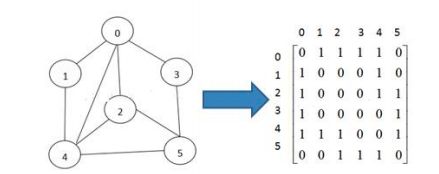
13.2.2 СкНгБэ
- СкНгОиеѓашвЊЮЊУПИіЖЅЕуЖМЗжХф n ИіБпЕФПеМф,ЦфЪЕгаКмЖрБпЖМЪЧВЛДцдк,ЛсдьГЩПеМфЕФвЛЖЈЫ№ЪЇ.
- СкНгБэЕФЪЕЯжжЛЙиаФДцдкЕФБп,ВЛЙиаФВЛДцдкЕФБпЁЃвђДЫУЛгаПеМфРЫЗб,СкНгБэгЩЪ§зщ+СДБэзщГЩ
- ОйР§ЫЕУї
13.3 ЭМЕФПьЫйШыУХАИР§
- вЊЧѓ: ДњТыЪЕЯжШчЯТЭМНсЙЙ.
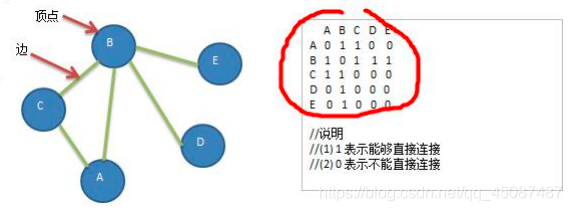
- ЫМТЗЗжЮі (1) ДцДЂЖЅЕу String ЪЙгУ ArrayList (2) БЃДцОиеѓ int[][] edges
- ДњТыЪЕЯж
public void insertVertex(String vertex) {
vertexList.add(vertex);
}
public void insertEdge(int v1, int v2, int weight) {
edges[v1][v2] = weight;
edges[v2][v1] = weight;
numOfEdges++;
}
13.4 ЭМЕФЩюЖШгХЯШБщРњНщЩм
13.4.1 ЭМБщРњНщЩм
ЫљЮНЭМЕФБщРњ,МДЪЧЖдНсЕуЕФЗУЮЪЁЃвЛИіЭМгаФЧУДЖрИіНсЕу,ШчКЮБщРњетаЉНсЕу,ашвЊЬиЖЈВпТд,вЛАугаСНжжЗУЮЪВпТд: (1)ЩюЖШгХЯШБщРњ (2)ЙуЖШгХЯШБщРњ
13.4.2 ЩюЖШгХЯШБщРњЛљБОЫМЯы
ЭМЕФЩюЖШгХЯШЫбЫї(Depth First Search) ЁЃ
- ЩюЖШгХЯШБщРњ,ДгГѕЪМЗУЮЪНсЕуГіЗЂ,ГѕЪМЗУЮЪНсЕуПЩФмгаЖрИіСкНгНсЕу,ЩюЖШгХЯШБщРњЕФВпТдОЭЪЧЪзЯШЗУЮЪ
ЕквЛИіСкНгНсЕу,ШЛКѓдйвдетИіБЛЗУЮЪЕФСкНгНсЕузїЮЊГѕЪМНсЕу,ЗУЮЪЫќЕФЕквЛИіСкНгНсЕу, ПЩвдетбљРэНт:
УПДЮЖМдкЗУЮЪЭъЕБЧАНсЕуКѓЪзЯШЗУЮЪЕБЧАНсЕуЕФЕквЛИіСкНгНсЕуЁЃ - ЮвУЧПЩвдПДЕН,етбљЕФЗУЮЪВпТдЪЧгХЯШЭљзнЯђЭкОђЩюШы,ЖјВЛЪЧЖдвЛИіНсЕуЕФЫљгаСкНгНсЕуНјааКсЯђЗУЮЪЁЃ
- ЯдШЛ,ЩюЖШгХЯШЫбЫїЪЧвЛИіЕнЙщЕФЙ§ГЬ
13.4.3 ЩюЖШгХЯШБщРњЫуЗЈВНжш
- ЗУЮЪГѕЪМНсЕу v,ВЂБъМЧНсЕу v ЮЊвбЗУЮЪЁЃ
- ВщевНсЕу v ЕФЕквЛИіСкНгНсЕу wЁЃ
- Шє w Дцдк,дђМЬајжДаа 4,ШчЙћ w ВЛДцдк,дђЛиЕНЕк 1 ВН,НЋДг v ЕФЯТвЛИіНсЕуМЬајЁЃ
- Шє w ЮДБЛЗУЮЪ,Жд w НјааЩюЖШгХЯШБщРњЕнЙщ(МДАб w ЕБзіСэвЛИі v,ШЛКѓНјааВНжш 123)ЁЃ
- ВщевНсЕу v ЕФ w СкНгНсЕуЕФЯТвЛИіСкНгНсЕу,зЊЕНВНжш 3ЁЃ
- ЗжЮіЭМ

13.4.4 ЩюЖШгХЯШЫуЗЈЕФДњТыЪЕЯж
private void dfs(boolean[] isVisited, int i) {
System.out.print(getValueByIndex(i) + "->");
isVisited[i] = true;
int w = getFirstNeighbor(i);
while(w != -1) {
if(!isVisited[w]) {
dfs(isVisited, w);
}
w = getNextNeighbor(i, w);
}
}
public void dfs() {
isVisited = new boolean[vertexList.size()];
for(int i = 0; i < getNumOfVertex(); i++) {
if(!isVisited[i]) {
dfs(isVisited, i);
}
}
}
13.5 ЭМЕФЙуЖШгХЯШБщРњ
13.5.1 ЙуЖШгХЯШБщРњЛљБОЫМЯы
- ЭМЕФЙуЖШгХЯШЫбЫї(Broad First Search) ЁЃ
- РрЫЦгквЛИіЗжВуЫбЫїЕФЙ§ГЬ,ЙуЖШгХЯШБщРњашвЊЪЙгУвЛИіЖгСавдБЃГжЗУЮЪЙ§ЕФНсЕуЕФЫГађ,вдБуАДетИіЫГађРДЗУЮЪетаЉНсЕуЕФСкНгНсЕу
13.5.2 ЙуЖШгХЯШБщРњЫуЗЈВНжш
- ЗУЮЪГѕЪМНсЕу v ВЂБъМЧНсЕу v ЮЊвбЗУЮЪЁЃ
- НсЕу v ШыЖгСа
- ЕБЖгСаЗЧПеЪБ,МЬајжДаа,ЗёдђЫуЗЈНсЪјЁЃ
- ГіЖгСа,ШЁЕУЖгЭЗНсЕу uЁЃ
- ВщевНсЕу u ЕФЕквЛИіСкНгНсЕу wЁЃ
- ШєНсЕу u ЕФСкНгНсЕу w ВЛДцдк,дђзЊЕНВНжш 3;ЗёдђбЛЗжДаавдЯТШ§ИіВНжш:
6.1 ШєНсЕу w ЩаЮДБЛЗУЮЪ,дђЗУЮЪНсЕу w ВЂБъМЧЮЊвбЗУЮЪЁЃ
6.2 НсЕу w ШыЖгСа
6.3 ВщевНсЕу u ЕФМЬ w СкНгНсЕуКѓЕФЯТвЛИіСкНгНсЕу w,зЊЕНВНжш 6ЁЃ
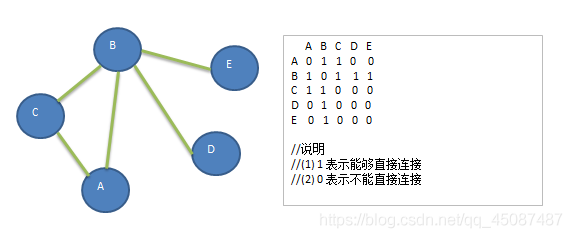
13.5.3 ЙуЖШгХЯШЫуЗЈЕФЭМЪО
13.6 ЙуЖШгХЯШЫуЗЈЕФДњТыЪЕЯж
private void bfs(boolean[] isVisited, int i) {
int u ;
int w ;
LinkedList queue = new LinkedList();
System.out.print(getValueByIndex(i) + "=>");
isVisited[i] = true;
queue.addLast(i);
while( !queue.isEmpty()) {
u = (Integer)queue.removeFirst();
w = getFirstNeighbor(u);
while(w != -1) {
if(!isVisited[w]) {
System.out.print(getValueByIndex(w) + "=>");
isVisited[w] = true;
queue.addLast(w);
}
w = getNextNeighbor(u, w);
}
}
}
public void bfs() {
isVisited = new boolean[vertexList.size()];
for(int i = 0; i < getNumOfVertex(); i++) {
if(!isVisited[i]) {
bfs(isVisited, i);
}
}
}
13.7 ЭМЕФДњТыЛузм
package com.atguigu.graph;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.LinkedList;
public class Graph {
private ArrayList<String> vertexList;
private int[][] edges;
private int numOfEdges;
private boolean[] isVisited;
public static void main(String[] args) {
int n = 8;
String Vertexs[] = {"1", "2", "3", "4", "5", "6", "7", "8"};
Graph graph = new Graph(n);
for(String vertex: Vertexs) {
graph.insertVertex(vertex);
}
graph.insertEdge(0, 1, 1);
graph.insertEdge(0, 2, 1);
graph.insertEdge(1, 3, 1);
graph.insertEdge(1, 4, 1);
graph.insertEdge(3, 7, 1);
graph.insertEdge(4, 7, 1);
graph.insertEdge(2, 5, 1);
graph.insertEdge(2, 6, 1);
graph.insertEdge(5, 6, 1);
graph.showGraph();
System.out.println("ЩюЖШБщРњ");
graph.dfs();
System.out.println("ЙуЖШгХЯШ!");
graph.bfs();
}
public Graph(