Spark大数据分析与实战:基于Spark框架实现TopN
基于Spark框架实现TopN
一、实验背景:
基于Spark框架实现TopN
二、实验目的:
获取蜀国武将中武力值最高的5位,即通过分布式计算框架实现从原始数据查询出武力最高的Top5
三、实验步骤:
- 安装Hadoop和Spark
- 启动Hadoop与Spark
- 创建 rank.txt 文件
- 将 rank.txt 文件上传到 HDFS 上
- 实现TopN计算
- 查看 HDFS 上的结果
四、实验过程:
1、安装Hadoop和Spark
具体的安装过程在我以前的博客里面有,大家可以通过以下链接进入操作:
Hadoop的安装:https://blog.csdn.net/weixin_47580081/article/details/108647420
Scala及Spark的安装:https://blog.csdn.net/weixin_47580081/article/details/114250894
提示:如果IDEA未构建Spark项目,可以转接到以下的博客:
IDEA使用Maven构建Spark项目:https://blog.csdn.net/weixin_47580081/article/details/115435536
2、
查看3个节点的进程
master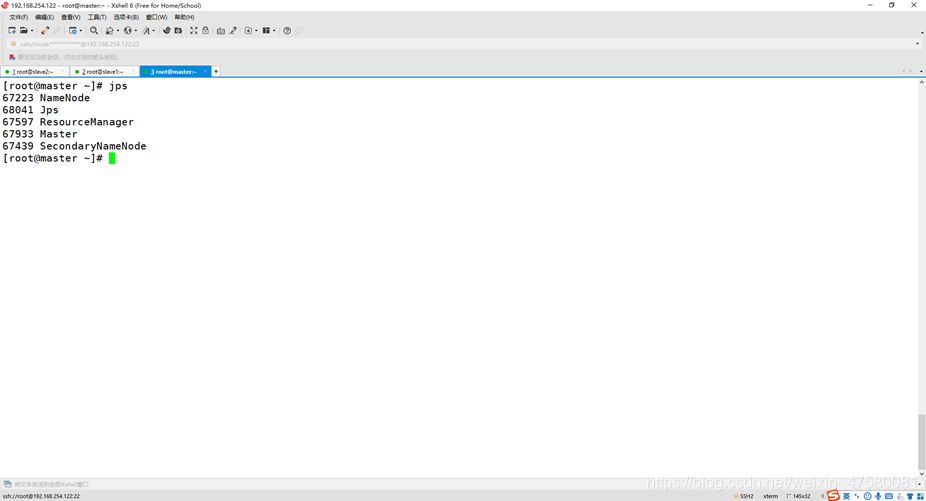
slave1

slave2
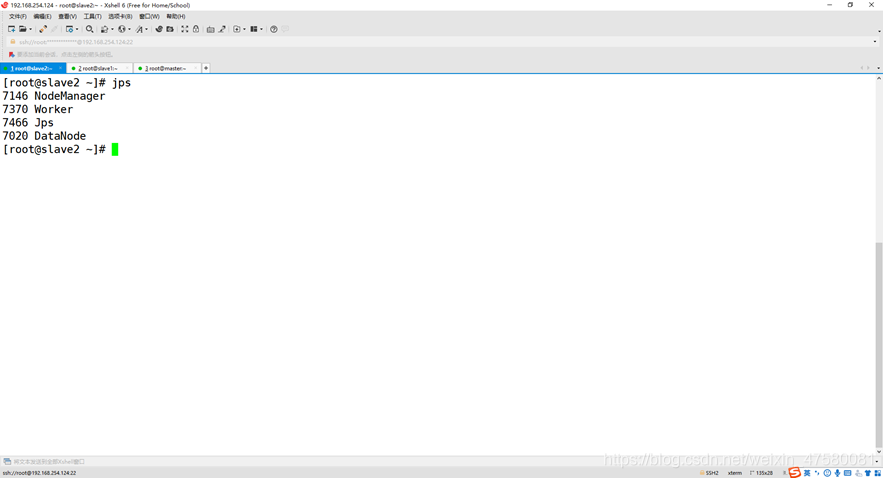
3、创建 rank.txt 文件
Shell命令:
[root@master ~]
[root@master data]

4、将 rank.txt 文件上传到 HDFS 上
Shell命令:
[root@master data]
[root@master data]
[root@master data]

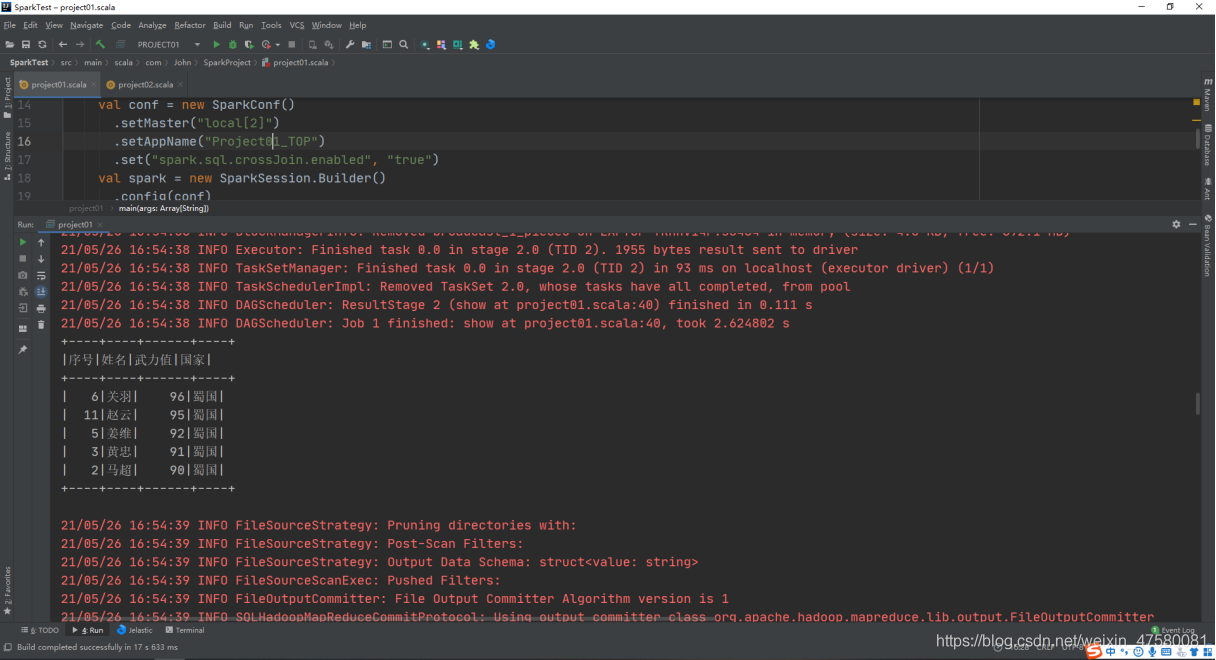
5、实现TopN计算
package com.John.SparkProject
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object project01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("Project01_TOP")
.set("spark.sql.crossJoin.enabled", "true")
val spark = new SparkSession.Builder()
.config(conf)
.getOrCreate()
val text = spark.read.textFile("hdfs://192.168.254.122:9000/spark/input/rank.txt")
import spark.implicits._
val header = text.first()
val dsData = text.filter(_ != header)
val dfData = dsData.map(line => {
val Array(id, name, experience,country) = line.split(' ')
(id.toInt, name, experience.toInt,country)
}).toDF("序号", "姓名", "武力值","国家")
val setRes = dfData.orderBy(-dfData("武力值")).limit(5)
setRes.show()
setRes.write.format("json").save("hdfs://192.168.254.122:9000/spark/output/")
}
}
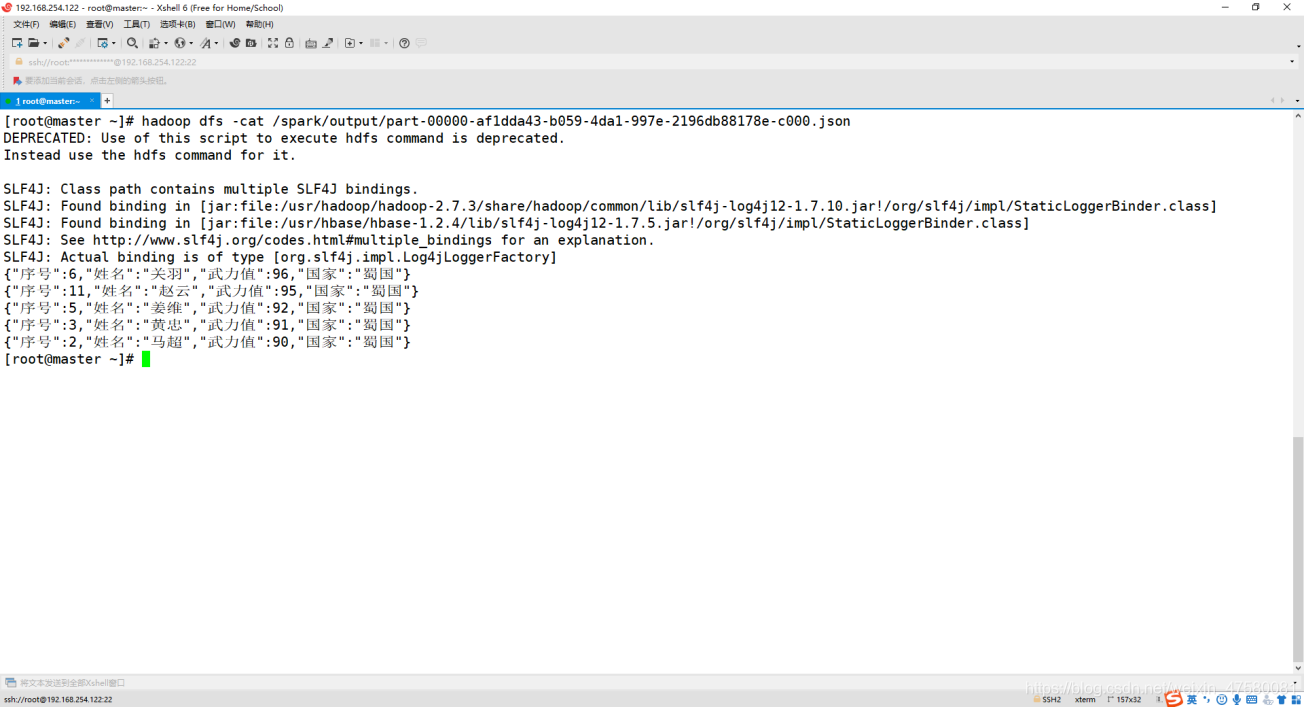
6、查看 HDFS 上的结果
Shell命令:
[root@master ~]
五、实验结论:
实验主要考察了大家对HDFS的操作,和Spark对数据操作以及关联HDFS。
实验难度不是特别大,大家可以进一步的推广尝试!
cs