SparkДѓЪ§ОнЗжЮігыЪЕеН:ЛљгкSpark MLlib ЪЕЯжвєРжЭЦМі
ЛљгкSpark MLlib ЪЕЯжвєРжЭЦМі
вЛЁЂЪЕбщБГОА:
ЪьЯЄ Audioscrobbler Ъ§ОнМЏ
ЛљгкИУЪ§ОнМЏбЁдёКЯЪЪЕФ MLlib ПтЫуЗЈНјааЪ§ОнДІРэ
НјаавєРжЭЦМі(ЛђгУЛЇЭЦМі)
ЖўЁЂЪЕбщФПЕФ:
МЦЫуAUCЦРЗжзюИпЕФВЮЪ§
РћгУAUCЦРЗжзюИпЕФВЮЪ§,ИјгУЛЇЭЦМівеЪѕМв
ЖдЖрИігУЛЇНјаавеЪѕМвЭЦМі
РћгУAUCЦРЗжзюИпЕФВЮЪ§,ИјвеЪѕМвЭЦМіЯВЛЖЫћЕФгУЛЇ
Ш§ЁЂЪЕбщВНжш:
- АВзАHadoopКЭSpark
- ЦєЖЏHadoopгыSpark
- НЋЮФМўЩЯДЋЕН HDFS
- ЪЕЯжвєРжЭЦМі
ЫФЁЂЪЕбщЙ§ГЬ:
1ЁЂАВзАHadoopКЭSpark
ОпЬхЕФАВзАЙ§ГЬдкЮввдЧАЕФВЉПЭРяУцга,ДѓМвПЩвдЭЈЙ§вдЯТСДНгНјШыВйзї:
HadoopЕФАВзА:https://blog.csdn.net/weixin_47580081/article/details/108647420
ScalaМАSparkЕФАВзА:https://blog.csdn.net/weixin_47580081/article/details/114250894
ЬсЪО:ШчЙћIDEAЮДЙЙНЈSparkЯюФП,ПЩвдзЊНгЕНвдЯТЕФВЉПЭ:
IDEAЪЙгУMavenЙЙНЈSparkЯюФП:https://blog.csdn.net/weixin_47580081/article/details/115435536
2ЁЂЦєЖЏHadoopгыSpark
ВщПД3ИіНкЕуЕФНјГЬ
master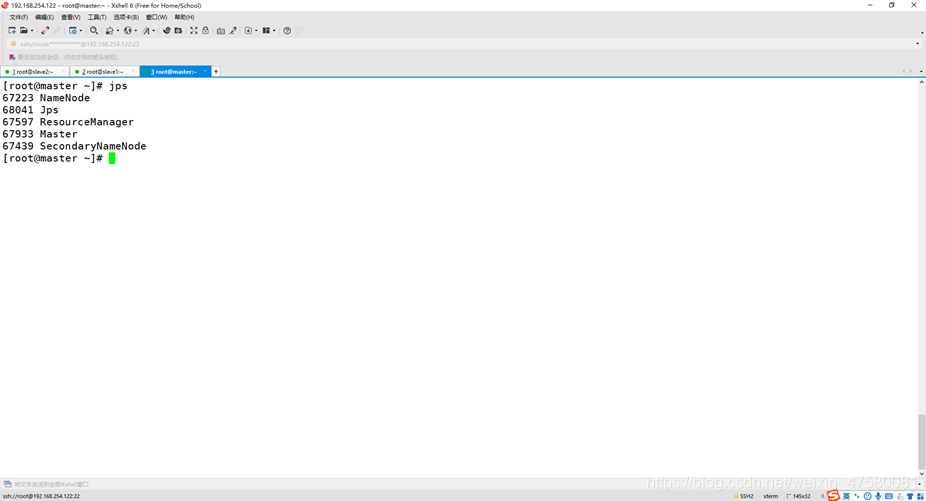
slave1
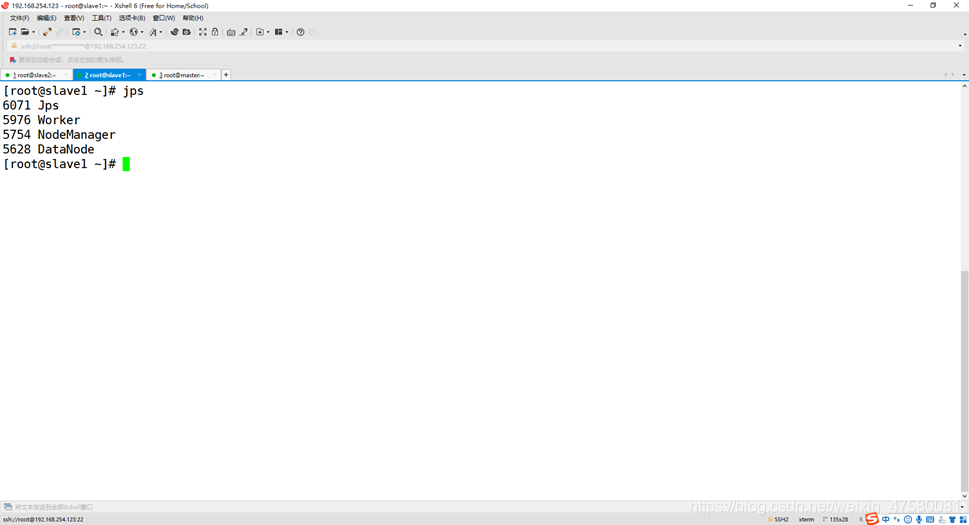
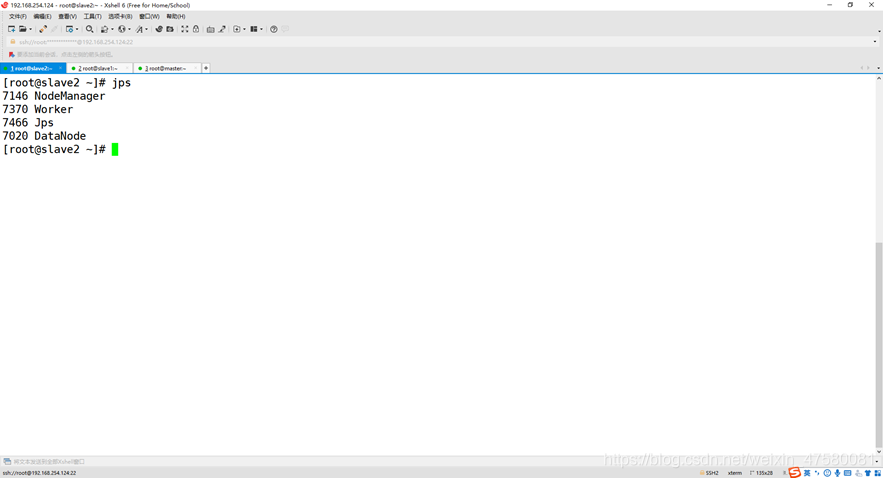
slave2
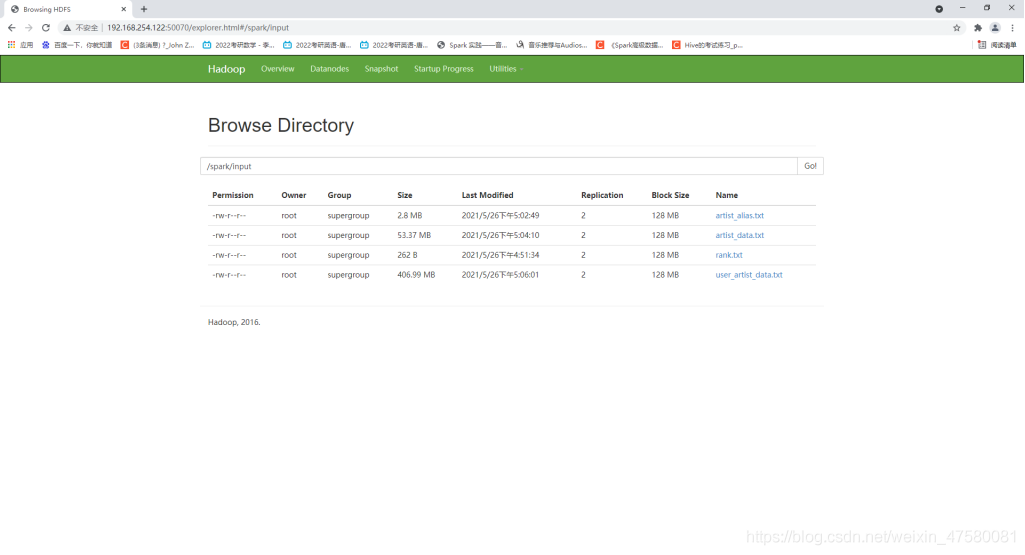
3ЁЂНЋЮФМўЩЯДЋЕН HDFS
ShellУќСю:
[root@master ~]
[root@master profiledata_06-May-2005]
[root@master profiledata_06-May-2005]
4ЁЂЪЕЯжвєРжЭЦМі
дДДњТы:
package com.John.SparkProject
import org.apache.spark.SparkConf
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.ml.recommendation.{ALS, ALSModel}
import org.apache.spark.sql.functions._
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
import scala.collection.mutable.ArrayBuffer
import scala.util.Random
object project02 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("Project02_RecommenderApp")
.set("spark.sql.crossJoin.enabled", "true")
val spark = new SparkSession.Builder()
.config(conf)
.getOrCreate()
import spark.implicits._
val rawArtistData = spark.read.textFile("hdfs://192.168.254.122:9000/spark/input/artist_data.txt")
val artistIdDF = transformArtistData(rawArtistData)
val artistIdDFtest = transformArtistData1(rawArtistData)
val rawAliasData = spark.read.textFile("hdfs://192.168.254.122:9000/spark/input/artist_alias.txt")
val artistAlias = transformAliasData(rawAliasData).collect().toMap
val rawUserArtistData = spark.read.textFile("hdfs://192.168.254.122:9000/spark/input/user_artist_data.txt")
val allDF = transformUserArtistData(spark, rawUserArtistData, artistAlias)
allDF.persist()
val Array(trainDF, testDF) = allDF.randomSplit(Array(0.9, 0.1))
trainDF.persist()
allDF.join(artistIdDFtest,"artist").select("name").filter("user='2093760'").show(5)
spark.stop()
}
def transformUserArtistData(spark: SparkSession, rawUserArtistDS: Dataset[String], artistAlias: Map[Int, Int]): DataFrame = {
import spark.implicits._
val bArtistAlias = spark.sparkContext.broadcast(artistAlias)
rawUserArtistDS.map(line => {
val Array(userId, artistId, count) = line.split(' ').map(_.toInt)
val finalArtistId = bArtistAlias.value.getOrElse(artistId, artistId)
(userId, finalArtistId, count)
}).toDF("user", "artist", "count").cache()
}
def transformArtistData(rawArtistData: Dataset[String]): DataFrame = {
import rawArtistData.sparkSession.implicits._
rawArtistData.flatMap(line => {
val (id, name) = line.span(_ != '\t')
try {
if (name.nonEmpty)
Some(id.toInt, name.trim)
else
None
} catch {
case _: Exception => None
}
}).toDF("id", "name").cache()
}
def transformArtistData1(rawArtistData: Dataset[String]): DataFrame = {
import rawArtistData.sparkSession.implicits.