optim ЕФЛљБОЪЙгУ
for do:
1. МЦЫуloss
2. ЧхПеЬнЖШ
3. ЗДДЋЬнЖШ
4. ИќаТВЮЪ§
optimЕФЭъећСїГЬ
cifiron = nn.MSELoss()
optimiter = torch.optim.SGD(net.parameters(),lr=0.01,momentum=0.9)
for i in range(iters):
out = net(inputs)
loss = cifiron(out,label)
optimiter.zero_grad() # ЧхПежЎЧАБЃСєЕФЬнЖШаХЯЂ
loss.backward() # НЋmini_batch ЕФloss аХЯЂЗДДЋЛиШЅ
optimiter.step() # ИљОн optimВЮЪ§ КЭ ЬнЖШ ИќаТВЮЪ§ w.data -= w.grad*lr
ЭјТчВЮЪ§ ФЌШЯЪЙгУЭГвЛЕФ гХЛЏЦїВЮЪ§
ШчЯТЩшжУ ЭјТчШЋОжВЮЪ§ ЪЙгУЭГвЛЕФгХЛЏЦїВЮЪ§
optimiter = torch.optim.Adam(net.parameters(),lr=0.01,momentum=0.9)
ШчЯТЩшжУНЋoptimizerЕФПЩИќаТВЮЪ§ЗжЮЊВЛЭЌЕФШ§зщЃЌУПзщЪЙгУВЛЭЌЕФВпТд
optimizer = torch.optim.SGD([
{'params': other_params},
{'params': first_params, 'lr': 0.01*args.learning_rate},
{'params': second_params, 'weight_decay': args.weight_decay}],
lr=args.learning_rate,
momentum=args.momentum,
)
ЮвУЧзЗЫнвЛЯТЙЙдьOptimЕФЙ§ГЬ
ЮЊСЫИќКУЕФПДећИіЙ§ГЬЃЌШЅЕєСЫКмЖр ЬѕМўХаЖЯ гяОфЃЌШч >0 <0
# ЪзЯШЪЧ згРрAdam ЕФЙЙдьКЏЪ§
class Adam(Optimizer):
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8,
weight_decay=0, amsgrad=False):
defaults = dict(lr=lr, betas=betas, eps=eps,
weight_decay=weight_decay, amsgrad=amsgrad)
'''
ЙЙдьСЫ ВЮЪ§paramsЃЌПЩвдгаСНжжДЋШыИёЪН,ЗжБ№ЖдгІ
1. ШЋОжВЮЪ§ net.parameters()
2. ВЛЭЌВЮЪ§зщ [{'params': other_params},
{'params': first_params, 'lr': 0.1*lr}]
КЭ <ШЋОж> ЕФФЌШЯВЮЪ§зжЕфdefaults
'''
# ШЛКѓЕїгУ ИИРрOptimizer ЕФЙЙдьКЏЪ§
super(Adam, self).__init__(params, defaults)
# ПДвЛЯТ OptimРрЕФЙЙдьКЏЪ§ жЛгаСНИіЪфШы params КЭ defaults
class Optimizer(object):
def __init__(self, params, defaults):
torch._C._log_api_usage_once("python.optimizer")
self.defaults = defaults
self.state = defaultdict(dict)
self.param_groups = [] # здЩэЙЙдьЕФВЮЪ§зщЃЌУПИізщЪЙгУвЛЬзВЮЪ§
param_groups = list(params)
if len(param_groups) == 0:
raise ValueError("optimizer got an empty parameter list")
# ШчЙћДЋШыЕФnet.parameters()ЃЌНЋЦфзЊЛЛЮЊ зжЕф
if not isinstance(param_groups[0], dict):
param_groups = [{'params': param_groups}]
for param_group in param_groups:
#add_param_group етИіКЏЪ§,жївЊЪЧДІРэвЛЯТУПИіВЮЪ§зщЦфЫќЪєадВЮЪ§(lr,eps)
self.add_param_group(param_group)
def add_param_group(self, param_group):
# ШчЙћЕБЧА ВЮЪ§зщжа ВЛДцдкФЌШЯВЮЪ§ЕФЩшжУЃЌдђЪЙгУШЋОжВЮЪ§ЪєадНјааИВИЧ
'''
[{'params': other_params},
{'params': first_params, 'lr': 0.1*lr}]
ШчЕквЛИіВЮЪ§зщ жЛЬсЙЉСЫВЮЪ§СаБэЃЌУЛгаЦфЫќЕФВЮЪ§ЪєадЃЌдђЪЙгУШЋОжЪєадИВИЧЃЌЕкЖўИіВЮЪ§зщ дђЩшжУСЫздЩэЕФlrЮЊШЋОж (0.1*lr)
'''
for name, default in self.defaults.items():
if default is required and name not in param_group:
raise ValueError("parameter group didn't specify a value of required optimization parameter " +
name)
else:
param_group.setdefault(name, default)
# ХаЖЯ ЪЧЗёгавЛИіВЮЪ§ ГіЯждкВЛЭЌЕФВЮЪ§зщжаЃЌЗёдђЛсБЈДэ
param_set = set()
for group in self.param_groups:
param_set.update(set(group['params']))
if not param_set.isdisjoint(set(param_group['params'])):
raise ValueError("some parameters appear in more than one parameter group")
# ШЛКѓ ИќаТздЩэЕФВЮЪ§зщжа
self.param_groups.append(param_group)
ЭјТчИќаТЕФЙ§ГЬ(Step)
ОпЬхЪЕЯж
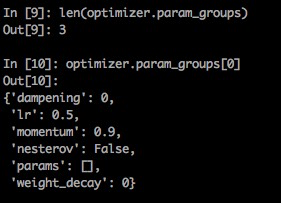
1ЁЂЮвУЧФУSGDОйР§ЃЌЪзЯШПДвЛЯТЃЌoptim.step ИќаТКЏЪ§ЕФОпЬхВйзї
2ЁЂПЩМћЃЌfor group in self.param_groupsЃЌoptimжаДцдквЛИіparam_groupsЕФЖЋЮїЃЌЦфЪЕЫќОЭЪЧЮвУЧДЋНјШЅЕФparam_listЃЌБШШчЮвУЧЩЯУцДЋНјШЅвЛИіГЄЖШЮЊ3ЕФparam_list,ФЧУД len(optimizer.param_groups)==3 , ЖјУПвЛИі group гжЪЧвЛИіdict, ЦфжаАќКЌСЫ УПзщВЮЪ§ЫљашЕФБивЊВЮЪ§ optimizer.param_groups:ГЄЖШ2ЕФlistЃЌoptimizer.param_groups[0]ЃКГЄЖШ6ЕФзжЕф
3ЁЂШЛКѓШЁЛиУПзщ ЫљашИќаТЕФВЮЪ§for p in group['params'] ,ИљОнЩшжУ МЦЫуЦф е§дђЛЏ МА ЖЏСПРлЛ§ЃЌШЛКѓИќаТВЮЪ§ w.data -= w.grad*lr
def step(self, closure=None):
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
# БОзщВЮЪ§ИќаТЫљБиашЕФ ВЮЪ§ЩшжУ
weight_decay = group['weight_decay']
momentum = group['momentum']
dampening = group['dampening']
nesterov = group['nesterov']
for p in group['params']: # БОзщЫљгаашвЊИќаТЕФВЮЪ§ params
if p.grad is None: # ШчЙћУЛгаЬнЖШ дђжБНгЯТвЛВН
continue
d_p = p.grad.data
# е§дђЛЏ МА ЖЏСПРлЛ§ Вйзї
if weight_decay != 0:
d_p.add_(weight_decay, p.data)
if momentum != 0:
param_state = self.state[p]
if 'momentum_buffer' not in param_state:
buf = param_state['momentum_buffer'] = torch.clone(d_p).detach()
else:
buf = param_state['momentum_buffer']
buf.mul_(momentum).add_(1 - dampening, d_p)
if nesterov:
d_p = d_p.add(momentum, buf)
else:
d_p = buf
# ЕБЧАзщ бЇЯАВЮЪ§ ИќаТ w.data -= w.grad*lr
p.data.add_(-group['lr'], d_p)
return loss
ШчКЮЛёШЁжИЖЈВЮЪ§
1ЁЂПЩвдЪЙгУmodel.named_parameters() ШЁЛиЫљгаВЮЪ§ЃЌШЛКѓЩшЖЈздМКЕФЩИбЁЙцдђЃЌНЋВЮЪ§Зжзщ
2ЁЂШЁЛиЗжзщВЮЪ§ЕФid map(id, weight_params_list)
3ЁЂШЁЛиЪЃгрЗжЬиЪтДІжУВЮЪ§ЕФid other_params = list(filter(lambda p: id(p) not in params_id, all_params))
all_params = model.parameters()
weight_params = []
quant_params = []
# ИљОнздМКЕФЩИбЁЙцдђ НЋЫљгаЭјТчВЮЪ§НјааЗжзщ
for pname, p in model.named_parameters():
if any([pname.endswith(k) for k in ['cw', 'dw', 'cx', 'dx', 'lamb']]):
quant_params += [p]
elif ('conv' or 'fc' in pname and 'weight' in pname):
weight_params += [p]
# ШЁЛиЗжзщВЮЪ§ЕФid
params_id = list(map(id, weight_params)) + list(map(id, quant_params))
# ШЁЛиЪЃгрЗжЬиЪтДІжУВЮЪ§ЕФid
other_params = list(filter(lambda p: id(p) not in params_id, all_params))
# ЙЙНЈВЛЭЌбЇЯАВЮЪ§ЕФгХЛЏЦї
optimizer = torch.optim.SGD([
{'params': other_params},
{'params': quant_params, 'lr': 0.1*args.learning_rate},
{'params': weight_params, 'weight_decay': args.weight_decay}],
lr=args.learning_rate,
momentum=args.momentum,
)
ЛёШЁжИЖЈВуЕФВЮЪ§id
# # вдВуЮЊЕЅЮЛЃЌЮЊВЛЭЌВужИЖЈВЛЭЌЕФбЇЯАТЪ
# ## ЬсШЁжИЖЈВуЖдЯѓ
special_layers = t.nn.ModuleList([net.classifiter[0], net.classifiter[3]])
# ## ЛёШЁжИЖЈВуВЮЪ§id
special_layers_params = list(map(id, special_layers.parameters()))
print(special_layers_params)
# ## ЛёШЁЗЧжИЖЈВуЕФВЮЪ§id
base_params = filter(lambda p: id(p) not in special_layers_params, net.parameters())
optimizer = t.optim.SGD([{'params': base_params},
{'params': special_layers.parameters(), 'lr': 0.01}], lr=0.001)
ВЙГфЃКЁОpytorchЁПЩИбЁЖГНсВПЗжЭјТчВуВЮЪ§ЭЌЪБЩшжУгаВЮЪ§зщЕФЪБКђИУдѕУДАьЃП
дкНјааЩёОЭјТчбЕСЗЕФЪБКђЃЌГЃГЃашвЊЖГНсВПЗжЭјТчВуЕФВЮЪ§ЃЌВЛЯыШУЫћУЧЛиДЋЬнЖШЁЃетИіЦфЪЕКмМђЕЅЃЌЦфЫћВЉПЭРяНЬГЬКмЖр~
ФЧШчЙћЃЌЮвЯыЖдВЛЭЌЕФВЮЪ§ЩшжУВЛЭЌЕФбЇЯАТЪФиЃПетИіЦфЫћВЉПЭвВгаЃЌЩшжУВЮЪ§зщОЭКУРВЃЌгХЛЏЦїОЭПЩвдЗжБ№ЩшжУбЇЯАТЪСЫЁЃ
ФЧУДЃЌШчЙћЮвЭЌЪБЯыЖГНсВЮЪ§КЭЩшжУВЛЭЌЕФбЇЯАТЪФиЃПЪЧВЛЪЧАбСНИіШЫИјКЯЦ№РДОЭКУСЫЃПКУЕФФЧФуЪдЪдАЩПДПДааВЛааЁЃ
ЮвзюНќЙЄзїжаашвЊЖдtwo-streamЕФЦфжаЕФвЛжЛНјааЖГНсЃЌВЂЧвЩшжУВЛЭЌЕФбЇЯАТЪЁЃЯТУцМЧТМвЛЯТЮвВШЕФПгЁЃ
ЪзЯШЃЌЮвУЧашвЊЩИбЁЫљашвЊЕФВуЁЃЮвЯывЊАбУћзжРяКЌгаЬиЖЈЗћКХЕФВуИјЩИбЁГіРДЁЃдкетРяЮввЊЧПСвЭЦМіетИіРћгУе§дђБэДяЪНРДНјаазжЗћДЎЩИбЁЕФЗНЪНЃЁ
import re
str = 'assdffggggg'
word = 'a'
a = [m.start() for m in re.finditer(word, str)]
етРяЕФaЪЧвЛИіСаБэЃЌЫќРяУцАќКЌЕФЪЧwordдкзжЗћДЎstrжаЫљдкЕФЮЛжУЃЌетРяздШЛОЭЪЧ0СЫЁЃ
дкНјааЭјТчВуВЮЪ§ЖГНсЕФЪБКђЃЌЭјЩЯЛсгаСНжжforбЛЗЃК
for name, p in net.named_parameters():
for p in net.parameters():
етСНжжЖМааЃЌЕЋЪЧЖдгкашвЊЖдЬиЖЈУћГЦЕФЭјТчВуНјааЖГНсЕФЪБКђОЭашвЊбЁЕквЛИіРВЃЌвђЮЊЮвУЧашвЊгУЕНВЮЪ§ЕФ"name"ЪєадЁЃ
ЯТУцОЭЪЧМђЕЅЕФЩИбЁКЭЖГНсЃЌКЭЦфЫћНЬГЬРяУцЕФвЛбљЃК
word1 = 'seg'
for name, p in decode_net.named_parameters():
str = name
a = [m.start() for m in re.finditer(word1, str)]
if a: #СаБэaВЛЮЊПеЕФЛАОЭЩшжУЛиДЋЕФБъЪЖЮЊFalse
p.requires_grad = False
else:
p.requires_grad = True
#if p.requires_grad:#етИіХаЖЯПЩвдДђгЁГіашвЊЛиДЋЬнЖШЕФВуЕФУћГЦ
#print(name)
ЕНетРяЮвУЧОЭЭъГЩСЫЭјТчВЮЪ§ЕФЖГНсЁЃЮвеце§ЯывЊЗжЯэЕФдкЯТУцетИіВПЗжЃЁЃЁПДСЫЫФЬьЕФДѓПгЃЁ
ЖГНсВПЗжВуЕФВЮЪ§жЎКѓЃЌЮвУЧдкЪЙгУгХЛЏЦїЕФЪБКђОЭашвЊЯШАбВЛашвЊЛиДЋЬнЖШЕФВЮЪ§ИјЙ§ТЫЕєЃЌШчЙћВЛЙ§ТЫОЭЛсБЈДэЃЌгХЛЏЦїОЭЛсБЇдЙФудѕУДАбВЛашвЊгХЛЏЕФВЮЪ§ИјЗХНјШЅСЫbalabalaЕФЁЃЫљвдЮвУЧМгвЛИіЃК
optimizer = optim.SGD(
filter(lambda p: p.requires_grad, net.parameters()), # МЧзЁвЛЖЈвЊМгЩЯfilter()ЃЌВЛШЛЛсБЈДэ
lr=0.01, weight_decay=1e-5, momentum=0.9)
ЕНетРявВУЛгаШЮКЮЕФЮЪЬтЁЃЕЋЪЧЃЁЮвзіЗжИюЕФencodeВПЗжЪЧpre-trainedЕФresnetЃЌетВПЗжЮвЕФбЇЯАТЪВЛЯыКЭЮвdecodeЕФВПЗжвЛбљАЁЃЁВЛШЛЮвгУpre-trainedЕФгаЩЖгУЃПЃПsoЃЌЮвЛЎЗжСЫвЛИіВЮЪ§зщЃК
base_params_id = list(map(id, net.conv1.parameters())) + list(map(id,net.bn1.parameters()))+\
list(map(id,net.layer1.parameters())) + list(map(id,net.layer2.parameters())) \
+ list(map(id,net.layer3.parameters())) + list(map(id,net.layer4.parameters()))
new_params = filter(lambda p: id(p) not in base_params_id , net.parameters())
base_params = filter(lambda p: id(p) in base_params_id, net.parameters())
КУСЫЃЌФЧУДетИіЪБКђЃЌШчЙћЮвЯШВЛПМТЧЙ§ТЫЕФЛАЃЌгХЛЏЦїЕФЩшжУгІИУЪЧетбљЕФЃК
optimizerG = optim.SGD([{'params': base_params, 'lr': 1e-4},
{'params': new_params}], lr = opt.lr, momentum = 0.9, weight_decay=0.0005)
ФЧУДЃЌАДееАйЖШГіРДЕФНЬГЬЃЌЮвЯТвЛВНвЊМгЩЯЙ§ТЫЦїЕФЛАЪЧВЛЪЧгІИУЃК
optimizerG = optim.SGD( filter(lambda p: p.requires_grad, net.parameters())ЃЌ
[{'params': base_params, 'lr': 1e-4},
{'params': new_params}], lr = opt.lr, momentum = 0.9, weight_decay=0.0005)
КУЕФПДЦ№РДУЛгаШЮКЮЕФЮЪЬтЃЌЕЋЪЧдЫааЕФЪБКђОЭПЊЪМБЈДэЃК

ОЭЪЧетРяЃЁЃЁвЛИіИеПЊЪМгУpytorchЕФЮвЃЁЪВУДЖМВЛЖЎЃЁШЛКѓЮвПДСЫЫФЬьЃЁЃЁзюКѓВщдФСЫЙйЗНЮФЕЕВХжЊЕРЮЊЪВУДБЈДэЁЃвдКѓПДЕНетжжЬсЪОinitКЏЪ§ДэЮѓЕФЖМвЊМЧЕУШЅЙйЗНdocЩЯПДЫЕУїЁЃ

етРяЦфЪЕаДЕФКмЧхГўСЫЃЌSGDгХЛЏЦїУПИіЮЛжУЖМЪЧЪВУДВЮЪ§ЁЃЕНетРягІИУвбОФмПДГіРДФФРягаЮЪЬтСЫАЩЃП
optimizerG = optim.SGD( filter(lambda p: p.requires_grad, net.parameters())ЃЌ
[{'params': base_params, 'lr': 1e-4},
{'params': new_params}], lr = opt.lr, momentum = 0.9, weight_decay=0.0005)
ПДЮвЕФSGDКЏЪ§УПИіВЮЪ§ЕФЮЛжУЃЌЕквЛИіЗХЕФЪЧЙ§ТЫЦїЃЌЕкЖўИіЪЧВЮЪ§зщЃЌШЛКѓЪЧlrЃЌЖдБШЙйЗНЕФЖЈвхЃКЕквЛИіВЮЪ§ЃЌЕкЖўИіЪЧlrЕШЕШЁЃ
ЫљвдДэЮѓОЭдкетРяЃЁЮвЕквЛИіЮЛжУЗХСЫЙ§ТЫЦїЃЁЕкЖўИіЮЛжУЪЧВЮЪ§зщЃЁЫљвдЫћАбЙ§ТЫЦїЕБзїВЮЪ§ЃЌВЮЪ§зщЕБзїбЇЯАТЪЃЌШЛКѓОЭБЈДэЫЕlrНгЪмЕНКмЖрИіжЕЁЁ
заЯИШЅПДЦфЫћВЉПЭЕФНЬГЬЃЌЛљБОЪЧжЛгаЗжВЮЪ§зщЕФгХЛЏЦїЩшжУКЭЖГНсВуСЫжЎКѓгХЛЏЦїЕФЩшжУЁЃУЛгагжЗжВЮЪ§зщгжЖГНсВПЗжВуВЮЪ§ЕФЩшжУЁЃЫљвдЩшжУЙ§ТЫЦїАбВЛашвЊгХЛЏЕФВЮЪ§ИјЬпЕєетИіВНжшЛЙЪЧвЊЕФЃЌЕЋЪЧдкЯждкетжжЧщПіЯТВЛгІИУЗХдкSGDРяЃЁ
new_params = filter(lambda p: id(p) not in base_params_id and p.requires_grad,\
netG.parameters())
base_params = filter(lambda p: id(p) in base_params_id,
netG.parameters())
гІИУдкЛЎЗжВЮЪ§зщЕФЪБКђОЭЬэМгЙ§ТЫЦїЃЌНЋВЛашвЊЛиДЋЬнЖШЕФВЮЪ§Й§ТЫЕєЃЈетРяОЭЪЧжБНгЩИбЁp.requires_gradМДПЩЃЉЁЃШчДЫБуПЩвдЫГРћЖГНсВЮЪ§ВЂЧвЩшжУВЮЪ§зщРВЃЁ
вдЩЯЮЊИіШЫОбщЃЌЯЃЭћФмИјДѓМввЛИіВЮПМЃЌвВЯЃЭћДѓМвЖрЖржЇГжеОГЄВЉПЭЁЃШчгаДэЮѓЛђЮДПМТЧЭъШЋЕФЕиЗНЃЌЭћВЛСпДЭНЬЁЃ
js