?
中国的AI内行顶级盛会――2021北京智源大会又来了。
每年的智源大会参会阵容都非常豪华,今年也不例外,包括Yoshua Bengio、David Patterson两位图灵奖得主在内的200多位学者将一起对AI的技术和应用进行深度探讨。
Bengio更是带来了他的System2深度学习理论最新进展。

?
但是在今年的智源大会上,最重磅的“明星”却不是这些学者。
因为全球最大的预训练模型的纪录,被中国团队刷新了。
真正的主角是它!
?
?
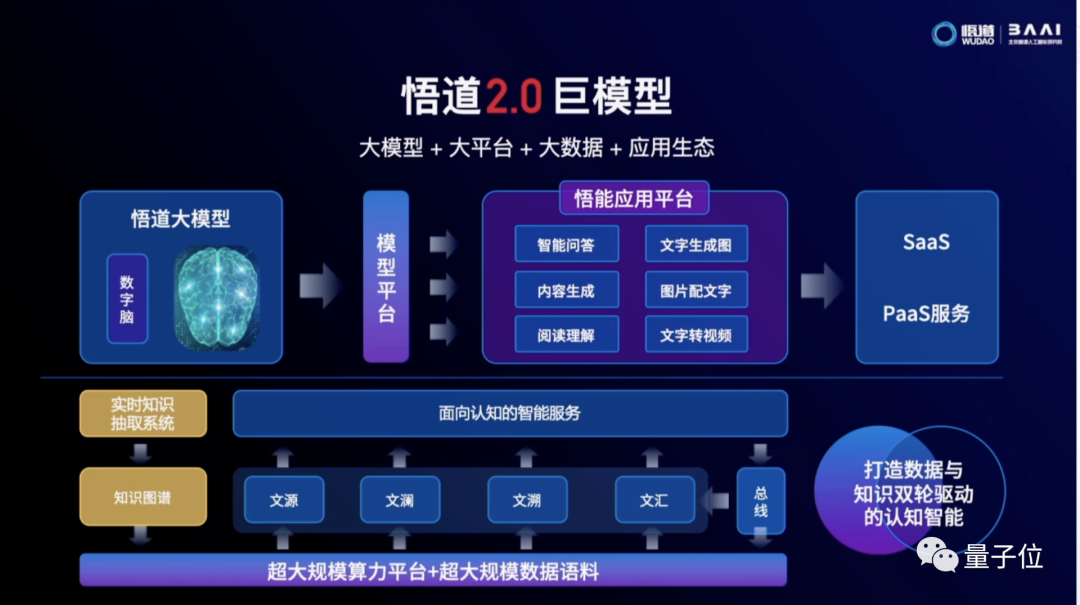
全球最大预训练模型“悟道2.0”发布
?
就在刚刚,北京智源人工智能研究院发布了“悟道2.0”,达到1.75万亿参数,超过之前由谷歌发布的Switch Transformer,成为全球最大的预训练模型。
今年3月22日,智源才发布了“悟道1.0”,这是由智源研究院学术副院长、清华大学教授唐杰领衔,来自北大、清华、中科院等单位的100余位AI科学家团队联合攻关完成。

?
2个多月后,悟道进化到2.0,模型规模爆发级增?,而参数越大,意味着越强的通???智能潜能。
?
“悟道2.0”不仅仅是个语言模型,它是一个全能选手,一统文本和视觉两大领域,在问答、绘画、作诗、视频等任务中正在逼近图灵测试。
?
“悟道2.0”一举在世界公认的9项Benchmark上获得了第一的成绩。

?
尤其值得?提是,这个世界最?万亿模型,完全基于国产超算平台打造,其基础算法是在中国的神威超算上完成模型训练。
对于AI研究者和企业来说,最重要的是,“悟道2.0”和GPT-3小批量付费使用的模式不同,将向AI社区和企业公开预测模型,并从今天起公开API,所有人都可以免费申请使用。
?
悟道背后
那么,为什么新?代“全球最?”预训练模型,会出现在智源“悟道”攻关团队?
智源之所以能打造出1.75亿参数“悟道2.0”,是因为拥有开创性的FastMoE,打破了分布式训练的瓶颈,这是实现“万亿模型”基?的关键。

?
过往,由于谷歌万亿模型的核?技术MoE和其昂贵的硬件强绑定,绝?多数??法得到使?用与研究机会。
MoE是?个在神经?络中引?若?专家?络的技术,能直接推动预训练模型经从亿级参数到万亿级参数的跨越,但离不不开对谷歌分布式训练框架mesh-tensorflow和定制硬件TPU的依赖。
FastMoE打破了这?限制,作为?个支持PyTorch框架的MoE系统,它简单易?、灵活、?性能,并针对神威架构进行了优化,可在国产超算上完成训练。
另外,还有两项技术赋予了悟道更为强大的能力。
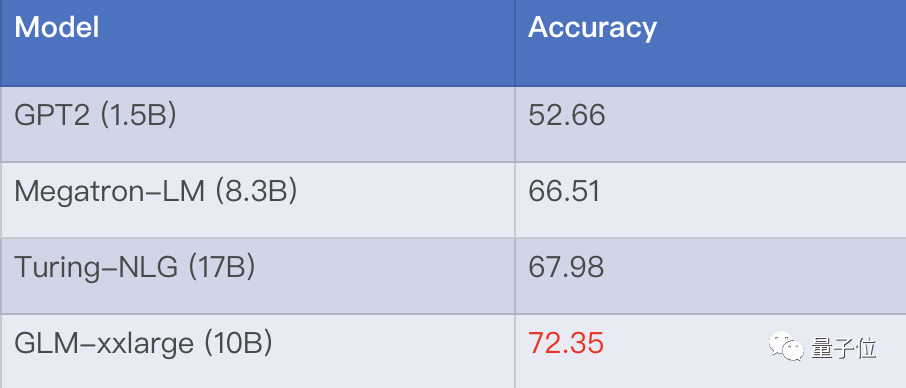
一是最大的英文通用预训练模型GLM 2.0。此前,GLM首次打破BERT和GPT壁垒,开创性地以单?模型兼容所有主流架构。新一代模型以100亿参数量, ?以匹敌微软170亿参数的Turing-NLG模型,在LAMABADA填空测试中表现更优。
?
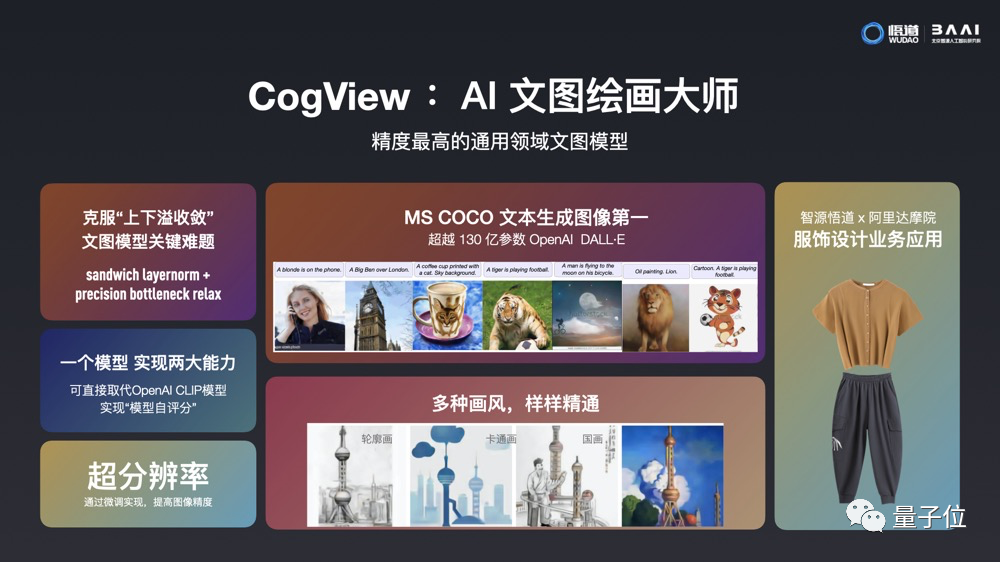
二是世界最大中文多模态生成模型CogView,参数量达40亿,可直接从中文文字生成图像,在MS COCO文本生成图像任务权威指标FID上,CogView打败OpenAI今年年初发布的130亿参数的DALL・E,获得世界第一。
CogView已经和阿里达摩院合作,将这项技术用于服装设计领域。
?
针对小样本学习系统,智源悟道团队提出了微调方法P-Tuning,极大缩小了少样本与全监督学习条件下微调性能的差距。
在训练大规模预训练模型时,要消耗大量的算力资源和时间,为了提升其产业的普适性和易用性,悟道团队搭建了?效预训练框架CPM-2:一个在编码、模型、训练、微调、推理AI全链路上的高效框架。

?
最后,唐杰教授还公布了全新数据集WuDaoCorpora,这是目前全球最大的中文文本数据集(3TB)、多模态数据集(90TB)和中文对话数据集(181G)。

?
?
悟出了什么?
?
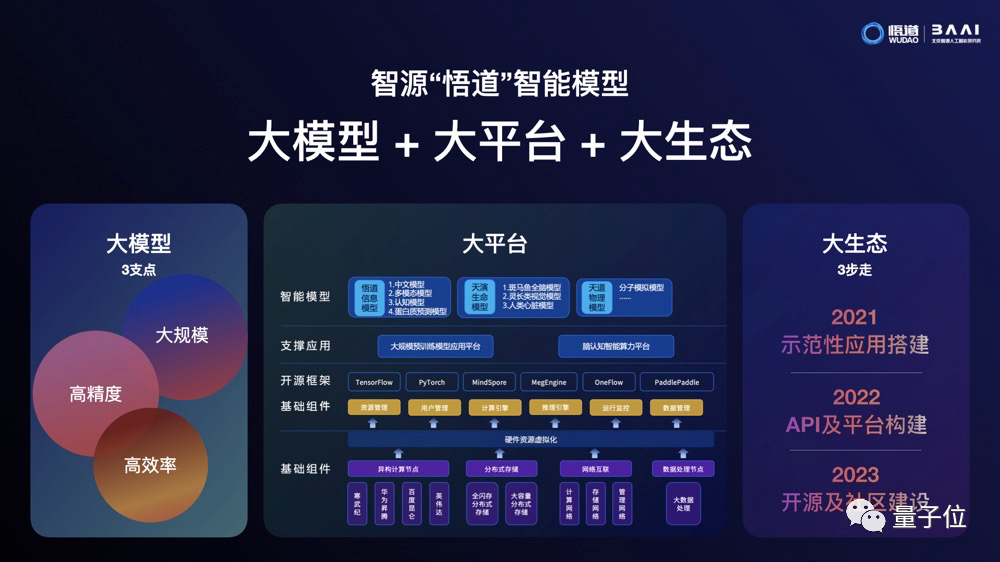
智源并不只满足于技术上的突破,还要以大模型为起点,打造未来AI平台。
?
悟道要成为像“电网”一样的基础设施,为AI在产业上的应用提供源源不断的动力。
大会现场举行了与美团、??、快手、搜狗、360、寒武纪、好未来、新华社等21家企业进行战略合作的签约仪式。

?
联合从行业龙头到中小创新企业,共同组建“悟道大模型技术创新生态联盟”,以模型研发和应用促进产业聚集。
如在与新华社的合作中,将大模型应用于新闻智能化转型。悟道能够进行新闻内容处理、图?生成、传播优化等,还具备接近?类的图?创意能力,可以作诗、 问答、创意写作。
其中,最让人期待的是“悟道”与“小冰”的梦幻联动,这两个AI今天一起打造了虚拟大学生“华智冰”。

?
华智冰同学使用悟道大模型已经掌握了写诗、绘画、作曲等技能,接下来还要拜唐杰教授为师,进入清华唐杰实验室学习,增进自己的能力。
