����˼·:
�����ÿ����߹����ҵ���Ҫ��ȡ���ݵı�ǩ��

����xpath��λ��Ҫ��ȡ���ݵ��б�

Ȼ���������ȡ��Ӧ������:
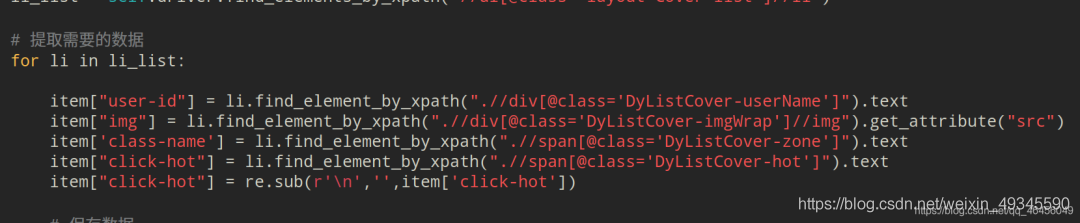
�������ݵ�csv:

���ÿ����߹����ҵ���һҳ��ť���ڱ�ǩ:

����xpath��ȡ�˱�ǩ�����أ�
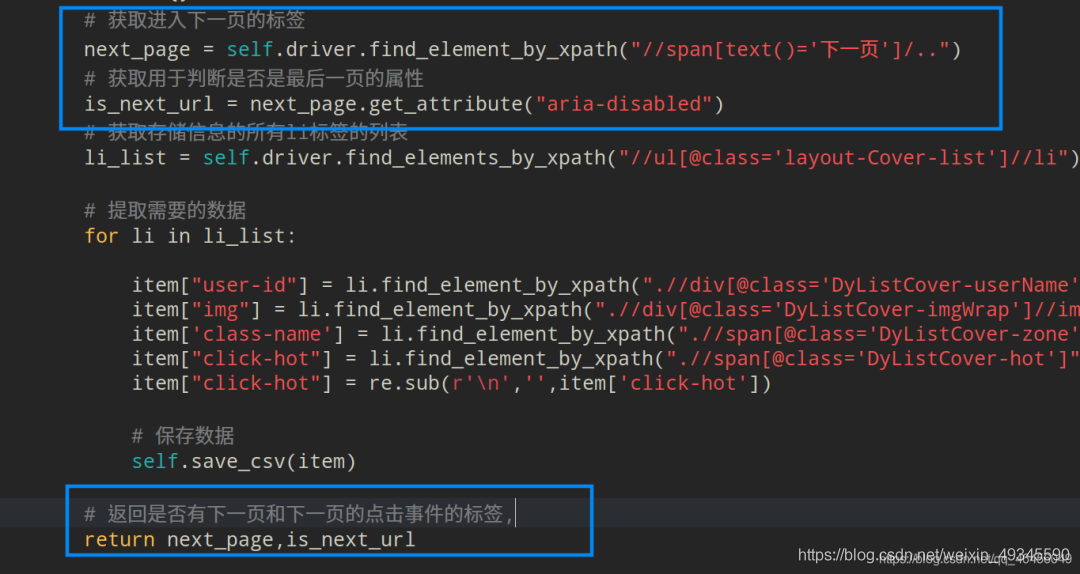
���õ���¼�,��ѭ����������:

����Ч��ͼ:

����:
from selenium import webdriver
import time
import re
class Douyu(object):
def __init__(self):
# ��ʼʱ��url
self.start_url = "https://www.douyu.com/directory/all"
# ʵ����һ��Chrome����
self.driver = webdriver.Chrome()
# ����дcsv�ļ��ı���
self.start_csv = True
def __del__(self):
self.driver.quit()
def get_content(self):
# ���ó�������,��֤ҳ���������ݶ����Լ��س���
time.sleep(2)
item = {}
# ��ȡ������һҳ�ı�ǩ
next_page = self.driver.find_element_by_xpath("//span[text()='��һҳ']/..")
# ��ȡ�����ж��Ƿ������һҳ������
is_next_url = next_page.get_attribute("aria-disabled")
# ��ȡ�洢��Ϣ������li��ǩ���б�
li_list = self.driver.find_elements_by_xpath("//ul[@class='layout-Cover-list']//li")
# ��ȡ��Ҫ������
for li in li_list:
item["user-id"] = li.find_element_by_xpath(".//div[@class='DyListCover-userName']").text
item["img"] = li.find_element_by_xpath(".//div[@class='DyListCover-imgWrap']//img").get_attribute("src")
item['class-name'] = li.find_element_by_xpath(".//span[@class='DyListCover-zone']").text
item["click-hot"] = li.find_element_by_xpath(".//span[@class='DyListCover-hot']").text
item["click-hot"] = re.sub(r'\n','',item['click-hot'])
# ��������
self.save_csv(item)
# �����Ƿ�����һҳ����һҳ�ĵ���¼��ı�ǩ,
return next_page,is_next_url
def save_csv(self,item):
# ����ȡ��ŵ�csv�ļ��е���������Ϊcsv��ʽ�ļ�
str = ','.join([i for i in item.values()])
with open('./douyu.csv','a',encoding='utf-8') as f:
if self.start_csv:
f.write("�û�id,image,������,����ȶ�\n")
self.start_csv = False
# ���ַ���д��csv�ļ�
f.write(str)
f.write('\n')
print("save success")
def run(self):
# ����chrome����λ����Ӧҳ��
self.driver.get(self.start_url)
while True:
# ��ʼ��ȡ����,����ȡ��һҳ��Ԫ��
next_page,is_next = self.get_content()
if is_next!='false':
break
# �����һҳ
next_page.click()
if __name__=='__main__':
douyu_spider = Douyu()
douyu_spider.run()
js