相信大家在爬虫中都设置过请求头 user-agent 这个参数吧? 在请求的时候,加入这个参数,就可以一定程度的伪装成浏览器,就不会被服务器直接识别为spider.demo.code ,据我了解的,我很多读者每次都是直接从network 中去复制 user-agent 然后把他粘贴到代码中, 这样获取的user-agent 没有错,可以用, 但是如果网站反爬措施强一点,用固定的请求头可能就有点问题, 所以我们就需要设置一个随机请求头,在这里,我分享一下我自己一般用的三种设置随机请求头方式
思路介绍:
其实要达到随机的效果,很大程度上我们可以利用随机函数库random 这个来实现,可以调用random.choice([user-agent]) 随机pick数组中一个就可以了,这是我的一种方式。
python作为一个拥有众多第三方包的语言,自然就有可以生成随机请求头的包咯,没错,就是fake-useragent 这个第三方库了,稍后我们介绍一下这个函数库的简单使用。
既然别人可以写第三方库,自然自己也可以实现一个这样的功能,大部分情况下,我很多代码都是直接调用我自己实现的一个GetUserAgentCS 类,直接就可以获取一个随机请求头了,直接写函数库,才牛逼舒服, 这个我也会在下面介绍如何编写函数库。
自己编写第三方库:
不知道你们写代码的框架是怎样的,面向过程还是面向对象? 对于一次性的代码,就简单的编码就行了,如果你觉得这个代码它可以会在很多的地方用得到,可以重复使用,那么你就可以使用类的方式,去编写这个代码,那么在其他的文件中,你就可以直接调用你的写这个文件,直接调用你写的class类中的各种方法,而我也是这样实现的一个随机请求头的一个第三方库, 如下:
import random
import csv
class GetUserAgentCS(object):
"""
调用本地请求头文件, 返回请求头
"""
def __init__(self):
with open('D://pyth//scrapy 项目//setting//useragent.csv', 'r') as fr:
fr_csv = csv.reader(fr)
self.user_agent = [str(i[1]) for i in fr_csv]
def get_user(self):
return random.choice(self.user_agent)
useragent文件如下:
1,"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36"
2,"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.17 Safari/537.36"
3,"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (X11; NetBSD) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36"
4,"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36"
5,"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36"
-------
------- # too much
100...
代码很简单的,读取本地的csv文件,然后random一个出去就行了,那现在就有人问我,你这个文件怎么来的, 很简单啊,自然就有方法了,待会在下一个模块我会讲到,在这里,我们只需要编写一个GetUserAgentCS类就可以,代码可以直接抄我上面的,然后保存为get_useragent.py 就可以了,然后你把这个包文件放在你自己爬虫文件夹的地方,然后这样调用:
from get_useragent import GetUserAgentCS
headers = {}
ua = GetUserAgentCS().get_user()
headers['user-agent'] = ua
return headers
如果你在这个调用GetUserAgentCS 不成功, 或者底下会出现红色的波浪线, 那么就是你没有设置当前工作环境,你只需要这么设置(设置你的爬虫文件夹):
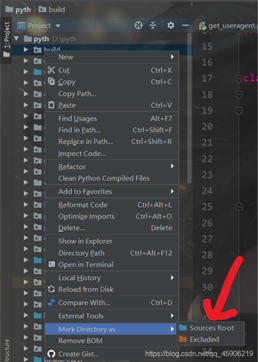
你需要点击 Sources Root 就可以了!
使用第三方库 fake-useragent:
这是一个别人已经写好的第三方库,你需要安装然后调用API 就可以了, 它可以获取各种的请求头,唯一的缺点就是 请求不稳定,有的时候网络波动就可能导致获取不成功,用于Scrapy中,不是很舒服,所以我在这个包的基础上,编写了如上我自己的包,至于请求头的数据怎么来的, 就是在这个包运行正常时候,一直更改user-agent,然后不断的请求 http://httpbin.org/user-agent 然后不断的保存数据,写入本地文件就可以了。
我们还是讲一讲这个包的使用方式吧!
安装
pip install fake-useragent
你可以 pip list 查看一下 是否安装成功
使用方式
from fake_useragent import UserAgent
headers= {'User-Agent':str(UserAgent().random)}
r = requests.get(url, headers=headers)
- UserAgent().random 可以获取任意浏览器的请求头
- UserAgent().Chrome 可以获取谷歌浏览器的请求头
- UserAgent().firefox 可以获取火狐浏览器的请求头
这个时候,直接用random就可以了,简单。
读取内存数组:
这个时候就有很多人说, 我就换个请求头而已,需要这么麻烦吗? 当然,自然有简单的方式,只不过每次都需要复制来用,不是很方法,具体如下:
ua = ["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36"
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.17 Safari/537.36"
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (X11; NetBSD) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36"]
预先把请求头放入数组里面,然后用就可以了。
import random
ua = [.....]
r = requests.get(url, headers={"user-agent":random.choice(ua)})
教你用三种方式设置随机请求头, 爬虫设置请求头(user-agent)是必然的,那如何生成一个随机请求头这个也是我们爬虫必须掌握的, 读完本篇文章你就可以轻松掌握 !
js