���ĵ����ּ�ͼƬ��Դ������,����ѧϰ������ʹ��,�������κ���ҵ��;,���������뼰ʱ��ϵ��������������
����������Դ������STUDIO��������������
Python���������û���Ϊ������Ƶ�����ַ
https://www.bilibili.com/video/BV1yp4y1q7ZC/
���ݻ�ȡ�����ݷ����е���Ҫ��һ�������ݻ�ȡ��;�����ֶ������������Ϣ��ը��ʱ�������ݻ�ȡ�Ĵ���Ҳ��Խ��ԽС�������ˣ���Ȼ�кܶ�С���������λ�ȡ������Ϣ���˴���������Ȳ����а��һ���ġ��������¡�Ϊ�����ְ��ֽ�����λ�ȡ�����յ��Ӿ絯Ļ���ݡ�

Ѱ�ҵ�Ļ��Ϣ
�����յĵ�Ļ������ͨ��.z��ʽ��ѹ���ļ����ڣ���ͨ�����²����ҵ���Ļurl, tvid�б����ٻ�ȡѹ���ļ������ù��߶Ի�ȡ��ѹ���ļ����н�ѹ���������洢��������
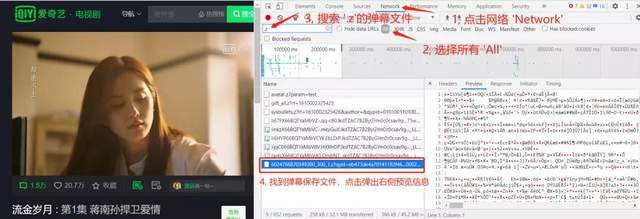
���ԣ�ʵ�ж�ҳ��ȡ����Ҫ����url���ɣ�����url����ѭ������ȡ�������ݡ�
�˵�Ļ�ļ�url��ַΪ
https://cmts.iqiyi.com/bullet/93/00/6024766870349300_300_1.z
����tvid = 6024766870349300
url������ʽΪ
url ='https:
//cmts.iqiyi.com/bullet/{}/{}/{}_300_{}.z'���е�һ����ڶ���������������tvid��3��4λ������1��2λ��������������Ϊtvid�����ĸ�������Ϊ���ļ���ţ��䲻��һ����������������ݲ�ͬ�ĵ��Ӿ��в�ͬ���������
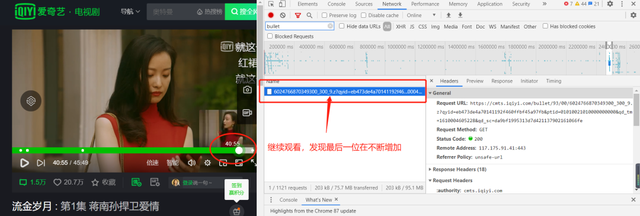
��ȡ��Ļ�ļ�
�������������ͨ��urlֱ��������ȡ�����
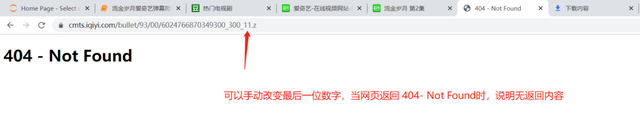
������ַ�ɻ�ȡ��Ļ���ݵ�ѹ���ļ��ļ���
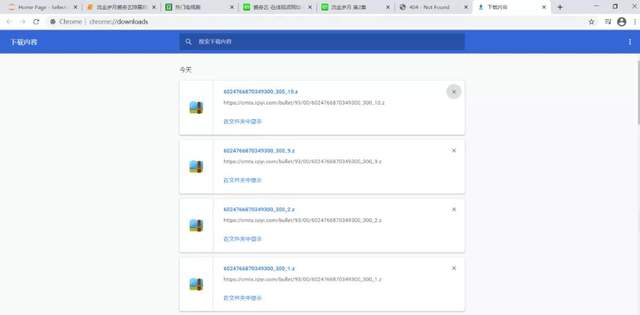
���ý�ѹ/ѹ����zlib������������ѹ���ļ����н�ѹ�鿴��
import zlib
from bs4 import BeautifulSoup
with open(r"C:\Users\HP\Downloads\6024766870349300_300_10.z", 'rb') as fin:
content = fin.read()
btArr = bytearray(content)
xml=zlib.decompress(btArr).decode('utf-8')
bs = BeautifulSoup(xml,"xml")
bs
���

���tvidֻҪ��þ������ɻ�ȡ�õ��Ӿ�ĵ�Ļ�ļ����ݡ�
import zlib
from bs4 import BeautifulSoup
import pandas as pd
import requests
def get_data(tv_name,tv_id):
"""
��ȡÿ����tvid
:param tv_name: ��������1������2��...
:param tv_id: ÿ����tvid
:return: DataFrame, ���յ�����
"""
base_url = 'https://cmts.iqiyi.com/bullet/{}/{}/{}_300_{}.z'
# �½�һ��ֻ�б�ͷ��DataFrame
head_data = pd.DataFrame(columns=['uid','contentsId','contents','likeCount'])
for i in range(1,20):
url = base_url.format(tv_id[-4:-2],tv_id[-2:],tv_id,i)
print(url)
res = requests.get(url)
if res.status_code == 200:
btArr = bytearray(res.content)
xml=zlib.decompress(btArr).decode('utf-8') # ��ѹѹ���ļ�
bs = BeautifulSoup(xml,"xml") # BeautifulSoup��ҳ����
data = pd.DataFrame(columns=['uid','contentsId','contents','likeCount'])
data['uid'] = [i.text for i in bs.findAll('uid')]
data['contentsId'] = [i.text for i in bs.findAll('contentId')]
data['contents'] = [i.text for i in bs.findAll('content')]
data['likeCount'] = [i.text for i in bs.findAll('likeCount')]
else:
break
head_data = pd.concat([head_data,data],ignore_index = True)
head_data['tv_name']= tv_name
return head_data
��ȡtvid
������ͨ��tvid��ȡ���˵�Ļ�ļ����ݣ���ô��λ�ȡtvid�ֱ����һ�����⡣Ī�������Ǽ���������ֱ��Ctrl + F����tvid
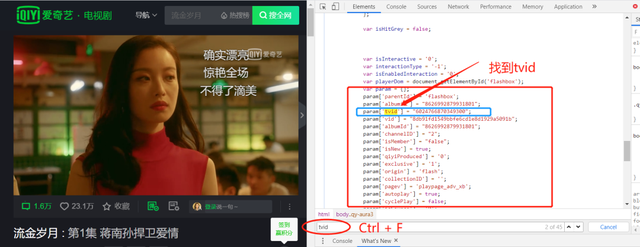
��˿���ֱ�Ӵӷ��ؽ����ͨ���������ʽ��ȡtvid��
from requests_html import HTMLSession, UserAgent
from bs4 import BeautifulSoup
import re
def get_tvid(url):
"""
��ȡÿ����tvid
:param url: ������ַ
:return: str, ÿ����tvid
"""
session = HTMLSession() #����HTML�Ự����
user_agent = UserAgent().random #�����������ͷ
header = {"User-Agent": user_agent}
res = session.get(url, headers=header)
res.encoding='utf-8'
bs = BeautifulSoup(res.text,"html.parser")
pattern =re.compile(".*?tvid.*?(\d{16}).*?") # �����������ʽ
text_list = bs.find_all(text=pattern) # ͨ���������ʽ��ȡ����
for t in range(len(text_list)):
res_list = pattern.findall(text_list[t])
if not res_list:
pass
else:
tvid = res_list[0]
return tvid
�ɴ�����tvid����ÿһ������һ��tvid���ж��ټ����Ӿ�Ϳ��Ի�ȡ���ٸ�tvid����ô���������ˣ���ȡtvidʱ����ͨ��url�������ӷ��ؽ���л�ȡ����ÿһ����url�ָ���λ�ȡ�ء�
��ȡÿ��url
ͨ��Ԫ��ѡ�߶�λ������ѡ����Ϣ��ͨ����ģ���������ȡ��̬������Ϣ��
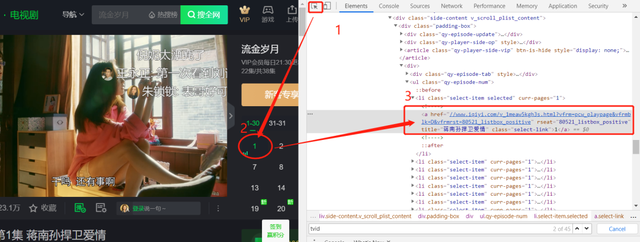
��С����˵������ֱ��ֱ�Ӵӷ��������л�ȡ��href��ַ����������Լ����ֳ����¡�
�ƶ�����Ժ�õ��Ľ����href="javascript:void(0);" rel="external nofollow" ����˽����һ����ķ���֮һ��������ģ���������ȡjs��̬������Ϣ��
def get_javascript0_links(url, class_name, class_name_father, sleep_time=0.02):
"""
Seleniumģ���û������ȡurl
:param url: Ŀ��ҳ��
:param class_name: ģ��������
:param class_name_father�� ģ�������࣬����Ϊclass_name�ĸ���
:param sleep_time: ����ҳ����˵�ʱ��
:return: list, ���classΪclass_name��ȥ�ij�����
"""
def wait(locator, timeout=15):
"""�ȵ�Ԫ�ؼ������"""
WebDriverWait(driver, timeout).until(EC.presence_of_element_located(locator))
options = Options()
# options.add_argument("--headless") # ����,������Ҫ�鿴�������ݣ����Խ�����ע�͵�
driver = webdriver.Chrome(options=options)
driver.get(url)
locator = (By.CLASS_NAME, class_name)
wait(locator)
element = driver.find_elements_by_class_name(class_name_father)
elements = driver.find_elements_by_class_name(class_name)
link = []
linkNum = len(elements)
for j in range(len(element)):
wait(locator)
driver.execute_script("arguments[0].click();", element[j]) # ģ���û����
for i in range(linkNum):
print(i)
wait(locator)
elements = driver.find_elements_by_class_name(class_name) # �ٴλ�ȡԪ�أ�Ԥ��StaleElementReferenceException
driver.execute_script("arguments[0].click();", elements[i]) # ģ���û����
time.sleep(sleep_time)
link.append(driver.current_url)
time.sleep(sleep_time)
driver.back()
driver.quit()
return link
if __name__ == "__main__":
url = "https://www.iqiyi.com/v_1meaw5kgh3s.html"
class_name = "qy-episode-num"
link = get_javascript0_links(url, class_name, class_name_father="tab-bar")
for i, _link in enumerate(link):
print(i, _link)
������
������ͨ�������������в��贮��
def main(sleep_second=0.02):
url = "https://www.iqiyi.com/v_1meaw5kgh3s.html"
class_name = "select-item"
class_name_father = "bar-li"
links = get_javascript0_links(url, class_name, class_name_father)
head_data = pd.DataFrame(columns=['tv_name','uid','contentsId','contents','likeCount'])
for num, link in enumerate(links):
tv_name = f"��{num+1}��"
tv_id = get_tvid(url=link)
data = get_data(tv_name,tv_id)
head_data = pd.concat([head_data,data],ignore_index = True)
time.sleep(sleep_second)
return head_data
��ȡ�������ݽ�����£�
>>> data = main()
>>> data.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 246716 entries, 0 to 246715
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 tv_name 246716 non-null object
1 uid 246716 non-null object
2 contentsId 246716 non-null object
3 contents 246716 non-null object
4 likeCount 246716 non-null object
dtypes: object(5)
memory usage: 9.4+ MB
"""
>>> data.sample(10)

����ͼ�ȷִ�
�������ķִʿ�jieba�ִʣ���ȥ�������ʡ�
def get_cut_words(content_series):
"""
:param content_series: ��Ҫ�ִʵ�����
:return: list, ���classΪclass_name��ȥ�ij�����
"""
# ����ͣ�ôʱ�
import jieba
stop_words = []
with open("stop_words.txt", 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# ���ӹؼ���
my_words = ['����', '��ʫʫ', '����', '������', '�µ���']
for i in my_words:
jieba.add_word(i)
# �Զ���ͣ�ô�
my_stop_words = ['������','��������', '���']
stop_words.extend(my_stop_words)
# �ִ�
word_num = jieba.lcut(content_series.str.cat(sep='��'), cut_all=False)
word_num_selected = [i for i in word_num if i not in stop_words and len(i)>=2] # ����ɸѡ
return word_num_selected
��ͼ
�������������ͼ��stylecloud���ӻ���Ļ�����
import stylecloud
from IPython.display import Image
text1 = get_cut_words(content_series=data.contents)
stylecloud.gen_stylecloud(text=' '.join(text1), collocations=False,
font_path=r'C:\Windows\Fonts\msyh.ttc',
icon_name='fas fa-rocket',size=400,
output_name='��������-����.png')
Image(filename='��������-����.png')
js