关于这样的定义方式其实我们早就接触过很多了,只不过之前我们的写的时候使用一个循环,而且设置的不是偏置(bias)而是权重(weight),所以相关的内容建议大家看一下我的LeNet-1989这篇博客,里面对这个代码的含义有简单的介绍。
由于激活函数使用的是ReLU函数,这个函数是没有上界的,这很有可能导致最后通过激活函数输出的数据分布过于极端。与此同时,论文的作者发现,对数据进行Normalize处理将有利于提高模型的泛化性能,降低过拟合的风险。所以在论文中作者提出了一个标准化方法,就是这里的LRN了。标准化使用的计算方法如下所示:
\[b^i_{x,y}=a^i_{x,y}/(k+{\alpha}\sum^{min(N-1,i+n/2)}_{j=max(0,i-n/2)}(a^j_{x,y})^2)^{\beta}
\]
这个公式中的各个参数的含义其实比较简单,但是由于博客园这边的文字上下标编辑实在是有点emmmmm,所以这边我就简单写写,如果有什么疑问的话还是直接参照论文来看吧:
这个公式的形象化理解就是,在对某一个像素点进行标准化时,是使用它前后的n/2共n范围内的特征图的对应位置的像素点作为标准,来进行标准化的计算。这一层中没有可训练参数,而且所做的就是十分简单的索引切片以及简单的运算,所以实际上没有什么复现难度,虽然这个基本上是整篇下来唯一一个需要自己写的类┓('?')┏。那么下面我们就把代码贴上来呗:
class LRN(nn.Module):
def __init__(self, in_channels: int, k=2, n=5, alpha=1.0e-4, beta=0.75):
super(LRN, self).__init__()
self.in_channels = in_channels
self.k = k
self.n = n
self.alpha = alpha
self.beta = beta
def forward(self, x):
tmp = x.pow(2)
div = torch.zeros(tmp.size()).to(device)
for batch in range(tmp.size(0)):
for channel in range(tmp.size(1)):
st = max(0, channel - self.n // 2)
ed = min(channel + self.n // 2, tmp.size(1)-1)+1
div[batch, channel] = tmp[batch, st:ed].sum(dim=0)
out = x / (self.k + self.alpha * div).pow(self.beta)
return out
这部分如果大家有python基础的话还是蛮简单的,并且虽然这个系列的博客是面向小白的,不过大家跟着玩了这么久,肯定python也学了个七七八八了,所以这部分就不详解了,如果有不明白的地方,直接搜一下python的切片操作即可,基本上这部分代码里面初学者难以理解的就是里面的切片操作而已。
接下来我们需要做的就只是调用这个类的初始化函数来进行对象的定义以及初始化即可,这个就之后完整代码里面说吧。
S1层
在这里论文作者又搞出一个骚操作,那就是让池化的核在移动的时候与之前发生重叠。具体来说,就是使用下面的参数:
选用的池化方式为最大化池化MaxPool。论文作者说,这么搞能够降低过拟合的风险(我读书不多,你可别骗我)。关于这一部分我因为读的论文啥的还不够多,所以关于这样做为什么能降低过拟合风险,我也不是太清楚,如果评论区有大佬能够指点一下那就太好了。
经过S1的池化操作之后,输出的特征图的尺寸变为[96, 27, 27]
C2层
从这里开始,原论文就开始把模型往两个GPU上面搬了,但是因为咱们其实手头上的GPU大多数都足够用,并且及时GPU不够用,网上也有许多在线的GPU训练平台可以免费使用一些GPU进行训练,因此在这里我们不看论文上的图,而是看我上面给出的稍微清晰一点的彩图。其实读的时候就是将论文里面给出的卷积核的数量加倍就完事了,所以这里结合着论文以及上面的一张彩图来看一下C2层的具体参数:
-
in_channels: 96
-
out_channels: 256
-
kernel_size: 5
-
stride: 1
-
padding: 2
在初始化时,权重的初始化方法和C1一致(应该说所有的权重初始化方法都是一致的),然后偏置是全部初始化为1
经过这样的卷积处理,输出的特征图的尺寸变为[256, 27, 27]
根据论文的描述,在C2之后也是有ReLU激活函数的。
N2层
根据论文介绍,在C2层使用激活函数激活之后,也需要使用LRN进行数据的标准化处理,由于我们之前已经介绍了LRN层的类代码内容,所以在这里不做过多的描述,直接调用一下初始化函数即可。
S2层
在经过N2层处理结束之后,我们需要对结果进行最大化池化。池化的参数和S1的参数是完全相同的,经过S2层之后,特征图的尺寸变为[256, 13, 13]
C3层
C3层就是我们之前经常接触的非常常见的尺寸的卷积层啦,所以在这里我们直接给出卷积层的参数:
-
in_channels: 256
-
out_channels: 384
-
kernel_size: 3
-
stride: 1
-
padding: 1
初始化的时候,偏置全部初始化为0。
输出的特征图的尺寸为[384, 13, 13]。在C3之后也是有ReLU激活函数的。
C4层
讲道理觉得,偷个懒真的是香啊,这么省事我真是谢谢论文作者啊233333。
-
in_channels: 384
-
out_channels: 384
-
kernel_size: 3
-
stride: 1
-
padding: 1
初始化的时候,偏置全部初始化为1。
输出特征图的尺寸为[384, 13, 13]。在C4之后同样有ReLU激活函数。
C5层
继续摸鱼233333
-
in_channels: 384
-
out_channels: 256
-
kernel_size: 3
-
stride: 1
-
padding: 1
初始化的时候,偏置全部初始化为1。
输出特征图的尺寸为[256, 13, 13]。在C5层之后同样有ReLU激活函数。
S3层
继续摸······啊摸不得了,差点就又把卷积层的那些参数粘过来了23333。
在这里使用的基本的池化方法和S1和S2是完全一致的,所以就不说参数啦。输出的特征图的尺寸为[256, 6, 6]。
F1层
接下来的部分,论文中提到进入全连接的部分,应该说一直到VGG,网络都还是基本的“卷积+全连接”的模式,直到后面有论文提出,全连接就是个垃圾,我到最后都用池化一直搞到最后,性能也其实挺好(我忘记是全卷积网络还是什么网络提出来的了,等到我后面有空再去瞅瞅┓('?')┏)。
AlexNet指出,全连接层这边有4096个神经元,考虑到从上层下来的特征图的尺寸为[256, 6, 6],而全连接层的输入要求图片的维度不考虑batch_size应该是个一维的,因此我们需要使用view操作对输入进行一个处理,变成[batch_size, 256*6*6]这样的形式,当然啦这个操作最好放在forward里面,这里就是提一下让大家注意一下。
因此F1的基本参数应该是下面的样子:
-
in_features: 256*6*6
-
out_features: 4096
初始化的时候,偏置全部初始化为1,并且所有的全连接层,偏置都是初始化为1。
在F1层之后是要跟一个ReLU激活函数的。
并且在论文里面指出,在F1和F2后面有Dropout操作,这个操作对于降低模型的过拟合风险真的是有奇效,具体内容等到之后和ReLU等一些骚操作一起说吧,这里大家先了解一下要用Dropout
F2层
这里也让我偷一下懒好啦( ̄▽ ̄)
-
in_features: 4096
-
out_features: 4096
同样的,在F2之后也有ReLU以及Dropout。
F3层
继续摸鱼,你能拿我咋办┓('?')┏
-
in_features: 4096
-
out_features: 1000
这里就只有一个ReLU函数啦,再往后我们就直接输出各个分类的计算结果了。
那么到这里,网络的基本结构就介绍完成了,接下来,我们需要简单介绍一下激活函数和dropout操作,然后我们就可以着手构建AlexNet的基本代码啦
ReLU激活函数
不同于之前使用的Sigmoid以及Tanh函数,在AlexNet中使用的是ReLU函数,这个函数的公式如下所示:
\[ReLU(x)=max(0,x)
\]
这个函数有一些比较有趣的东西(有好有坏),我们一个一个来说:
总之ReLU函数就是有上面的或好或坏的基本特点啦,而且因为这个函数非常常用,所以在Pytorch中已经有现成的代码,我们直接安安稳稳地做个调包侠就完事了,做个咸鱼它不香么┓('?')┏。具体的调用方法和我们之前的激活函数的调用时完全一致的,在这里就不赘述了,有空自己去看看官方文档啦。
Dropout
这篇文章也是比较早地在深度模型中使用Dropout机制的论文了,虽然首次提出并不是这篇,我记得好像是Hitton老爷子的论文来着?总之原文如果大家有兴趣的话可以去找来读一读,在这里我主要为那些没有接触过的萌新小伙伴们简单一下机制以及效果,同样的,参考的博客链接我会放在最后,大家可以去点个关注啥的。
在介绍Dropout之前我们还是先来看一下传统的全连接网络:

从上面这张图可以看到,对于一个完整的全连接网络来说,里面参数太多,密密麻麻的一大片简直就是密集恐惧症的福音,无论是从计算成本还是从过拟合风险来说,都是相对来说比较差的。如果大家稍微接触过一些神经研究的话可能会知道,实际上在人的神经系统中,神经又不是全部一个一个地密密麻麻连在一起的,有些神经其实并不是相互连通的。因此,如果我们在训练过程中指定一个概率p,让每一个神经元都以p的概率被“杀死”,也就是不参与运算,那不就既减少了计算量,又降低了参数量,岂不美哉?这个思想实际就是Dropout做的事情。下图就是我们使用dropout后在某一个训练轮次中的全连接网络的示意:
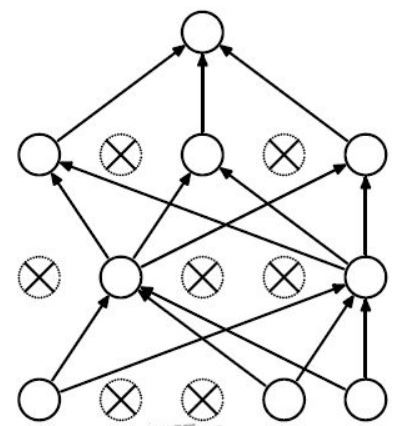
可以看到,参数量少了,而且从网路的拓扑结构上看也和之前不太一样了。
这样做的好处在我看来一共有以下几个:
-
仿生学意义:较好地模拟了真实神经之间的连接情况。
-
拓扑结构:改变了原有的拓扑结构,并且由于每一轮训练得到的实际网络结构都是由概率得到的,因此拓扑结构更加复杂,有可能会学到更加复杂的输入特征。
-
减少神经元之间的共适应关系:在上一条中提到,神经元在每一个训练epoch中是否存在取决于概率p,因此在不同的训练epoch之间,某一个神经元可能有时候在有时候不在,这就导致在每次训练中,神经元之间的依赖关系并不是那么强,自然就降低了过拟合的风险。
-
集成学习思想:在第二条中提到,每一轮epoch中的网络结构由于概率p的存在,实际上的连接情况是各有不同的,也就是说,最后训练得到的网络结构,实际上和训练了很多个不同的网络结构然后再堆到一起是差不多的。如果大家接触过集成学习的话应该会对这个思想感到比较熟悉,集成学习实际上就是把一大堆的分类器放在一起,然后在训练过程中不断修改各个分类器的得分权重,然后进行各自的参数调整。经过Dropout训练后的模型也相当于有许多个模型集成在一起进行结果的判断,而且当训练轮次epochs足够多的时候,相当于训练了2^n个模型,n为神经元个数,通过这么多模型进行共同判断,自然可以将过拟合风险显著降低。
同样的,因为Dropout在现在的深度学习模型中非常常见,因此也在Pytorch中有现成的,调用方法也很简单,还是请大家自行翻阅一下Pytorch的官方文档看一下怎么用吧。相信跟着这个系列的博客的小伙伴们已经能比较熟练地阅读Pytorch的官方文档了吧。
训练策略
除了在网络的具体结构之外,AlexNet在训练使用的一些小策略上,也和之前的LeNet-5以及其他的传统机器学习模型有一些不同的地方。
梯度下降方式
在LeNet-5以及LeNet-1989中,论文作者使用的都是基于单个样本的简单SGD,具体的内容如果大家不太清楚的话,可以自行查阅相关的论文,或者是看一下我之前的博客(这应该不算打广告吧┓('?')┏)。然后呐,在AlexNet中作者基于单样本以及简单SGD进行了两个方面的改进:
-
单样本改进——mini-batch:就如同我之前在LeNet-5的复现博客中提到的,基于所有样本的梯度下降如果看成是基于整个样本空间的期望的话,那么单样本的SGD就相当于从样本空间随机取得一个样本,把这个值作为期望的估计值。这样确实是引入了足够的随机性,但是问题在于,这也太粗糙了,随机过了头就很可能导致参数更新方向完全错了。其实仔细想一想我们平常如果想要获得某个数值的估计,一般都是取平均嘛,这样既有一定的随机性,同时又可以保证大致的方向是和整体期望近似相同的(好歹人家也是期望的无偏估计量嘛┓('?')┏)。而这也是这篇论文中所使用的mini-batch思想。在AlexNet中,由于使用的训练集有1.2millon张图片,因此mini-batch稍微取大一点点,对于随机性的影响并不是很大,在论文中使用的mini-batch为128。
-
简单SGD改进——带动量的SGD:之前我们使用的SGD就是很简单的利用所在点的函数梯度(导数)来作为参数的更新依据。从更新方法上来看,如果我们出现了导数为0的点(驻点),那么SGD就会在这个点停止更新。如果这个点是极值点倒是还算运气好,但是当出现像下面的函数图像的时候,你就会怀疑人生: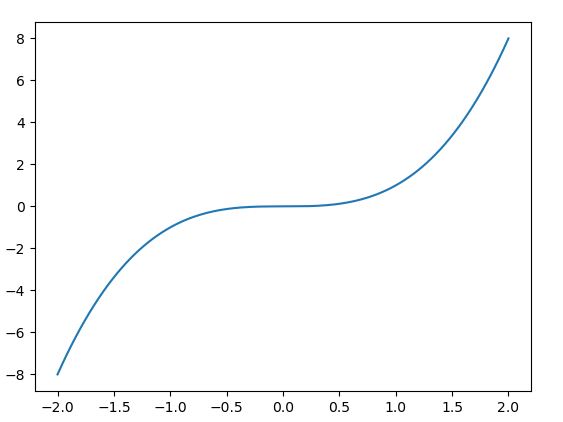
这个函数图像实际上是三次曲线,为了让大家看得更清楚所以把图片稍微压扁了一点点。可以发现在x=0的邻域内,函数的图像十分平缓,这也就意味着函数在这附近的梯度很小,那基本上也就没办法被正常更新(看一下[-0.5, 0.5]的区间,导数基本上是0啊),同时(0, 0)这个点并不是极值点(事实上三次曲线没极值点┓('?')┏),也就是发生了“明明没训练好,但是模型自己就停止训练了”的尴尬问题。这个玩意在DeepLearning里面好像是叫鞍点问题。虽然举的例子是一个没有极值点的不太合适的例子,但是事实上在实际我们经常训练的其他的假设函数模型中,部分邻域内函数图像是这种情况的多了去了,这也是普通的SGD效果在复杂问题中一般很差的原因。因此在AlexNet中,作者使用了带有动量的SGD。带动量的SGD,通俗一点的理解就是带初速度的加速运动(是不是有高中物理内味儿了),具体的公式以及说明建议大家查阅一下相关的资料,我会把我读过的博客放在最后的链接中。
学习率的下降
不同于之前LeNet-5的直接按照epoch数来认为设置学习率的下降,AlexNet中将训练函数中的错误率作为评价的指标,当错误率停止下降的时候,就对学习率进行下降。这样根据某一指标进行学习率的动态下降,我觉得其实还行,就是稍微麻烦了一点。
之前我们提到过,Pytorch专门提供了类用来方便我们的学习率下降,这里我们既可以像之前的LeNet-5一样,通过在优化器中的param_group字典来遍历参数进行人工修改,也可以直接调用专门的类来进行调整。为了让大家知道有这么些类能够用来调整学习率,所以在这里我们直接用现成的。由于我们之前已经导入过torch.optim了,所以这里我们直接用:
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.1, patience=1)
为大家解释一下这段代码:首先在torch.optim中存在这样一个包lr_scheduler,里面是我们所有的和学习率衰减有关的类,比如指定epoch下降、指数衰减以及这个指定参数衰减。参数含义在下面简单介绍一下啦:
而在使用scheduler的时候,实际上和使用optimizer差不多。我们需要在optimizer进行step操作之后,对这个scheduler进行step操作,并将我们的正确率作为参数传给step(废话,不传参数怎么知道拿啥作指标┓('?')┏)。大致的伪代码看一下下面啦:
optimizer.step()
with torch.no_grad():
计算分类正确的个数acc
accRate = acc / 验证集样本数
scheduler.step(accRate)


