import csv
import pyinotify #这个包只支持linux,如果是window系统可以使用watchdog,一个原理及写法
import time
import requests
import json
import datetime
import pandas as pd
CORPID = "******" #企业微信id
SECRET = "*******" #企业微信密钥
AGENTID = 1000041 #企业微信端口
multi_event = pyinotify.IN_CREATE #只对create这个动作做监控
wm = pyinotify.WatchManager()
#继承ProcessEvent后,对process_IN_CREATE方法重写
class MyHandler(pyinotify.ProcessEvent):
def send_msg_to_wechat(self, content):
record = '{}\n'.format(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
s = requests.session()
url1 = "https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid={0}&corpsecret={1}".format(CORPID, SECRET)
rep = s.get(url1)
record += "{}\n".format(json.loads(rep.content))
if rep.status_code == 200:
token = json.loads(rep.content)['access_token']
record += "获取token成功\n"
else:
record += "获取token失败\n"
token = None
url2 = "https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token={}".format(token)
header = {
"Content-Type": "application/json"
}
form_data = {
"touser": "@all",
"toparty": " PartyID1 | PartyID2 ",
"totag": " TagID1 | TagID2 ",
"msgtype": "text",
"agentid": AGENTID,
"text": {
"content": content
},
"safe": 0
}
rep = s.post(url2, data=json.dumps(form_data).encode('utf-8'), headers=header)
if rep.status_code == 200:
res = json.loads(rep.content)
record += "发送成功\n"
else:
record += "发送失败\n"
res = None
return res
def process_IN_CREATE(self, event):
try:
if '_spark_metadata' in event.pathname or '.crc' in event.pathname:
pass
else:
print(event.pathname)
f_path = event.pathname
#此处坑,streaming那边生成文件还没写入数据就会触发该任务,不sleep打开的是空白文件
time.sleep(5)
df = pd.read_csv(r'' + f_path, encoding='utf8', names=['value'], sep='/')
send_str = df.iloc[0, 0].replace('\\', '').replace(',"before":null}', '').replace('"','')
print(send_str)
self.send_msg_to_wechat('中间库预警:' + send_str)
except:
pass
handler = MyHandler()
notifier = pyinotify.Notifier(wm,handler)
wm.add_watch('/tmp/filesink/',multi_event)
notifier.loop()
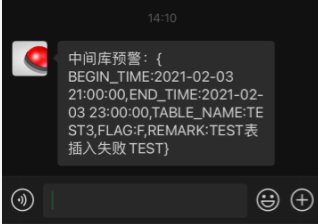
微信端消息如下:
四、问题点
还有下面几个问题还没实现,有思路还请随时评论私信交流,感谢
学习交流,有任何问题还请随时评论指出交流。
