一 为pod分配cpu,内存以及其他的资源
1.1 创建一个pod,同时为这个pod分配内存以及cpu的资源请求量
apiVersion: v1
kind: Pod
metadata:
name: requests-pod
spec:
containers:
- image: busybox
command: ["dd", "if=/dev/zero", "of=/dev/null"]
name: main
resources:
requests:
cpu: 200m
memory: 10Mi
- 如下配置的容器里面添加了requests字段,包括cpu以及内存的请求量
- cpu:200m的含义是容器最少可使用宿主机的200毫核(即一个cpu核心时间的1/5)
- memory:10Mi的含义是该容器使用10M的内存
1.2 来验证一下这个pod内的容器使用的cpu核数
Mem: 2904756K used, 977004K free, 179080K shrd, 0K buff, 2061448K cached
CPU: 4.4% usr 21.6% sys 0.0% nic 73.5% idle 0.0% io 0.0% irq 0.0% sirq
Load average: 1.04 1.07 1.05 2/424 15
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
1 0 root R 1300 0.0 2 25.0 dd if /dev/zero of /dev/null
6 0 root S 1308 0.0 1 0.0 top
11 0 root R 1308 0.0 3 0.0 top
[root@node01 Chapter14]# cat /proc/cpuinfo| grep "processor"| wc -l
4
- 由于这个机器是一个四核的虚拟机,,所有这个进程只能占据全部核数的1/4
- 可以看到通过这个参数,让容器最少可以使用20%,却不是只能使用20%
1.3 了解调度器如何判断一个pod是否适合调度某个节点
首先调度器在调度的适合并不关注各类资源在当前时刻的实际使用量,而只关心节点上pod的资源的申请量之和,原因是如果是看集群所有资源的实际使用总和的话,那么之前那些资源分配的额度就有可能达不到了
用一张图来看下所描述的现象
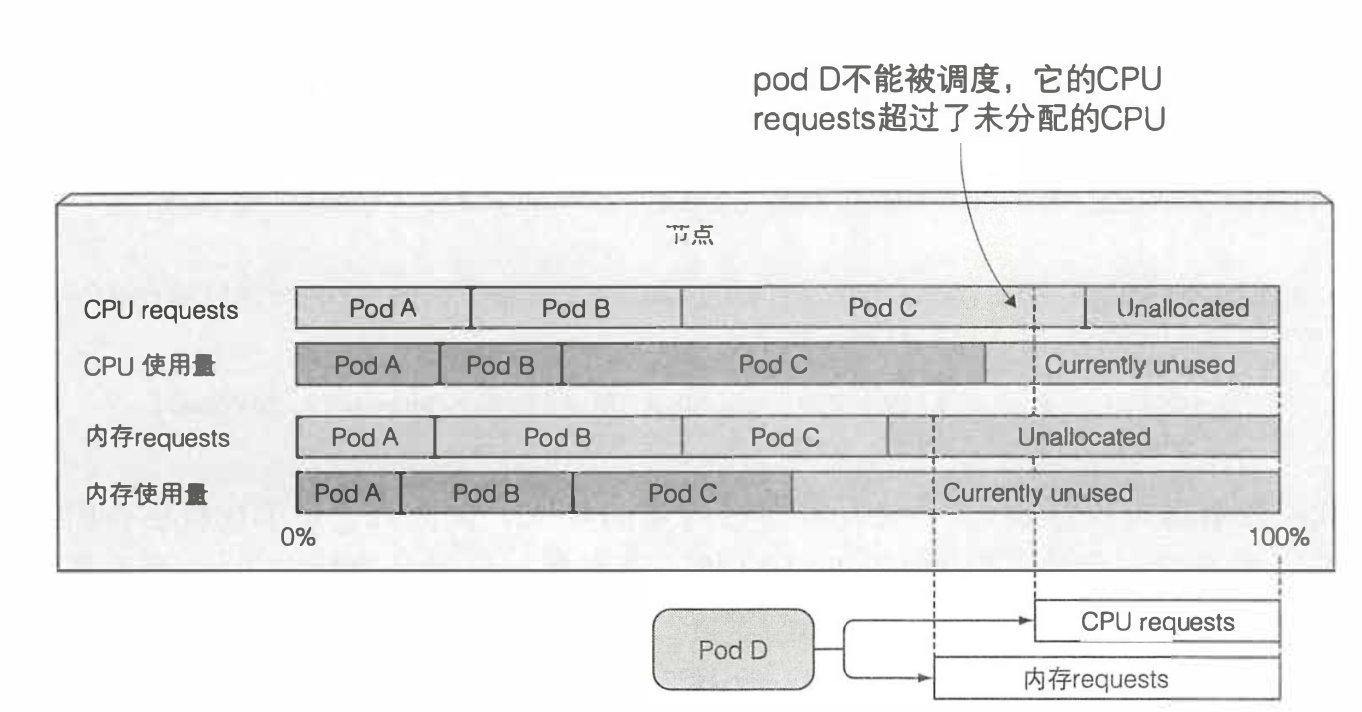
- 如下图所示,节点上CPU的申请量是80%,但是实际使用量只有70%,我们的podD的申请量是25%
- 若按照实际使用量来看,pod还是可以被调度上去的,但是实际上已经无法进行调度了,因为它是根据资源的申请量来计算的
1.4 调度器如何通过pod requests为其选择最佳节点
之前了解过调度器的调度原理的时候,首先会排除那些不满足需求的节点,之后会有一个LeastRequestPriority和MostRequestPriority,前者优先级将pod调度到请求量少的节点,而后者则是优先将pod调度到请求资源较多的节点,一般自家建设的kubernetes集群都倾向于使用前面的策略,这样的话负载均衡会好点,但是如果是运行云基础设施上面的话,使用后者的话,会省去一笔很大的开支
1.5 查看节点资源总量
Name: node01
......
InternalIP: 172.16.70.4
Hostname: node01
Capacity:
cpu: 4
ephemeral-storage: 8178Mi
hugepages-2Mi: 0
memory: 3881760Ki
pods: 110
Allocatable:
cpu: 4
ephemeral-storage: 7717729063
hugepages-2Mi: 0
memory: 3779360Ki
pods: 110
......
- 红色字体显示的节点的资源总量
- 绿色的字体显示的可分配给pod的资源量
- 之所以系统总量和可分配给pod的总量,是因为要预留一些资源给系统的pod
1.6 创建一个cpu请求量较大的pod,观察能否创建成功,如果失败又是如何
[root@node01 Chapter14]# k run request-pod-3 --image=busybox --restart Never --requests='cpu=4,memory=20Mi' -- dd if=/dev/zero of=/dev/null
pod/request-pod-3 created
[root@node01 Chapter14]# k get po
NAME READY STATUS RESTARTS AGE
request-pod-2 1/1 Running 0 3m4s
request-pod-3 0/1 Pending 0 3s
requests-pod 1/1 Running 0 4h52m
[root@node01 Chapter14]# k describe po request-pod-3
Name: request-pod-3
Namespace: default
Priority: 0
Node: <none>
Labels: run=request-pod-3
Annotations: <none>
Status: Pending
IP:
IPs: <none>
Containers:
request-pod-3:
Image: busybox
Port: <none>
Host Port: <none>
Args:
dd
if=/dev/zero
of=/dev/null
Requests:
cpu: 4
memory: 20Mi
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-tzwwt (ro)
Conditions:
Type Status
PodScheduled False
Volumes:
default-token-tzwwt:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-tzwwt
Optional: false
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 13s (x2 over 13s) default-scheduler 0/3 nodes are available: 3 Insufficient cpu.
- 创建一个超级大cpu请求量之后,集群的任何节点都无法满足这个pod
- 如红色字体显示,无法调度到任何的节点,因为任何节点都没有足够的cpu可以分配