-- 创建表
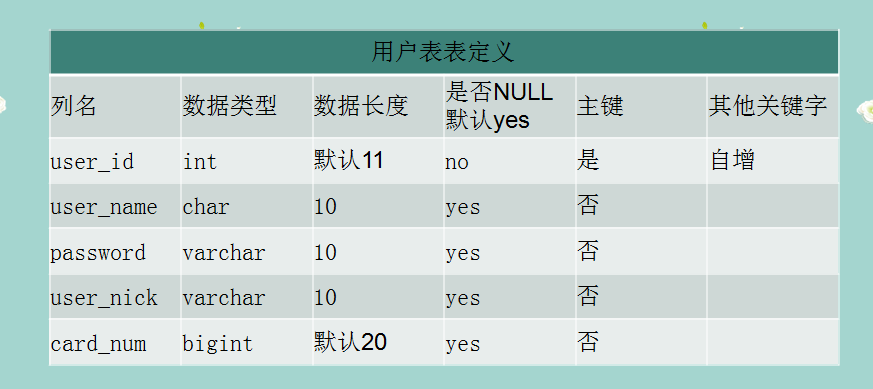
CREATE TABLE user_info (
user_id INT NOT NULL AUTO_INCREMENT,
user_name CHAR ( 10 ),
password VARCHAR ( 10 ),
user_nick VARCHAR ( 10 ),
card_num BIGINT,
PRIMARY KEY ( user_id )
);
-- 插入数据
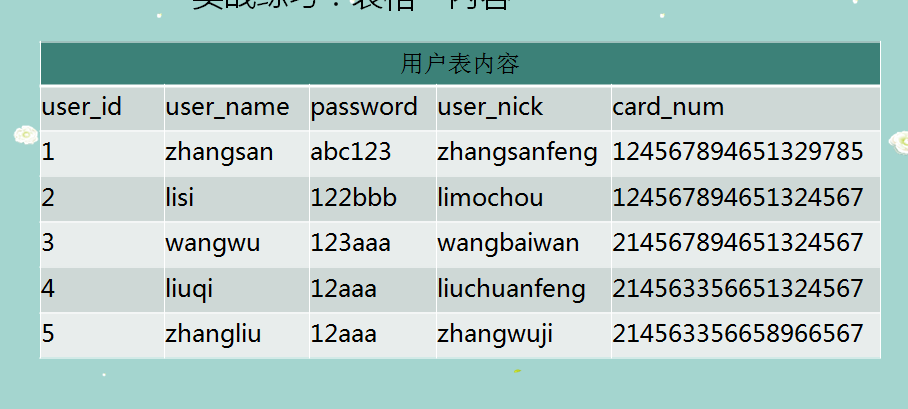
INSERT INTO user_info ( user_id, user_name, PASSWORD, user_nick, card_num )
VALUES
( 1, 'zhangsan', 'abc123', 'zhangsanfeng', 124567894651329785 ),
( 2, 'lisi', '122bbb', 'limochou', 124567894651324567 ),
( 3, 'wangwu', '123aaa', 'wangbaiwan', 214567894651324567 ),
( 4, 'liuqi', '12aaa', 'liuchuanfeng', 214563356651324567 ),
( 5, 'zhangliu', '12aaa', 'zhangwuji', 214563356658966567 );
-- user_nick长度不够,修改user_nick的长度再重新插入数据
ALTER TABLE user_info MODIFY user_nick VARCHAR ( 20 );
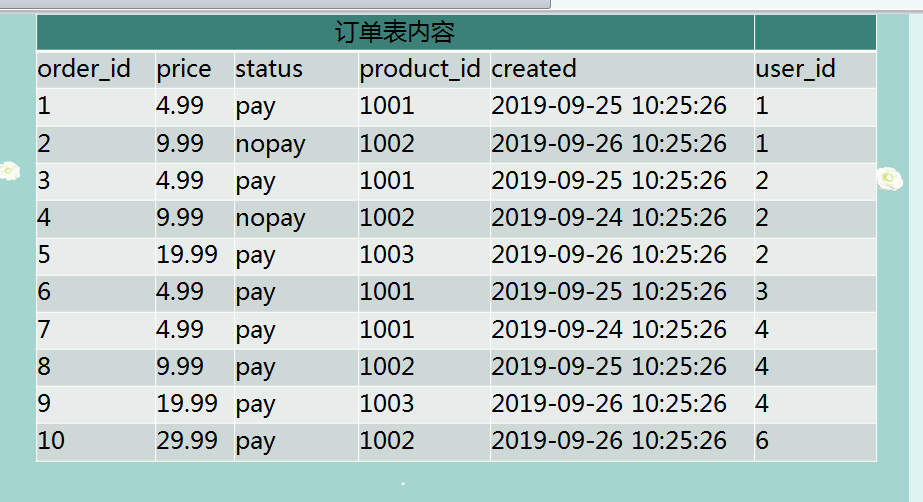
-- 创建订单表
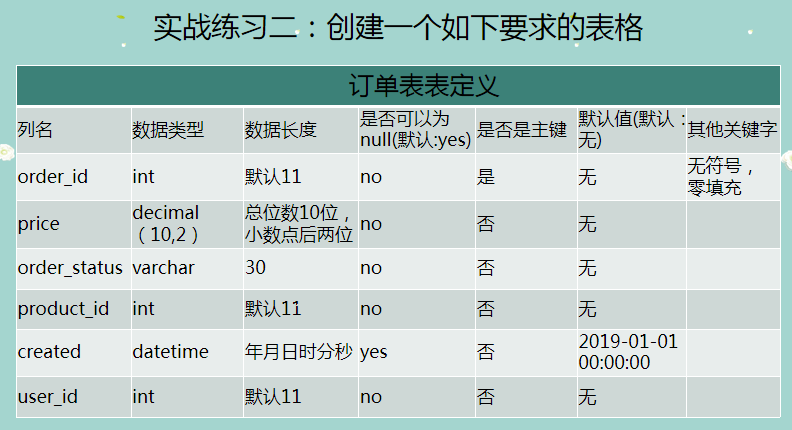
CREATE TABLE order_info (
order_id INT UNSIGNED ZEROFILL NOT NULL,
price DECIMAL ( 10, 2 ) NOT NULL,
order_status VARCHAR ( 30 ) NOT NULL,
product_id INT NOT NULL,
created datetime DEFAULT "2019-01-01 00:00:00",
user_id INT NOT NULL,
PRIMARY KEY ( order_id )
);
-- 插入数据
INSERT INTO order_info
VALUES
( 1, 4.99, 'pay', 1001, '2019-09-25 10:25:26', 1 ),
( 2, 9.99, 'nopay', 1002, '2019-09-26 10:25:26', 1 ),
( 3, 4.99, 'pay', 1001, '2019-09-25 10:25:26', 2 ),
( 4, 9.99, 'nopay', 1002, '2019-09-24 10:25:26', 2 ),
( 5, 19.99, 'pay', 1003, '2019-09-26 10:25:26', 2 ),
( 6, 4.99, 'pay', 1001, '2019-09-25 10:25:26', 3 ),
( 7, 4.99, 'pay', 1001, '2019-09-25 10:25:26', 4 ),
( 8, 9.99, 'pay', 1002, '2019-09-25 10:25:26', 4 ),
( 9, 19.99, 'pay', 1003, '2019-09-26 10:25:26', 4 ),
( 10, 29.99, 'pay', 1002, '2019-09-26 10:25:26', 6 );
-- where子句小练习
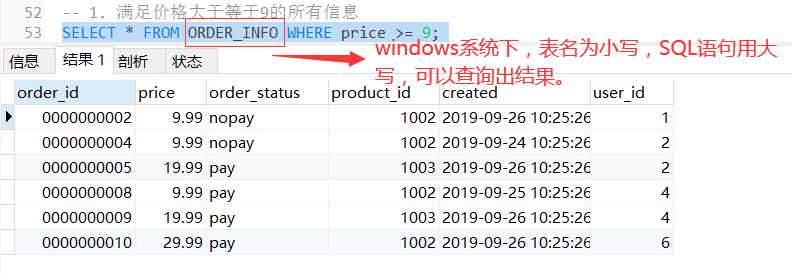
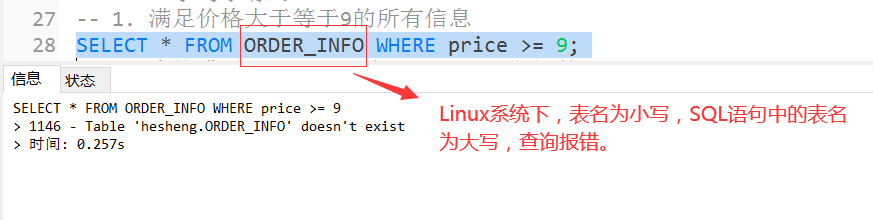
-- 1. 满足价格大于等于9的所有信息
SELECT * FROM order_info WHERE price >= 9;
-- 2. 查找满足product_id在1002和1003之间的
SELECT * FROM order_info WHERE product_id BETWEEN 1002 AND 1003;
-- 3. 查找user_id在1、3、5这三个数内的信息
SELECT * FROM order_info WHERE user_id IN (1,3,5);
-- 4. 查找订单状态是已支付的信息
SELECT * FROM order_info WHERE order_status = 'pay';
-- 5. 查找用户名类似于已li开头的信息
SELECT * FROM user_info WHERE user_name LIKE 'li%';
-- 6. 查找用户名中第二个字母是h的信息
SELECT * FROM user_info WHERE user_name LIKE '_h%';
-- 7. 查找用户名中第二个字母不是h的信息
SELECT * FROM user_info WHERE user_name NOT LIKE '_h%';
-- 8. 查找用户名中最后一个字母以i结尾的信息
SELECT * FROM user_info WHERE user_name LIKE '%i';
-- 9. 查找价格大于8,并且订单状态是已支付的所有信息
SELECT * FROM order_info WHERE price > 8 AND order_status = 'pay';
-- 10.查找用户表中user_nick为null的信息
SELECT * FROM user_info WHERE user_nick IS NULL;
-- 11.查找用户表中user_nick为 not null的信息
SELECT * FROM user_info WHERE user_nick IS NOT NULL;
-- 聚合函数练习
-- 1. 查找订单表中最大的价格,查找订单表中最小的价格
SELECT MAX(price),MIN(price) FROM order_info;
-- 2. 查找订单表中user_id=2的最小价格
SELECT MIN(price) FROM order_info WHERE user_id = 2;
-- 3. 分别列出订单表中user_id=2的最小价格和最大价格
SELECT MIN(price),MAX(price) FROM order_info WHERE user_id = 2;
-- 4. 分别列出订单表中user_id=2的最小价格和最大价格,并把最小价格的展示结果的列名改为"min_price"
SELECT MIN(price) AS min_price,MAX(price) FROM order_info WHERE user_id = 2;
-- 5. 求订单表的价格的平均值,求订单表中user_id=2的价格的平均值
SELECT AVG(price) FROM order_info;
SELECT AVG(price) FROM order_info WHERE user_id = 2;
-- 6. 分别列出订单表中user_id=2的价格的平均值、最小值、最大值
SELECT AVG(price),MIN(price),MAX(price) FROM order_info WHERE user_id = 2;
-- 7. 求订单表中user_id=1的价格的总和
SELECT SUM(price) FROM order_info WHERE user_id = 1;
-- 8. 求订单表中user_id=1或者user_id=3的价格总和
SELECT SUM(price) FROM order_info WHERE user_id = 1 OR user_id = 3;
-- 分组练习
-- 1.首先筛选状态为已支付的订单,然后按照user_id分组,分组后每一组对支付金额进行求和,最终展示user_id和对应组求和金额
SELECT user_id,SUM(price) FROM order_info WHERE order_status = 'pay' GROUP BY user_id;
-- 2.首先筛选状态为支付的订单,然后按照user_id分组,分组后每一组对支付金额进行求和,再过滤求和金额大于10的,最终展示user_id和对应组的求和金额
SELECT user_id,SUM(price) FROM order_info WHERE order_status = 'pay' GROUP BY user_id HAVING SUM(price) > 10;
-- 数据表连接查询和子查询练习
-- 1.查询订单表中的价格大于10元的用户的昵称(小提示:用户昵称在用户表中,订单价格在订单表中)
SELECT a.user_nick FROM user_info a INNER JOIN order_info b ON a.user_id = b.user_id WHERE b.price > 10;
SELECT user_nick FROM user_info WHERE user_id IN (SELECT user_id FROM order_info WHERE price > 10);
-- 2.查询用户名以l开头的用户买过的所有订单id和对应价格(小提示:订单id和对应价格在订单表中,用户名在用户表中)
SELECT o.order_id,o.price FROM order_info o WHERE o.user_id IN (SELECT user_id FROM user_info u WHERE u.user_name LIKE 'l%');
二、创建如下要求的表格,并完成相应的题目。
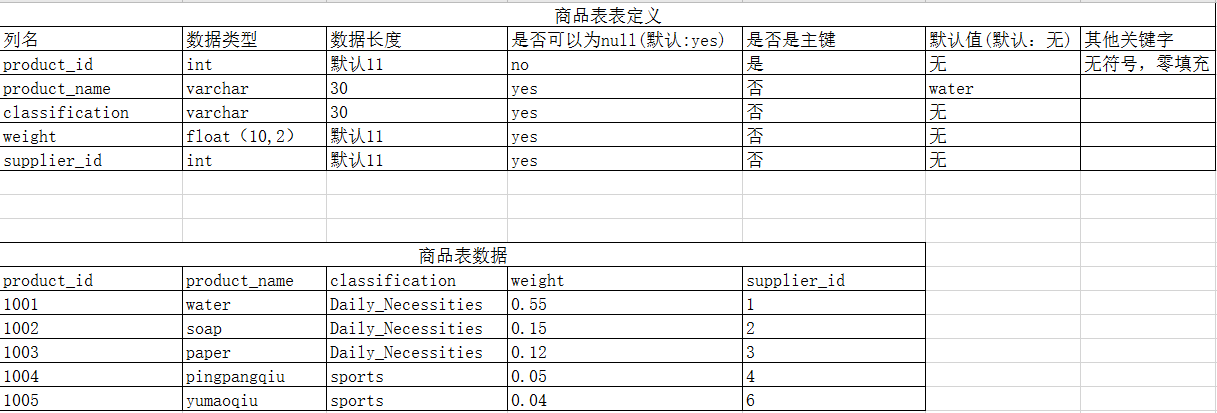
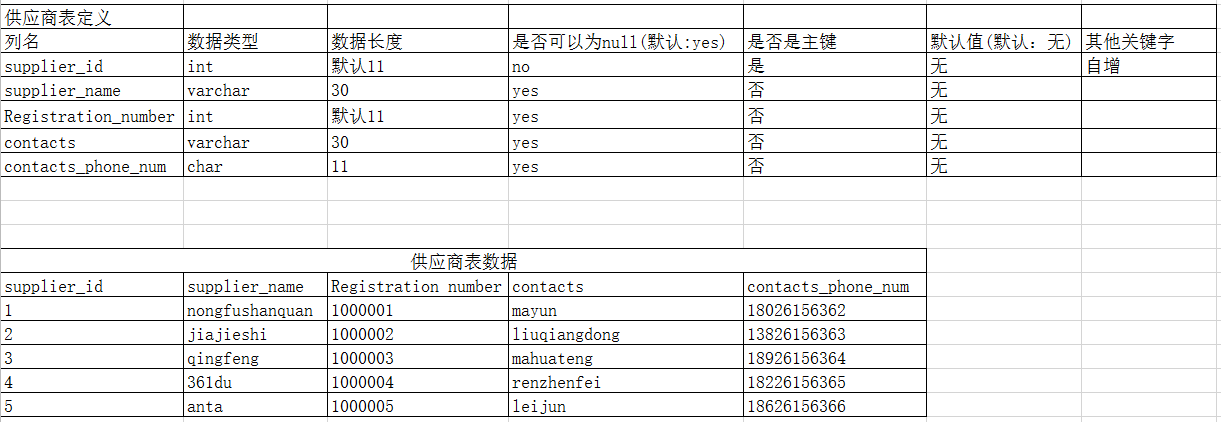
-- 1.按照表定义创建商品表+供应商表
-- 2.按照表数据插入所有数据
-- 创建商品表
CREATE TABLE products_info (
product_id INT UNSIGNED ZEROFILL NOT NULL,
product_name VARCHAR ( 30 ) DEFAULT 'water',
classification VARCHAR ( 30 ),
weight FLOAT ( 10, 2 ),
supplier_id INT,
PRIMARY KEY ( product_id )
);
-- 向商品表插入数据
INSERT INTO products_info
VALUES
( 1001, 'water', 'Daily_Necessities', 0.55, 1 ),
( 1002, 'soap', 'Daily_Necessities', 0.15, 2 ),
( 1003, 'paper', 'Daily_Necessities', 0.12, 3 ),
( 1004, 'pingpangqiu', 'sports', 0.05, 4 ),
( 1005, 'yumaoqiu', 'sports', 0.04, 6 );
-- 创建供应商表
CREATE TABLE suppliers_info (
supplier_id INT NOT NULL AUTO_INCREMENT,
supplier_name VARCHAR ( 30 ),
Registration_number INT,
contacts VARCHAR ( 30 ),
contacts_phone_num CHAR ( 11 ),
PRIMARY KEY ( supplier_id )
);
-- 向供应商表插入数据
INSERT INTO suppliers_info
VALUES
( 1, 'nongfushanquan', 1000001, 'mayun', '18026156362' ),
( 2, 'jiajieshi', 1000002, 'liuqiangdong', '13826156363' ),
( 3, 'qingfeng', 1000003, 'mahuateng', '18926156364' ),
( 4, '361du', 1000004, 'renzhenfei', '18226156365' ),
( 5, 'anta', 1000005, 'leijun', '18626156366' );
-- 3.修改供应商id为4的供应商名称为‘hongshuangxi’
UPDATE suppliers_info SET supplier_name = 'hongshuangxi' WHERE supplier_id = 4;
-- 4.查询商品重量大于0.10的商品的名称
SELECT product_name FROM products_info WHERE weight > 0.10;
-- 5.查询商品名称以字母p开头的商品的所有信息
SELECT * FROM products_info WHERE product_name like 'p%';
-- 6.查询商品重量大于0.10,小于0.20的商品名称
SELECT product_name FROM products_info WHERE weight > 0.10 AND weight < 0.20;
-- 7.按照商品分类统计各自的商品总个数,显示每个分类和其对应的商品总个数
SELECT classification,COUNT(classification) FROM products_info GROUP BY classification;
-- 8.将所有商品的名称按照商品重量由高到低显示
SELECT product_name,weight FROM products_info ORDER BY weight DESC;
-- 9.显示所有商品的信息,在右边显示有供应商的商品对应的供应商信息
SELECT * FROM products_info a LEFT JOIN suppliers_info b ON a.supplier_id = b.supplier_id;
-- 10.显示重量大于等于0.15的商品的供应商的联系人和手机号
SELECT s.contacts,s.contacts_phone_num FROM suppliers_info s INNER JOIN products_info p ON s.supplier_id = p.supplier_id and p.weight >= 0.15;