SELECT
a.fans_id,
a.order_time,
a.sync_time,
count( * ) AS times
FROM
统计表 AS a,
统计表 AS b
WHERE
a.fans_id = b.fans_id
AND a.order_time >= b.order_time
AND a.effective = '有效'
AND b.effective = '有效'
AND a.series LIKE concat('%','系列','%')
AND b.series LIKE concat('%','系列','%')
GROUP BY
a.fans_id,
a.id
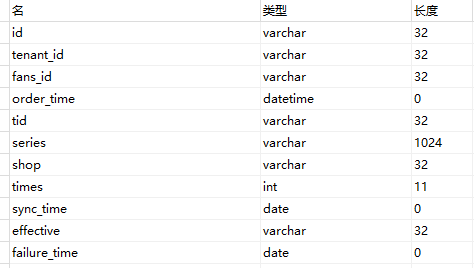
-- 按照购买人id,按照购买时间进行排序,并标记序号,加上创建表语句如下(建表时需加索引,方便后续查找):
CREATE TABLE 临时表名 (
id INT PRIMARY KEY AUTO_INCREMENT,
fans_id VARCHAR ( 32 ),
order_time datetime,
sync_time date,
times INT ( 6 ),
PRIMARY KEY ( id ),
INDEX mid_fans_id ( fans_id ) USING BTREE,
INDEX mid_order_time ( order_time ) USING BTREE,
INDEX mid_times ( times ) USING BTREE,
INDEX mid_sync_time ( sync_time ) USING BTREE
)
AS
(
SELECT
a.fans_id,
a.order_time,
a.sync_time,
count( * ) AS times
FROM
统计表 AS a,
统计表 AS b
WHERE
a.fans_id = b.fans_id
AND a.order_time >= b.order_time
AND a.effective = '有效'
AND b.effective = '有效'
AND a.series LIKE concat('%','系列','%')
AND b.series LIKE concat('%','系列','%')
GROUP BY
a.fans_id,
a.id
);
-- 由于数据库版本为5.4,所以建完临时表不支持一条sql多次查询,没办法,只能直接创建表
结果如图:
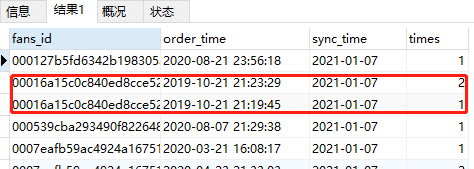
满足了排序,但是后来我发现有一些人是同时间下单的,以至于某些人的times是重复的,于是更新为下面的SQL
SELECT
a.fans_id,
a.order_time,
a.sync_time,
( @i := CASE WHEN @pre_keyword = fans_id THEN @i + 1 ELSE 1 END ) AS times,
@pre_keyword:=fans_id
FROM
( SELECT fans_id, order_time, sync_time FROM 统计表 WHERE effective = '有效' AND series LIKE concat('%','系列','%') ORDER BY fans_id,order_time ) a,
( SELECT @i := 0, @pre_keyword := '' ) AS b
这次的sql是按照时间排序后,判断当前购买人第几次出现,打上序号,由此满足需求
查询结果和上图相同,就不附图了哈
效率这,购买人id,下单时间需要创建索引,否则可能有些慢,测试库中数据大概七百万左右,总体查询可在四秒内完成
希望这篇文章能在开发中给予您一定的帮助,新人博客主,码龄一年,如有更好的方案,望指教!