一.基本思想
在机器学习的问题中,我们目标是构建模型来作出准确的预测。但实际上,单个的模型往往难以有比较好的预测效果。所以我们通过学习多个弱学习器,并最终进行组合的方法,来构造强学习器,从而达到更好的预测效果。
集成学习常见的种类:
- bagging
- boosting
- stacking
- blending
下图是集成学习的常见的结构图。
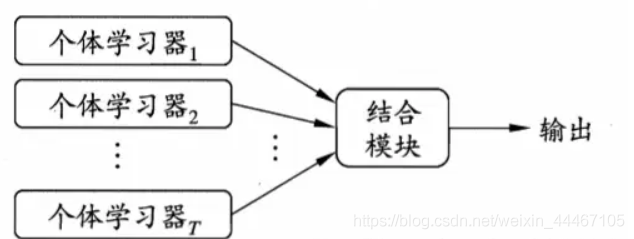
二.Bagging
Bagging是一种并行的算法,它的弱学习器之间没有依赖关系。的一个关键点在于它的Bootstrap Sample(自助采样),实际上是一种有放回的随机抽样(这里的有放回的意思是抽一个放回一个)。
Bagging算法的流程如下:
- 给定训练集样本S,给定K个弱学习器。从S中利用Bootstrap方法抽取M的样本,作为一个训练样本集,重复K次,得到K个独立的训练样本集。
- 用采用得到的K个训练样本集来分别作为K个弱学习器的训练集来训练这K个弱学习器。
- 用K个弱学习器预测测试集,并融合结果(分类可以采用投票机制,回归可以采用平均的方法)
当学习算法不稳定时,可以用Bagging方法,因为Bagging方法可以有效的减少方差。
优点:减少了方差
缺点:由于又放回的随机抽样得到的训练集改变了原来的样本分布,一定程度上会引入偏差
另外,与Random Forest不同的是,RF(一般用Cart树)训练时虽然采样方法也是Boostrap,但是RF没有用到所有特征,而是抽样出一部分特征来进行训练。
三.Boosting
Boosting是一种串行的算法,它的弱学习器之间存在着强依赖关系。
它与bagging的不同:
1)样本选择:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
5)计算效果
Bagging主要减小了variance,而Boosting主要减小了bias,而这种差异直接推动结合Bagging和Boosting的MultiBoosting的诞生
为什么bagging减少方差而boosting减少偏差?
boosting的基模型一般为弱模型(否则会导致方差过大),而bagging一般为强模型(否则偏差会偏大)
1.bagging中每个弱分类器都是近似的,但是其相关性不高,所以一般不能降低偏差,但可以一定程度上减低方差.单个弱分类器的方差:
V
a
r
(
f
(
x
)
)
=
σ
2
Var(f(x))=\sigma^2
Var(f(x))=σ2
对于独立同分布的变量X1,X2…Xn来说有:
-
V
a
r
(
c
X
)
=
E
[
(
c
X
?
E
(
c
X
)
)
2
]
=
E
[
(
c
X
?
c
E
(
X
)
)
2
]
=
c
2
E
[
(
X
?
E
(
X
)
)
2
]
=
c
2
V
a
r
(
X
)
Var(cX)=E[(cX-E(cX))^2]=E[(cX-cE(X))^2]=c^2E[(X-E(X))^2]=c^2Var(X)
Var(cX)=E[(cX?E(cX))2]=E[(cX?cE(X))2]=c2E[(X?E(X))2]=c2Var(X)
-
V
a
r
(
X
1
,
X
2..
X
n
)
=
V
a
r
(
X
1
)
+
V
a
r
(
X
2
)
+
.
.
.
+
V
a
r
(
X
n
)
Var(X1,X2..Xn)=Var(X1)+Var(X2)+...+Var(Xn)
Var(X1,X2..Xn)=Var(X1)+Var(X2)+...+Var(Xn)
基于上面的条件,对独立和近似的n个弱分类器进行组合时:
V
a
r
(
∑
f
(
x
)
n
)
=
1
n
2
V
a
r
(
∑
f
(
x
)
)
=
1
n
V
a
r
(
f
(
x
)
)
=
1
n
σ
2
Var(\frac{\sum f(x)}{n})=\frac{1}{n^2}Var(\sum f(x))=\frac{1}{n}Var(f(x))=\frac{1}{n}\sigma^2
Var(n∑f(x)?)=n21?Var(∑f(x))=n1?Var(f(x))=n1?σ2
所以,bagging能减少方差。
bagging之所以不能减少偏差是因为:
E
(
∑
f
(
x
)
n
)
=
E
(
f
(
x
)
)
E(\frac{\sum f(x)}{n})=E(f(x))
E(n∑f(x)?)=E(f(x))
2.Boosting采用的是贪心算法(每次寻找局部最优),最优的目标就是减少损失函数(即减少偏差),所以能够有效减少偏差。但是由于基模型之间存在强相关性,所以不能降低方差。
四.Stacking
我们以两层的Stacking为例(实际可以多层),第一层为两个模型M1,M2,第二层为一个模型M3。对于整体的数据集划分为Traing set (800个样本)和Testing set(200个样本)。
- 首先对第一层的两个模型M1,M2进行训练,训练的方法是对训练集进行K折交叉,这里以5折交叉为例。对M1进行5折交叉验证(160个样本作为验证集,640个样本作为训练集),每个交叉用640个样本进行训练,对160个样本进行预测,得到这160个样本的预测值
T
r
a
11
Tra_{11}
Tra