
1.КөПЦФӯАн
- КЧПИЈ¬ОТГЗРиТӘАҙөҪОч№ПКУЖөөД№ЩНшЈ¬БҙҪУОӘЈәОч№ПКУЖөЈ¬Лжұгөг»чЖдЦРТ»ёцКУЖөҪшИлЈ¬өг»чөзДФјьЕМөДF12АҙөҪҝӘ·ўХЯДЈКҪЈ¬°ҙctrl+FҪшРРЛСЛчЈ¬КдИлvideoЈ¬ИзПВЈә
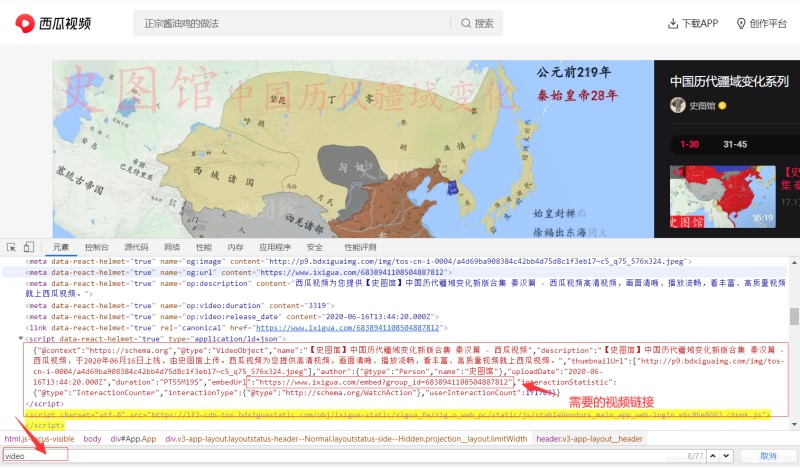
- ОТГЗҝЙТФ·ўПЦЈ¬ХвАпУРТ»ёцКУЖөБҙҪУЈ¬ОТГЗөг»чХвёцБҙҪУҪшИлЈ¬ТАҫЙ°ҙөзДФF12јьАҙөҪҝӘ·ўХЯДЈКҪЈ¬јМРшЛСЛчvideoЈ¬ҝЙТФ·ўПЦЈ¬ХвАпЦұҪУУРКУЖөөДПВФШБҙҪУЈ¬ИзПВЈә
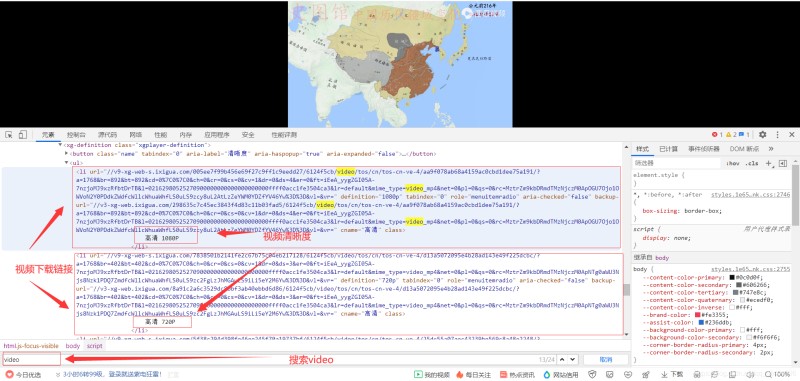
- ОТГЗКЗІ»КЗЦ»ТӘФЛУГҙъВлҫНҝЙТФХТөҪКУЖөөДПВФШБҙҪУДШЈҝІ»№эЈ¬УЙУЪЙПКцНјЖ¬ХвР©КУЖөПВФШБҙҪУКЗ¶ҜМ¬јУФШөДЈ¬ХвАпРиТӘУГөҪseleniumДЈҝй№юЈЎІ»¶®ХвёцДЈҝйөД ¶БХЯҝЙТФҝҙҝҙРЎұаЦ®З°РҙөДІ©ҝН№юЈЎХвАпРЎұаёшіцТ»ЖӘІ©ҝНЈ¬І©ҝНБҙҪУОӘЈәseleniumДЈҝйМ«ЗҝҙуБЛЈ¬НшТЧФЖТфАЦ¶јҝЙПВФШ

2.іМРтҙъВл
іМРтҙъВлИзПВЈә
import re
from selenium import webdriver
# url="https://www.ixigua.com/6982149651281478152?logTag=cc6bf98fd0f8fe35fe0e"
url=input("КдИлКУЖөБҙҪУЈә")
group_id=re.findall('https://www.ixigua.com/(.*)\?logTag=.*',url)
url='https://www.ixigua.com/embed?group_id='+group_id[0]
# ҪшИлдҜААЖчЙиЦГ
options = webdriver.ChromeOptions()
# ЙиЦГЦРОД
options.add_argument('lang=zh_CN.UTF-8')
# ёь»»Н·Іҝ
options.add_argument('user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"')
driver=webdriver.Chrome(options=options)
driver.get(url=url)
driver.implicitly_wait(5)
infos=driver.find_elements_by_xpath("//xg-definition/ul/li")
for info in infos[:-1]:
print(info.get_attribute("definition"))
print('http:'+info.get_attribute("url"))
- ұрҝҙЧЬ№ІҙъВлҫНХвГҙөгЈ¬Из№ыІ»ЦӘөАЖдЦРөДФӯАнЈ¬»тРнХвГҙөгҙъВл¶јЗГІ»іцАҙДШЈҝ
- УЙУЪКУЖөПВФШЦұҪУУГҙъВлКөПЦҝЙДЬРиТӘҪПіӨөДКұјдЈ¬К№УГХвАпЦұҪУ°СКУЖөөДПВФШБҙҪУёшіцАҙ№юЈЎЦ®әу¶БХЯҫНҝЙТФДГКУЖөПВФШБҙҪУИҘдҜААЖчЙППВФШјҙҝЙЎЈ

3.ФЛРРҪб№ы


PythonЕАіжПВФШОч№ПКУЖө
jsjbwy