目录
- 1.审查分类算法
- 1.1线性算法审查
- 1.2非线性算法审查
- 1.2.1K近邻算法
- 1.2.2贝叶斯分类器
- 1.2.3分类与回归树
- 1.2.4支持向量机
- 2.审查回归算法
- 2.1线性算法审查
- 2.1.1线性回归算法
- 2.1.2岭回归算法
- 2.1.3套索回归算法
- 2.1.4弹性网络回归算法
- 2.2非线性算法审查
- 2.2.1K近邻算法
- 2.2.2分类与回归树
- 2.2.3支持向量机
- 3.算法比较
- 总结
程序测试是展现BUG存在的有效方式,但令人绝望的是它不足以展现其缺位。
――艾兹格・迪杰斯特拉(Edsger W. Dijkstra)
算法审查时选择合适的机器学习算法主要方式之一。审查算法前并不知道哪个算法对问题最有效,必须设计一定的实验进行验证,以找到对问题最有效的算法。
审查算法前没有办法判断那个算法对数据集最有效、能够生成最优模型,必须通过一些列的实验进行验证才能够得出结论,从而选择最优的算法。这个过程被称为审查算法。
审查算法时,要尝试多种代表性算法、机器学习算法以及多种模型,通过大量实验才能找到最有效的算法。
1.审查分类算法
1.1线性算法审查
1.1.1逻辑回归
逻辑回归其实是一个分类算法而不是回归算法,通常是利用已知的自变量来预测一个离散型因变量的值(如二进制0/1、真/假)。简单来说,它就是通过拟合一个逻辑回归函数(Logistic Function)来预测事件发生的概率。所以它预测的是一个概率值,它的输出值应该为0~1,因此非常适合二分类问题。
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression#逻辑回归
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
array = data.values
X = array[:, 0:8]
Y = array[:, 8]
#逻辑回归
num_folds = 10
seed = 7
kfold = KFold(n_splits=num_folds, random_state=seed, shuffle=True)
model = LogisticRegression(max_iter=3000)
result = cross_val_score(model, X, Y, cv=kfold)
print(result.mean())
执行结果如下:0.7721633629528366
1.1.2线性判别分析
线性判别分析(Linear DIscriminant Analysis,LDA),也叫做Fisher线性判别(Fisher Linear Discriminant Analysis,FLD)。它的思想是将高维的模式样本投影到最佳鉴别矢量空间,以达到抽取分类信息和压缩特征空间维数的效果,投影后保证模式样本在新的子空间有最大类间距离和最小类内距离。因此,他是一种有效的特征抽取方法。(完全不懂它是什么东西。。。)
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
#相同代码不再赘述
#线性判别分析
model = LinearDiscriminantAnalysis()
result = cross_val_score(model, X, Y, cv=kfold)
print(result.mean())
执行结果如下:
0.7669685577580315
1.2非线性算法审查
1.2.1K近邻算法
K近邻算法的基本思路是:如果一个样本在特征空间中的k个最相似的样本中大多数属于某一个类别,则该样本也属于这个了类别。在scikit-learn中通过KNeighborsClassifier实现。
from sklearn.neighbors import KNeighborsClassifier
#相同代码不再赘述
#K近邻
model = KNeighborsClassifier()
result = cross_val_score(model, X, Y,cv=kfold)
print(result.mean())
0.7109876965140123
1.2.2贝叶斯分类器
贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其在所有类别上的后验概率,即该对象属于某一类的来率,选择具有最大后验概率的类作为该对象所属的类。
from sklearn.naive_bayes import GaussianNB
#贝叶斯分类器
model = GaussianNB()
result = cross_val_score(model, X, Y,cv=kfold)
print(result.mean())
0.7591421736158578
1.2.3分类与回归树
分类与回归树(CART).CART算法由以下两布组成:
- 树的生成:基于训练集生成决策树,生成的决策树要尽量大。
- 树的剪枝:用验证集对已生成的树进行剪枝,并选择最优子树,这时以损失函数最小作为剪枝标准。
from sklearn.tree import DecisionTreeClassifier
#分类与回归树
model = DecisionTreeClassifier()
result = cross_val_score(model, X, Y,cv=kfold)
print(result.mean())
0.688961038961039
1.2.4支持向量机
from sklearn.svm import SVC
#支持向量机
model = SVC()
result = cross_val_score(model, X, Y,cv=kfold)
print(result.mean())
0.760457963089542
2.审查回归算法
本部分使用波士顿房价的数据集来审查回归算法,采用10折交叉验证来分离数据,并应用到所有的算法上。
2.1线性算法审查
2.1.1线性回归算法
线性回归算法时利用数理统计中的回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。在回归分析中,若只包含一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析成为一元线性回归分析。如果回归分析中包含两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
filename = 'housing.csv'
names = ['CRIM','ZN','INDUS','CHAS','NOX','RM','AGE','DIS','RAD','TAX','PRTATIO','B','LSTAT','MEDV']
data = read_csv(filename,names=names,delim_whitespace=True)
array = data.values
X = array[:,0:13]
Y = array[:,13]
n_splits = 10
seed = 7
kfold = KFold(n_splits=n_splits,random_state=seed,shuffle=True)
#线性回归算法
model = LinearRegression()
scoring = 'neg_mean_squared_error'
result = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
print("线性回归算法:%.3f" % result.mean())
线性回归算法:-23.747
2.1.2岭回归算法
岭回归算法是一种专门用于共线性数据分析的有偏估计回归方法,实际上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价,获得回归系数更符合实际、更可靠的回归方法,对病态数据的拟合要强于最小二乘法。
from sklearn.linear_model import Ridge
#岭回归算法
model = Ridge()
scoring = 'neg_mean_squared_error'
result = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
print("岭回归算法:%.3f" % result.mean())
岭回归算法:-23.890
2.1.3套索回归算法
套索回归算法与岭回归算法类似,套索回归算法也会惩罚回归系数,在套索回归中会惩罚回归系数的绝对值大小。此外,它能够减少变化程度并提高线性回归模型的精度。
from sklearn.linear_model import Lasso
#套索回归算法
model = Lasso()
scoring = 'neg_mean_squared_error'
result = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
print("套索回归算法:%.3f" % result.mean())
套索回归算法:-28.746
2.1.4弹性网络回归算法
弹性网络回归算法是套索回归算法和岭回归算法的混合体,在模型训练时弹性网络回归算法综合使用L1和L2两种正则化方法。当有多个相关的特征时,弹性网络回归算法是很有用的,套索回归算法会随机挑选一个,而弹性网络回归算法则会选择两个。它的优点是允许弹性网络回归继承循环状态下岭回归的一些稳定性。
from sklearn.linear_model import ElasticNet
#弹性网络回归算法
model = ElasticNet()
scoring = 'neg_mean_squared_error'
result = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
print("弹性网络回归算法:%.3f" % result.mean())
弹性网络回归算法:-27.908
2.2非线性算法审查
2.2.1K近邻算法
在scikit-learn中对回归算法的K近邻算法的实现类是KNeighborsRegressor。默认距离参数为闵氏距离。
from sklearn.neighbors import KNeighborsRegressor
#K近邻算法
model = KNeighborsRegressor()
scoring = 'neg_mean_squared_error'
result = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
print("K近邻算法:%.3f" % result.mean())
K近邻算法:-38.852
2.2.2分类与回归树
在scikit-learn中分类与回归树的实现类是DecisionTreeRegressor。
from sklearn.tree import DecisionTreeRegressor
#分类与回归树算法
model = DecisionTreeRegressor()
scoring = 'neg_mean_squared_error'
result = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
print("分类与回归树算法:%.3f" % result.mean())
K近邻算法:-38.852
分类与回归树算法:-21.527
2.2.3支持向量机
from sklearn.svm import SVR
#支持向量机
model = SVR()
scoring = 'neg_mean_squared_error'
result = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
print("支持向量机:%.3f" % result.mean())
支持向量机:-67.641
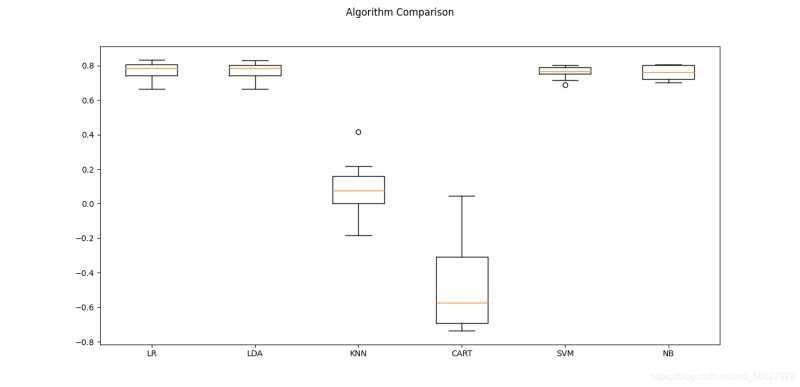
3.算法比较
比较不同算法的准确度,选择合适的算法,在处理机器学习的问题时是分厂重要的。接下来将介绍一种模式,在scikit-learn中可以利用它比较不同的算法,并选择合适的算法。
当得到一个新的数据集时,应该通过不同的维度来审查数据,以便找到数据的特征。一种比较好的方法是通过可视化的方式来展示平均准确度、方差等属性,以便于更方便地选择算法。
最合适的算法比较方法是:使用相同数据、相同方法来评估不同算法,以便得到一个准确的结果。
使用Pima Indias数据集来介绍如何比较算法。采用10折交叉验证来分离数据,并采用相同的随机数分配方式来确保所有算法都使用相同的数据。为了便于理解,为每个算法设定一个短名字。
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from matplotlib import pyplot
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename,names=names)
array = data.values
X = array[:,0:8]
Y = array[:,8]
num_folds = 10
seed = 7
kfold = KFold(n_splits=num_folds,random_state=seed,shuffle=True)
models={}
models['LR'] = LogisticRegression(max_iter=3000)
models['LDA'] = LinearDiscriminantAnalysis()
models['KNN'] = KNeighborsRegressor()
models['CART'] = DecisionTreeRegressor()
models['SVM'] = SVC()
models['NB'] = GaussianNB()
results = []
for name in models:
result = cross_val_score(models[name], X, Y, cv=kfold)
results.append(result)
msg = '%s: %.3f (%.3f)' % (name, result.mean(), result.std())
print(msg)
#图表显示
fig = pyplot.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(models.keys())
pyplot.show()
执行结果如下:
LR: 0.772 (0.050)
LDA: 0.767 (0.048)
KNN: 0.081 (0.159)
CART: -0.478 (0.257)
SVM: 0.760 (0.035)
NB: 0.759 (0.039)
总结
本文主要介绍了算法审查以及如何选择最合适的算法,在第三部分中提供了代码实例,可以直接将其作为模板使用到项目中以选择最优算法。
jsjbwy