def main():
# Training settings
# 声明一个parser
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
# 添加参数
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=14, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--dry-run', action='store_true', default=False,
help='quickly check a single pass')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
# 读取命令行参数
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
train_kwargs = {'batch_size': args.batch_size}
test_kwargs = {'batch_size': args.test_batch_size}
if use_cuda:
cuda_kwargs = {'num_workers': 1,
'pin_memory': True,
'shuffle': True}
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
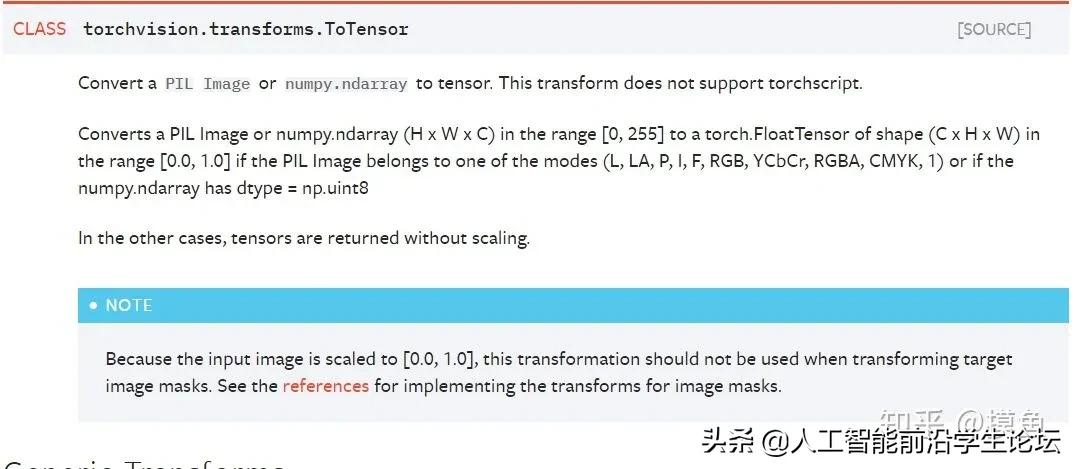
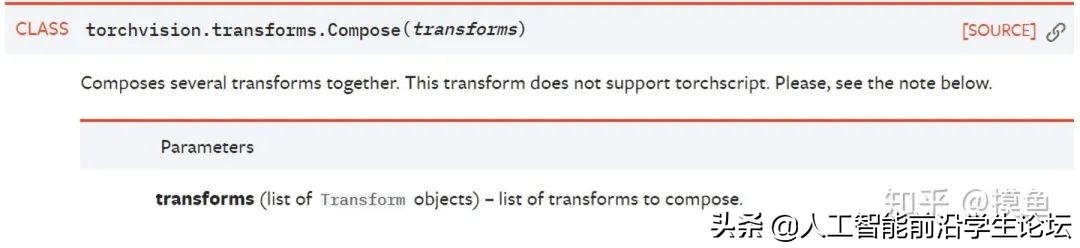
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset1 = datasets.MNIST('../data', train=True, download=True,
transform=transform)
dataset2 = datasets.MNIST('../data', train=False,
transform=transform)
train_loader = torch.utils.data.DataLoader(dataset1, **train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
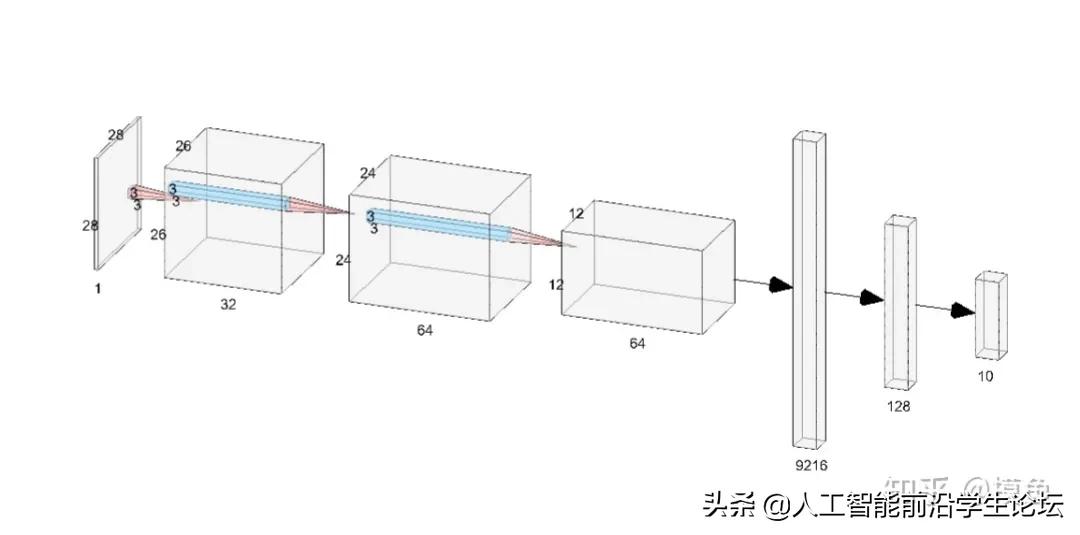
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
scheduler.step()
if args.save_model:
torch.save(model.state_dict(), "mnist_cnn.pt")
06
模型结果

07
摸鱼建议
摸鱼也是最近接触PyTorch这个框架,在学习过程中遇到了一些问题,也总结了一些经验。下面是摸鱼遇到的一些问题以及解决方式
Q1:为什么网络的结构是这样定义的?有什么理由吗?
A1:其实刚开始摸鱼也不清楚为什么网络要这样设计,后来在Andrew Ng的课上,老师提起过一嘴,说这个没有什么特别的原因,如果非要说一个原因的话那就是它在实验上的表现很好。所以我们在学习的过程中,可以借鉴那些经典的网络结构,以此为基础改进来形成我们自己的网络架构。同样网络中的参数也是一般采用设计者给出的会比较好。
Q2:transform,DataLoader等等的到底是干嘛的?在好多地方看到过但还是比较模糊
A2:确实,在看官方文档的时候,经常看到这两段代码。相信看完本文应该就可以解决这个问题了,至于要如何解决类似的问题,我的一个建议是了解数据的源格式以及你想要的的目的格式。其实transform不难理解,就是进行一个数据格式的转换,但是如果不了解数据的源格式,可能对这块就会比较模糊。
cs