今天对分布式相关的一些概念与理论进行学习。
1.集群与分布式
集群:相同的应用部署在多台服务器。
分布式:不同的应用部署在多台服务器。
1.数据一致性
在分布式环境中,为了提高系统整体性能,数据以多副本冗余机制存储,副本之间通过数据复制进行同步。
数据副本与数据复制必然引入新的问题:如何处理副本数据的一致性?
总的来说,无法找到一种能够满足所有分布式环境的一致性解决方案,很多时候要在系统性能与数据一致性之间权衡。
由此,分布式一致性常见以下三种一致性:
1.1.强一致性
强一致性:数据写以后,任意时刻,所有数据副本中的数据都是一致的。
强一致性,也可以称为:原子一致性、线性一致性。
强一致性,是非分布式环境中主要被采用的一致性原则。
在非分布式环境中,数据可以集中存储,例如整个系统就一个数据库,这种情况下容易保证数据的强一致性。
在分布式环境中,数据存在多个副本,分布在不同的服务器上,数据副本之间的同步会经过网络通讯,这种情况下,很难保证强一致性。
1.2.顺序一致性
顺序一致性:任何一次读都能读取到数据的最近一次写的数据,系统的所有进程的顺序一致,而且是合理的。
顺序一致性,其实本人接触也不多,而且实际中暂时未涉及,这里就不再赘述。
1.2.弱一致性
弱一致性:数据写以后,不保证所有的数据副本何时能够达到一致,但是会尽可能的保证到某个时刻达到一致。
1.3.最终一致性
最终一致性:数据写以后,经过一段时间,所有数据副本中的数据最终是一致的。
一段时间的长短是由业务场景决定的。
最终一致性是弱一致性的特例,是分布式环境中广泛被采用的一致性原则。
2.CAP定理
2.1.概念
CAP:一个分布式系统不可能同时满足一致性(Consistentcy)、可用性(Availability)和分区容错性(Partition tolerance),最多只能满足其中的两项。
下面对C、A、P进行描述:
- Consistency(一致性):所有数据副本的数据都是一致的。
- Availability(可用性):所有请求都能获取正确的响应。
- Partition Tolerance(分区容错性):即使发生了网络分区,服务也能对外提供满足一致性和可用性的服务。
网络分区:分布式系统由网络连通的多个节点构成,有时由于一些特殊原因(网络波动、异常)导致部分节点之间出现网络不连通的情况。这种情况下,就会形成多个孤立的子网络或孤立节点,这些子网络和孤立节点称之为网络分区。
其实在分布式系统中,首先需要保证的就是分区容错性,否则分布式的意义就不存在了。
所以,一般情况下,我们需要权衡的是一致性和可用性之间的平衡。
2.2.举例验证
下面以外卖下单为例,通过下图进行简单验证:
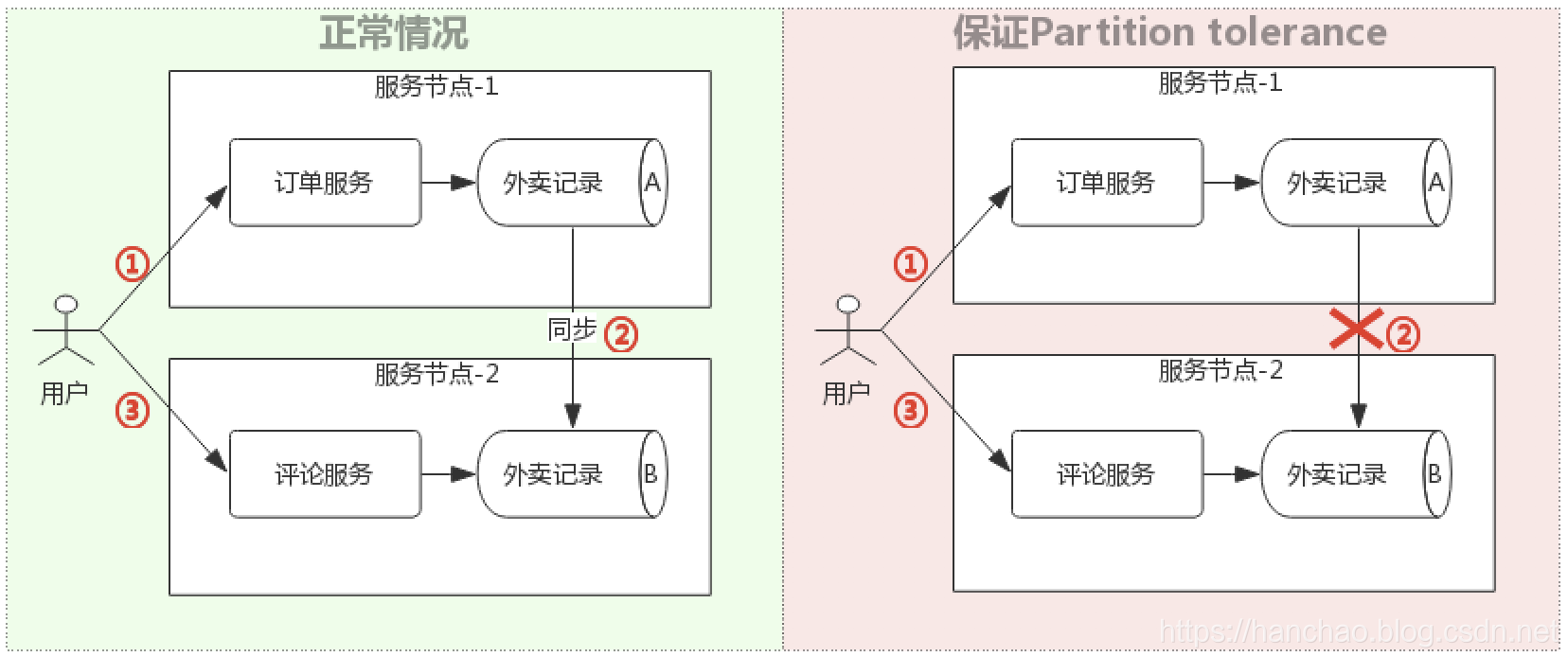
正常情况下
- 用户外卖下单,数据库A插入外卖记录。
- 数据库A的外卖记录通过网络同步给数据库B,数据库B中存有外卖记录。
- 用户查看评论情况,评论服务获取数据库B的数据,显示:外卖评论详情。
网络分区情况:第二步数据库A的外卖记录通过网络同步给数据库B时失败。
此时,是否能够同时保证Consistency和Availability呢?答案是否定的。
先保证一致性的情况
- 用户外卖下单,数据库A插入外卖记录。
- 数据库A的外卖记录通过网络同步给数据库B时失败。
- 因为
要保证一致性,所以需要用户一直等待,直至网络恢复正常,数据库A将最新数据同步给数据库B。 - 这种情况下,相当于
牺牲了可用性。
先保证可用性的情况
- 用户外卖下单,数据库A插入外卖记录。
- 数据库A的外卖记录通过网络同步给数据库B时失败。
- 因为
要保证可用性,所以直接查询数据库B的旧数据,返回给用户:无此外卖订单。 - 这种情况下,相当于
牺牲了一致性。
通过上述简单举例,验证了在分布式环境下,保证分区可用性的前提下,无法同时保证一致性和可用性。
同时,也可以看出上面两种处理方式都不太理想,那么更加理想的处理方式是什么呢?
3.BASE理论
3.1.概念
BASE:基本可用(Basic Availability)、软状态(Soft State)和最终一致性(Eventually Consistency)。
BASE理论是在CAP定理上,依据行业实践经验,逐渐演化出来的一种分布式方案。
下面对BA、S、E进行描述:
- 基本可用:分布式系统故障时,允许损失部分可用性,提供基本可用的服务。
- 允许在响应时间上的可用性损失:正常情况下,外卖下单需要0.5s;异常情况下,外卖下单需要3s。
- 允许在功能上的可用性损失:正常情况下,订单、评价服务都正常;异常情况下,只保证订单服务正常。
- 软状态:分布式系统中,允许存在的一种中间状态,也叫弱状态或柔性状态。
- 举例:在下单支付时,让页面显示
支付中,直到支付数据同步完成。
- 最终一致性:在出现软状态的情况下,经过一段时间后,各项数据最终到底一致。
- 举例:在
支付中这个软状态时,数据并未一致,软状态结束后,最终支付数据达到一致。
3.2举例说明
还是以章节2.2的外卖下单示例图为例,对BASE理论进行说明:
采取软状态和最终一致性的示例
- 用户外卖下单,数据库A插入外卖记录。
- 数据库A的外卖记录通过网络同步给数据库B时失败。
- 此时采取
最终一致性方案,并设置软状态下单中。 - 前端页面展示给用户
下单中,然后直到网络恢复正常,数据库A将最新数据同步给数据库B,数据最终达到一致。 - 用户查看评论情况,评论服务获取数据库B的数据,显示:外卖评论详情。
采取基本可用的实例
- 用户外卖下单,数据库A插入外卖记录。
- 数据库A的外卖记录通过网络同步给数据库B时失败。
- 此时采取
基本可用方案,有两种方案。 - 方案一:损失响应时间。用户查看评论情况时,由原来的0.5秒增长到10s,其实后端在进行数据同步。
- 方案二:损失功能。评论服务不是关键服务,可以直接降级,展示给用户一个降级页面。
4.分布式事务
在传统数据库中,事务是一项非常重要的特性,其理论基于ACID。
在分布式环境下,由于数据副本的存在,原有事务机制难以生效,此时大多会采取基于BASE理论的分布式事务。
下面简单介绍几类分布式事务算法,更加深入的知识请自行了解。
4.1.二阶段提交算法
二阶段提交,2-Phase Commit,简称2PC。
2PC算法有2个参与者:
- 事务参与者,即分布式事务中的多个数据节点。
- 事务协调者,整体组织和协调参与者,以保证事务最终提交或者回滚的角色。
2PC算法如下:
第一阶段:准备提交
阻塞协调者和所有参与者。- 协调者询问所有参与者
准备提交是否完成。 - 参与者开始事务提交前的准备工作。
- 如果参与者准备工作完成,则回复协调者
准备完成,否则回复准备失败。
第二阶段:正式提交
- 若任意参与者回复
准备失败:
- 则协调者向所有参与者发布命令
回滚。 - 所有参与者回滚事务,释放资源,并回复
回滚完成。 - 协调者收到全部
回滚完成之后回滚事务。
- 若全部参与者都回复
准备完成:
- 则协调者向所有参与者发布命令
开始提交。 - 所有参与者提交事务,释放资源,并回复
提交完成。 - 协调者收到全部
提交完成之后提交事务。
2PC是一种老式的分布式事务算法,主要问题在于:
- 从第一阶段开始阻塞所有参与者,极大影响性能。
- 在第二阶段,如果协调者挂掉,则参与者进入
不知所措状态。 - 面对网络超时,难以适从。
4.2.三阶段提交算法
二阶段提交,3-Phase Commit,简称3PC。3PC算法如下:
第一阶段:可否提交
- 协调者询问所有参与者
是否可以准备提交。 - 参与者开始确认自身资源是否可以准备提交。
- 如果参与者可以准备提交,则回复协调者
可以准备,否则回复无法准备。
第二阶段:准备提交
- 若任意参与者回复
无法准备:
- 则协调者向所有参与者发布命令
终止。 - 所有参与者终止操作。
- 若全部参与者都回复
可以准备:
第三阶段:正式提交
3PC比2PC多了一个阶段:第一阶段会先询问参与者能否准备提交,此阶段不阻塞资源。
3PC基于一个理论:如果第一阶段所有参与者返回成功,那么成功提交的概率很大。
3PC优于2PC的几个方面:
- 在询问阶段不阻塞资源,能够一定程度上提高性能。
- 在第三阶段,如果协调者挂掉,则能保证事务最终提交。
3PC同样也存在一个问题:面对网络超时,难以适从。
4.3.Paxos算法
Paxos 算法解决的问题是在一个可能发生上述异常的分布式系统中如何就某个值达成一致,保证不论发生以上任何异常,都不会破坏决议的一致性。
一个典型的场景是,在一个分布式数据库系统中,如果各节点的初始状态一致,每个节点都执行相同的操作序列,那么他们最后能得到一个一致的状态。
为保证每个节点执行相同的命令序列,需要在每一条指令上执行一个「一致性算法」以保证每个节点看到的指令一致。
Paxos算法基本上来说是个民主选举的算法――大多数的决定会成个整个集群的统一决定。
任何一个点都可以提出要修改某个数据的提案,是否通过这个提案取决于这个集群中是否有超过半数的结点同意(所以Paxos算法需要集群中的结点是单数)。
其实,2PC/3PC都是分布式一致性算法的残次版本,Google Chubby的作者Mike Burrows说过这个世界上只有一种一致性算法,那就是Paxos,其它的算法都是残次品。
Paxos算法保证在任何阶段被打断,都能保证最终的正确性。
由于本人水平有限,并未深入学习Paxos算法,所以只是给出了基本介绍,有需要的同学请自行了解。
5.分布式锁
在单机应用中,当多个线程访问共享资源时,我们通常通过synchronized关键字、Lock锁、线程安全对象等措施保证资源的安全使用。
在分布式环境下,上述措施不再能满足需求,这事,我们需要一种应用于分布式换件的加锁机制,即:分布式锁。
分布式锁的实现方式有多重,如:数据库、Redis、ZooKeeper等等。
关于分布式锁,可以参考本人的另一篇文章:Redis: 分布式锁的官方算法RedLock以及Java版本实现库Redisson
参考
- https://blog.csdn.net/ZytheMoon/article/details/84256896
- https://blog.csdn.net/zhangyuan19880606/article/details/51143628
- https://blog.csdn.net/a291382932/article/details/52567094
- https://blog.csdn.net/yfkiss/article/details/6967311
cs