?
01
题目信息
题目地址:
https://leetcode-cn.com/problems/first-unique-character-in-a-string/
给定一个字符串,找到它的第一个不重复的字符,并返回它的索引。如果不存在,则返回 -1。?(s只包含小写字母)
示例:
s?= "leetcode"?
返回 0?
s = "loveleetcode"?
返回 2
02
解法一:双指针
双指针比较,每指定一个值都要全文扫描有无重复
public?int?firstUniqChar(String s)?{
????char[] arr = s.toCharArray();
????int?n = arr.length;
????for(int?i = 0; i < n; i++){
????????boolean?flag = true;
????????//遍历每个值与当前值比较,有重复改false
????????for(int?j = 0; j < n; j++){
????????????if(i != j && arr[i] == arr[j]){
????????????????flag = false;
????????????}
????????}
????????//遍历完没有和当前值相同的
????????if(flag){
????????????return?i;
????????}
????}
????return?-1;
}

然后LeetCode的测试用例字符串也是真的长 (只截取了部分下面还可以翻页),所以在n^2的情况下超时。
(只截取了部分下面还可以翻页),所以在n^2的情况下超时。
03
解法二:细节优化(解一)
上面的解法是有可优化的点的。我们去查找第一个只出现一次的,那么一个值找到相同的后我们就不必要再往后了遍历因为不需要看它有几个相同的,它不满足就应该看下一个值也就是应该加上break。
for(int?j = 0; j < n; j++){
????if(i != j && arr[i] == arr[j]){
????????flag = false;
????????break;
????}
}
这一点是影响还是比较大的,第二点就是我们去判断遍历完了没有重复也就是找到了可以直接返回的处理我们除了定义flag在循环体标记,到循环去判断处理。其实我们去表达循环完后的处理也可以在循环体里面,也就是循环到最后了仍然不满足相等。
for(int?j = 0; j < n; j++){
????if(i != j && arr[i] == arr[j]){
????????break;
????}else?if(j == n-1){
????????return?i;
????}
}
这样和前面的就是同一个意思,并且少定义一个变量flag,并且最后我们的代码不会超时
public?int?firstUniqChar(String s)?{
????char[] arr = s.toCharArray();
????int?n = arr.length;
????for(int?i = 0; i < n; i++){
????????for(int?j = 0; j < n; j++){
????????????if(i != j && arr[i] == arr[j]){
? ? ? ? ? ? ? ??break;
? ? ? ? ? ? }else?if(j == n - 1){
? ? ? ? ? ? ? ??return?i;
? ? ? ? ? ? }
????????}
????}
????return?-1;
}
时间O(n^2),空间O(1)

?
04
解法三:Hash表
那么使用hash表去存信息,就不用重复遍历了
public?int?firstUniqChar(String s) {
????char[] arr = s.toCharArray();
????int?n = arr.length;
????HashMap<Character, Integer> count = new?HashMap<Character, Integer>();
????//遍历存下所有信息
????for?(int?i = 0; i < n; i++) {
????????char?c = arr[i];
????????count.put(c, count.getOrDefault(c, 0) + 1);
????}
????//遍历查看key值为1的
????for?(int?i = 0; i < n; i++) {
????????if?(count.get(arr[i]) == 1)
????????????return?i;
????}
????return?-1;
}
时间O(n),空间O(n),虽然如此但效率反而比双指针要差,这主要是它的这些方法。
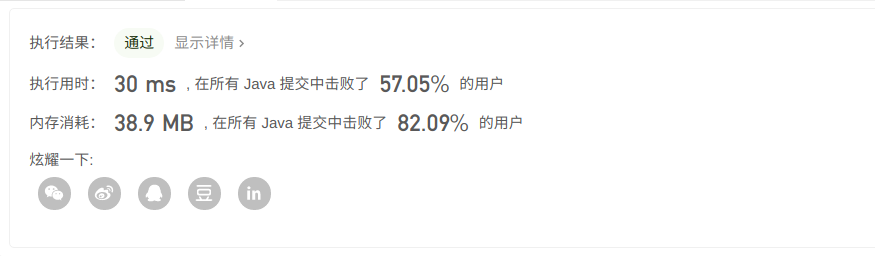
?
05
解法四:数组
用Hash表能存,那用数组也应该是可以的,一样的key位索引值判断是不是1。同一个字母就是同一个地方对应值就加一。统计完之后遍历字符串按字符串的顺序去数组查率先等于1的就返回
public?int?firstUniqChar(String s)?{
????int[] chars = new?int[26];
????char[] arr = s.toCharArray();
????for?(char?c : arr) {
????????chars[c - 'a'] += 1;
????}
????for?(int?i = 0; i < arr.length; ++i) {
????????if?(chars[arr[i] - 'a'] == 1) {
????????????return?i;
????????}
????}
????return?-1;
}
和解法二同样的一个思路选取数组这种数据结构,效率就直接上去了。
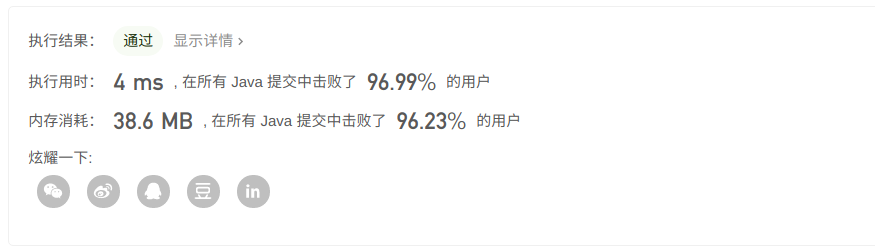
?
06
解法五:细节优化(解四)
上述数组解法在效率上仍然是有可优化点,因为我们去比较两个容器的时候谁短我们就遍历谁。更何况这里只需要拿值到另一个容器参考只需要一次遍历,那我们更应该遍历短的。那么当字符串长度小于26和上面一样遍历字符串到数组去记录,最后再遍历数组看结果,如果字符串长于26那么我们就遍历a-z这26个字母
int?result = -1;
for?(char?i = 'a'; i <= 'z'; ++i) {
????int?begin = s.indexOf(i);
????int?end = s.lastIndexOf(i)
????// 在字符串中存在该字符并且唯一
????if?(begin != -1?&& begin == end {
??????// 不仅要唯一,且索引还要小。遍历完成拿到字符串最前的唯一
??????result = (result == -1?|| result > begin) ? begin : result;
????}
}
那么在字符串长度很大的情况下也只需要完整遍历26次就能找到首个唯一,完整代码如下:
public?int?firstUniqChar(String s)?{
????int?result = -1;
????// 字符串长度不超过26
????if?(s.length() <= 26) {
????????int[] chars = new?int[26];
????????char[] arr = s.toCharArray();
????????for?(char?c : arr) {
????????????chars[c - 'a'] += 1;
????????}
????????for?(int?i = 0; i < arr.length; ++i) {
????????????if?(chars[arr[i] - 'a'] == 1) {
????????????????return?i;
????????????}
????????}
????}else{
? ? ? ? for?(char?i = 'a'; i <= 'z'; ++i) {
? ? ? ? ? ??int?begin = s.indexOf(i);
? ? ? ? ? ??int?end = s.lastIndexOf(i);
? ? ? ? ? ??if?(begin != -1?&& begin == end) {
? ? ? ? ? ? ? ? result = (result == -1?|| result > begin) ? begin : result;
? ? ? ? ? ? }
? ? ? ? }
? ? }
????return?result;
}
?

?
07
总结
?
题目难度呢属于简单,双指针、hash表这样成对的解法就出来了,主要是通过此题去回顾一些注意点比如双循环的优化,循环中字符串的方法频繁的进出也是有一定的浪费,可以先拿数组出来操作会好一点。适合体会解题迭代的一个流程。
?
cs