给定一个仅包含大小写字母和空格?' '?的字符串,返回其最后一个单词的长度。
如果不存在最后一个单词,请返回 0?。
说明:一个单词是指由字母组成,但不包含任何空格的字符串。
示例:
输入: "Hello World"
输出: 5
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/length-of-last-word
?
public int lengthOfLastWord(String s) {
if(s == null){
return 0;
}
s = s.trim();
if(s.equals("")){
return 0;
}
String[] split = s.split(" ");
return split[split.length-1].length();
}
实现?int sqrt(int x)?函数。
计算并返回?x?的平方根,其中?x 是非负整数。
由于返回类型是整数,结果只保留整数的部分,小数部分将被舍去。
示例 1:
输入: 4
输出: 2
示例 2:
输入: 8
输出: 2
说明: 8 的平方根是 2.82842...,?
?? ? 由于返回类型是整数,小数部分将被舍去。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/sqrtx
牛顿迭代法
下面这种方法可以很有效地求出根号 aa 的近似值:首先随便猜一个近似值 xx,然后不断令 xx 等于 xx 和 a/xa/x 的平均数,迭代个六七次后 xx 的值就已经相当精确了。
例如,我想求根号 22 等于多少。假如我猜测的结果为 44,虽然错的离谱,但你可以看到使用牛顿迭代法后这个值很快就趋近于根号 22 了:
( 4 + 2/ 4 ) / 2 = 2.25
( 2.25 + 2/ 2.25 ) / 2 = 1.56944..
( 1.56944..+ 2/1.56944..) / 2 = 1.42189..
( 1.42189..+ 2/1.42189..) / 2 = 1.41423..
….
作者:LOAFER
链接:https://leetcode-cn.com/problems/sqrtx/solution/niu-dun-die-dai-fa-by-loafer/
来源:力扣(LeetCode)
?
class Solution {
static int s;
public static int mySqrt(int x) {
s = x;
if(x==0) return 0;
return ((int)(sqrts(x)));
}
public static double sqrts(double x){
double res = (x + s / x) / 2;
if (res == x) {
return x;
} else {
return sqrts(res);
}
}
}
98. 验证二叉搜索树
给定一个二叉树,判断其是否是一个有效的二叉搜索树。
假设一个二叉搜索树具有如下特征:
节点的左子树只包含小于当前节点的数。
节点的右子树只包含大于当前节点的数。
所有左子树和右子树自身必须也是二叉搜索树。
示例?1:
输入:
? ? 2
? ?/ \
? 1 ? 3
输出: true
示例?2:
输入:
? ? 5
? ?/ \
? 1 ? 4
?? ? / \
?? ?3 ? 6
输出: false
解释: 输入为: [5,1,4,null,null,3,6]。
?? ? 根节点的值为 5 ,但是其右子节点值为 4 。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/validate-binary-search-tree
?
// Definition for a binary tree node.
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) {
val = x;
}
}
乍一看,这是一个平凡的问题。只需要遍历整棵树,检查 node.right.val > node.val 和
node.left.val < node.val 对每个结点是否成立。
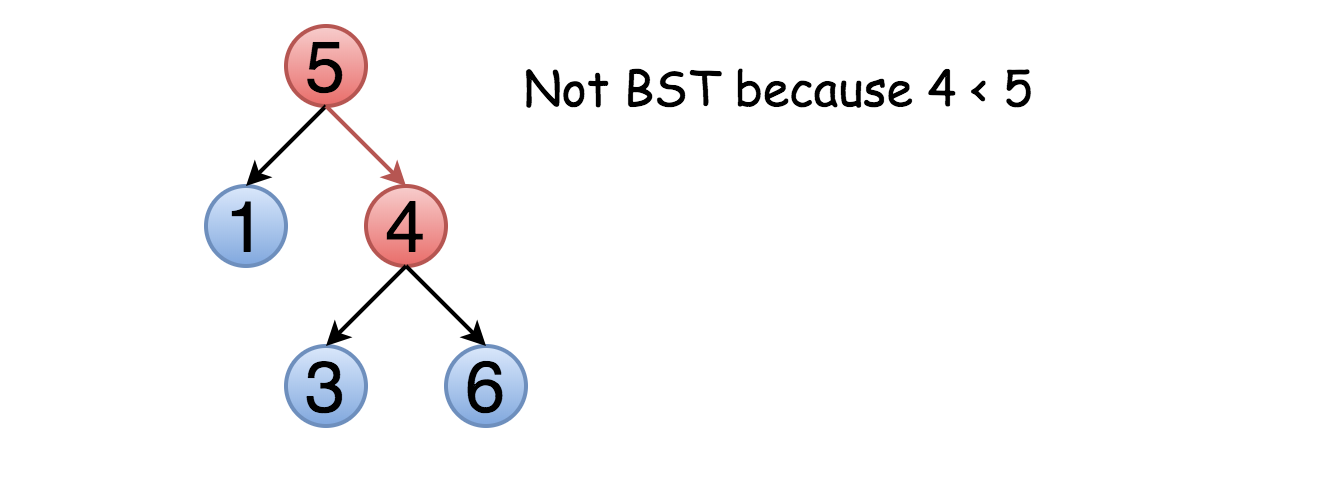
问题是,这种方法并不总是正确。不仅右子结点要大于该节点,整个右子树的元素都应该大于该节点。例如:
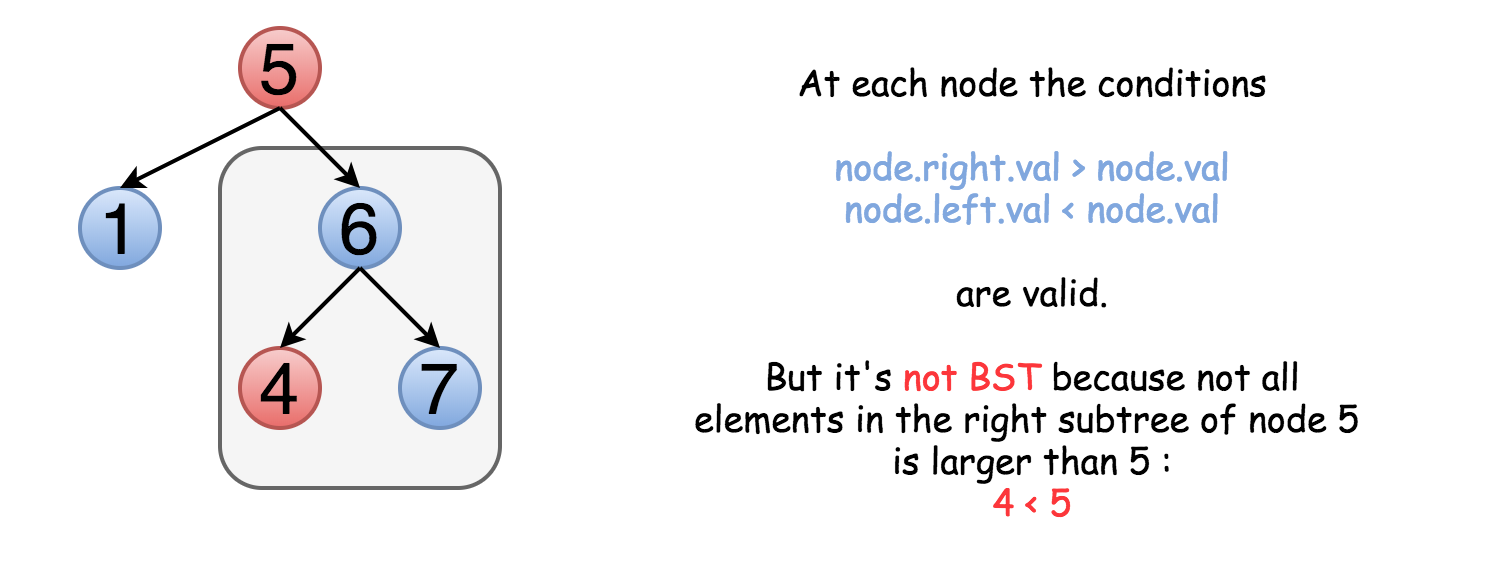
这意味着我们需要在遍历树的同时保留结点的上界与下界,在比较时不仅比较子结点的值,也要与上下界比较。

public boolean helper(TreeNode node, Integer lower, Integer upper) {
if (node == null) return true;
int val = node.val;
if (lower != null && val <= lower) return false;
if (upper != null && val >= upper) return false;
if (! helper(node.right, val , upper)) return false;
if (! helper(node.left, lower, val)) return false;
return true;
}
public boolean isValidBST(TreeNode root) {
return helper(root, null, null);
}
?
方法二: 迭代
通过使用栈,上面的递归法可以转化为迭代法。这里使用深度优先搜索,比广度优先搜索要快一些。
package demo4.tcyl;
import java.util.LinkedList;
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) { val = x; }
}
public class Main {
LinkedList<TreeNode> stack = new LinkedList();
LinkedList<Integer> uppers = new LinkedList();
LinkedList<Integer> lowers = new LinkedList();
public void update(TreeNode root, Integer lower, Integer upper) {
stack.add(root);
lowers.add(lower);
uppers.add(upper);
}
public boolean isValidBST(TreeNode root) {
Integer lower = null, upper = null, val;
update(root, lower, upper);
while (!stack.isEmpty()) {
root = stack.poll();
lower = lowers.poll();
upper = uppers.poll();
if (root == null) continue;
val = root.val;
if (lower != null && val <= lower) return false;
if (upper != null && val >= upper) return false;
update(root.right, val, upper);
update(root.left, lower, val);
}
return true;
}
}
14. 最长公共前缀
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串?""。
示例?1:
输入: ["flower","flow","flight"]
输出: "fl"
示例?2:
输入: ["dog","racecar","car"]
输出: ""
解释: 输入不存在公共前缀。
说明:
所有输入只包含小写字母?a-z?。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/longest-common-prefix
??

public static String longestCommonPrefix(String[] strs) {
if (strs.length == 0) return "";
String prefix = strs[0];
for (int i = 1; i < strs.length; i++)
while (strs[i].indexOf(prefix) != 0) {
prefix = prefix.substring(0, prefix.length() - 1);
if (prefix.isEmpty()) return "";
}
return prefix;
}
 ?
?
自己写的如下感觉好长
public static String longestCommonPrefix1(String[] strs) {
if(strs == null || strs.length == 0){
return "";
}
int len = Integer.MAX_VALUE;
String s = "";
for (int i = 0; i < strs.length; i++) {
if(strs[i].length() < len){
len = strs[i].length();
s = strs[i];
}
}
int i = 0;
out: for ( i = 0; i < len; i++) {
for (int j = 0; j < strs.length; j++) {
if(strs[j].charAt(i) == s.charAt(i) ){
continue;
}else{
break out;
}
}
}
return s.substring(0, i);
}
算法二:水平扫描
算法
想象数组的末尾有一个非常短的字符串,使用上述方法依旧会进行 S?次比较。优化这类情况的一种方法就是水平扫描。我们从前往后枚举字符串的每一列,先比较每个字符串相同列上的字符(即不同字符串相同下标的字符)然后再进行对下一列的比较。
?S 是所有字符串中字符数量的总和。
public String longestCommonPrefix(String[] strs) {
if (strs == null || strs.length == 0) return "";
for (int i = 0; i < strs[0].length() ; i++){
char c = strs[0].charAt(i);
for (int j = 1; j < strs.length; j ++) {
if (i == strs[j].length() || strs[j].charAt(i) != c)
return strs[0].substring(0, i);
}
}
return strs[0];
}

cs