如需转载请注明出处:https://juyou.blog.csdn.net/article/details/115716559
之前有写过 日常生活 – 嵌入式面试 ,讲了面试大部分都会问哪些问题。
也有自己总结了一些面试题:
- C语言再学习 – 详解C++/C 面试题 1
- C语言再学习 – 详解C++/C 面试题 2
下载:嵌入式C语言面试题汇总(超经典)
提取码:w779
但是每次我都要翻好几篇文章挨个看知识点,这就很烦了。现在将所用到的知识点在这篇文章内加以总结。
一、关键字
1、const
问题:
- 问题一:const有什么用途?(请至少说明两种)
(1)可以定义const常量
(2)const可以修饰函数的参数和返回值,甚至函数的定义体。被const修饰的东西都受到强制保护,可以预防意外的变动,能提高程序的健壮性。 - 问题二:以下的p和*p哪个可变,哪个不可变?
先忽略类型名(编译器解析的时候也是忽略类型名),我们看 const 离哪个近。“近水楼先得月”,离谁近就修饰谁。
int arr[5];
const int * p = arr; //const 修饰 * p,p 是指针,可变; * p 是指针指向的对象,不可变。
int const * p = arr; //const 修饰 * p,p 是指针, 可变; * p 是指针指向的对象,不可变。
int * const p = arr; //const 修饰 p, p 是指针,不可变; p 指向的对象可变。
const int * const p= arr; //前一个 const 修饰 * p,后一个 const 修饰 p,指针 p 和 p 指向的对象都不可变。 - 问题三:关键字const有什么含义?
const修饰的数据类型是指常类型,常类型的变量或对象的值是不能被更新的。或者说const意味着只读。
解答:
参看:C语言再学习 – 关键字const
const 修饰类型:
(1)const 修饰一般常量
(2)const修饰指针、数组
(3)const 修饰函数的形参和返回值
(4)const 修饰常对象
(5)const 修饰常引用
(6)const 修饰类的成员变量
(7)const 修饰类的成员函数
const 作用:
(1)可以定义 const 常量,具有不可变性。
(2)便于进行类型检查,使编译器对处理内容有更多了解,消除一些隐患。
(3)可以避免意义模糊的数字出现,同样可以很方便进行参数的调整和修改。同宏定义一样,可以做到不变则已,一变都变。
(4)可以保护被修改的东西,防止意外的修改,增强程序的健壮性。
(5)可以节省空间,避免不必要的内存分配。
(6)为函数重载提供了一个参考
(7)提高效率
const介绍:
(1)在定义该const 变量时,通常需要对它进行初始化,因为以后就没有机会再去改变它了;
(2)对指针来说,可以指定指针本身为const,也可以指定指针所指的数据为 const,或二者同时指定为const;
(3)在一个函数声明中,const可以修饰形参,表明它是一个输入参数,在函数内部不能改变其值;
(4)对于类的成员函数,若指定其为const 类型,则表明其是一个常函数,不能修改类的成员变量;
(5)对于类的成员函数,有时候必须指定其返回值为const 类型,以使得其返回值不为“左值”。
作用的话,可以保护被修改的东西,防止意外的修改,增强程序的健壮性。
2、static
问题:
- 问题一:关键static的作用是什么?
static 修饰全局变量
static 修饰局部变量
static 修饰函数
解答:
参看:C语言再学习 – 存储类型关键字
(1)static 修饰的全局变量也叫静态全局变量,该类具有静态存储时期、文件作用域和内部链接,仅在编译时初始化一次。如未明确初始化,它的字节都被设定为0。static全局变量只初使化一次,是为了防止在其他文件单元中被引用;利用这一特性可以在不同的文件中定义同名函数和同名变量,而不必担心命名冲突。
(2)static 修饰的局部变量也叫静态局部变量,该类具有静态存储时期、代码作用域和空链接,仅在编译时初始化一次。如未明确初始化,它的字节都被设定为0。函数调用结束后存储区空间并不释放,保留其当前值。
(3)static 修饰的函数也叫静态函数,只可以在定义它的文件中使用。
3、volatile
问题:
- 问题一:关键字volatile有什么含意?并给出三个不同的例子。
volatile关键字是一种类型修饰符。volatile的作用是作为指令关键字,确保本条指令不会因编译器的优化而省略,且要求每次直接读值。直接读值是指从内存重新装载内容,而不是直接从寄存器拷贝内容。
volatile使用:
(1)并行设备的硬件寄存器(如:状态寄存器)。
(2)一个中断服务子程序中会访问到的非自动变量。
(3)多线程应用中被几个任务共享的变量。
解答:
参看:C语言再学习 – 关键字volatile
4、sizeof
问题:
- 问题一:以下为Windows NT下的32位C++程序,请计算sizeof的值。
void Func ( char str[100])
{
请计算:
sizeof( str ) = 4
}
char str[] = “Hello” ;
char *p = str ;
int n = 10;
请计算:
sizeof (str ) = 6
sizeof ( p ) = 4
sizeof ( n ) = 4
void *p = malloc( 100 );
请计算:
sizeof ( p ) = 4 - 问题二:在 32 位系统下:short * p =NULL;sizeof( p )的值是多少?sizeof( * p)呢?
sizeof ( p ) = 4; 因为 p为指针,32位系统 指针所占字节为 4个字节
sizeof ( *p ) = 2; 因为 *p 为 指针所指向的变量为int类型,short为 2个字节 - 问题三:请计算sizeof的值
int a[100];
sizeof (a) = 400; // 因为 a是类型为整型、有100个元素的数组,所占内存为400个字节
sizeof (a[100]) = 4; //因为 a[100] 为数组的第100元素的值该值为 int 类型,所占内存为4个字节。
sizeof (&a) = 4; //因为 &a 为数组的地址即指针,32位系统 指针所占字节为 4个字节
sizeof (&a[0]) = 4; //因为&a[0] 为数组的首元素的地址即指针,32位系统 指针所占字节为 4个字节
解答:
参看:C语言再学习 – 关键字sizeof与strlen
(1)sizeof 操作符以字节形式给出了其操作数的存储大小。操作数可以是一个表达式或括在括号内的类型名。操作数的存储大小由操作数的类型决定。
在windows,32位系统中
char 1个字节
short 2个字节
int 4个字节
long 4个字节
double 8个字节
float 4个字节
(2)数据类型必须用圆括号括住。如:sizeof (int)
记住这两句话:
在 32 位系统下,不管什么样的指针类型,其大小都为 4 byte。
参数传递数组永远都是传递指向数组首元素的指针。
5、extern
问题:
- 问题一:在C++程序中调用被C编译器编译后的函数,为什么要加extern “C”声明?
C++语言支持函数重载, C 语言不支持函数重载。函数被 C++编译后在库中的名字与 C 语言的不同。假设某个函数的原型为: void foo(int x, int y);该 函 数 被 C 编 译 器 编 译 后 在 库 中 的 名 字 为 _foo, 而 C++编 译 器 则 会 产 生 像_foo_int_int 之类的名字。C++提供了 C 连接交换指定符号 extern“ C”来解决名字匹配问题。
解答:
参看:C语言再学习 – 存储类型关键字
C 程序中,不允许出现类型不同的同名变量。而C++程序中 却允许出现重载。重载的定义:同一个作用域,函数名相同,参数表不同的函数构成重载关系。因此会造成链接时找不到对应函数的情况,此时C函数就需要用extern “C”进行链接指定,来解决名字匹配问题。简单来说就是,extern “C”这个声明的真实目的是为了实现C++与C及其它语言的混合编程。
二、字符串
1、strcpy 函数功能实现
问题:
- 问题一:编写 strcpy 函数
已知 strcpy 函数的原型是
char *strcpy(char *strDest, const char *strSrc);
其中 strDest 是目的字符串, strSrc 是源字符串。
(1)不调用 C++/C 的字符串库函数,请编写函数 strcpy
char *strcpy(char *strDest, const char *strSrc);
{
assert((strDest!=NULL) && (strSrc !=NULL)); // 2分
char *address = strDest; // 2分
while( (*strDest++ = * strSrc++) != ‘\0’ ) // 2分
NULL ;
return address ; // 2分
}
(2) strcpy 能把 strSrc 的内容复制到 strDest,为什么还要 char * 类型的返回值?
答:为了实现链式表达式。 // 2 分
例如 int length = strlen( strcpy( strDest, “hello world”) );
2、字符串的翻转
问题:
- 问题一:字符串的翻转实现
实现逻辑,就是将字符串从中间一分为二,互相换位置即完成了翻转的效果void rechange_str(char *str)
{
int i, len;
char tmp;
if (NULL == str) {
return ;
}
len = strlen(str);
for (i = 0; i < len/2; i ++) {
tmp = str[i];
str[i] = str[len-i-1];
str[len-i-1] = tmp;
}
}
3、strcpy和memcpy区别
问题:
- 问题一:strcpy和memcpy区别?
(1)复制的内容不同。strcpy只能复制字符串,而memcpy可以复制任意内容,例如字符数组、整型、结构体、类等。
(2)复制的方法不同。strcpy不需要指定长度,它遇到被复制字符的串结束符"\0"才结束,所以容易溢出。memcpy则是根据其第3个参数决定复制的长度。
(3)用途不同。通常在复制字符串时用strcpy,而需要复制其他类型数据时则一般用memcpy。
解答:
参看:C语言再学习 – 字符串和字符串函数
剩下的像strcat、strlen、atoi、itoa函数功能实现,自行查看。
三、大小端
问题:
#include <stdio.h>
#icnlude <arpa/inet.h>
int main (void)
{
union
{
short i;
char a[2];
}u;
u.a[0] = 0x11;
u.a[1] = 0x22;
printf ("0x%x\n", u.i); //0x2211 为小端 0x1122 为大端
printf ("0x%.x\n", htons (u.i)); //大小端转换
return 0;
}
输出结果:
0x2211
0x1122
- 问题二:大小端应用场景?
一般操作系统都是小端,而通讯协议是大端的。
大小端是由CPU和操作系统来决定的,在操作系统中,x86和一般的OS(如windows,FreeBSD,Linux)使用的是小端模式,但比如Mac OS是大端模式。
在网络上传输数据时,由于数据传输的两端对应不同的硬件平台,采用的存储字节顺序可能不一致。所以在TCP/IP协议规定了在网络上必须采用网络字节顺序,也就是大端模式。
解答:
参看:C语言再学习-- 大端小端详解(转)
一般都是采用 union 来判断机器的字节序。
union 型数据所占的空间等于其最大的成员所占的空间。 对 union 型的成员的存取都是相对于该联合体基地址的偏移量为 0 处开始,也就是联合体的访问不论对哪个变量的存取都是从 union 的首地址位置开始。
联合是一个在同一个存储空间里存储不同类型数据的数据类型。 这些存储区的地址都是一样的,联合里不同存储区的内存是重叠的,修改了任何一个其他的会受影响。
现在明白了,我们为什么用 union 联合来测试大小端,在联合变量 u 中, 短整型变量 i 和字符数组 a 共用同一内存位置。给 a[0]、a[1] 赋值后,i 也是从同一内存地址读值的。
四、预处理
问题:
-
问题一:用预处理指令#define 声明一个常数,用以表明1年中有多少秒(忽略闰年问题)
#define SENCONDS_PER_YEAR (60 * 60 * 24 * 365)UL
#define 声明一个常量,使用计算常量表达式的值来表明一年中有多少秒,显得就更加直观了。再有这个表达式的值为无符号长整形,因此应使用符号 UL。
-
问题二:写一个“标准”宏MIN ,这个宏输入两个参数并返回较小的一个。
#define MIN(A,B) ((A) <= (B) ? (A) : (B))
实现输入两个参数并返回较小的一个,应使用三目表达式。使用必须的足够多的圆括号来保证以正确的顺序进行运行和结合。
-
问题三:#include <filename.h>和#include “filename.h”有什么区别?
对于#include <filename.h> ,编译器从标准库路径开始搜索 filename.h
对于#include “filename.h” ,编译器从用户的工作路径开始搜索 filename.h
-
问题四:计算值?
#define N 3
#define Y(n) ((N+1)*n)
执行语句z=2*(N+Y(5+1));
变量z的值为(B ).
A:42 B:48 C:54 D:出错
2*(N+Y(5+1)); =》 2*(3+(3+1)*5+1) =》 48
若有宏定义:#define MOD(x,y) x%y
则执行以下语句后的输出结果是
int a=13,b=94;
printf(″%d\n″,MOD(b,a+4));
A.5
B.7
C.9
D.11
所以实际上计算的结果是MOD(b,a+4),即printf(″%d\n″,b%a+4);b%a=3,所结果是3+4=7
解答:
参看:C语言再学习 – C 预处理器
使用#define需要注意下面几点:
(1)宏的名字中不能有空格,但是在替代字符串中可以使用空格。ANSI C 允许在参数列表中使用空格。
(2)用圆括号括住每个参数,并括住宏的整体定义。
(3)用大写字母表示宏函数名,便于与变量区分。
(4)有些编译器限制宏只能定义一行。即使你的编译器没有这个限制,也应遵守这个限制。
(5)宏的一个优点是它不检查其中的变量类型,这是因为宏处理字符型字符串,而不是实际值。
(6)在宏中不要使用增量或减量运算符。
五、位操作
问题:
- 问题一:嵌入式系统总是要用户对变量或寄存器进行位操作。给定一个整型变量a,写两段代码,第一个设置a的bit 3,第二个清除a 的bit 3。在以上两个操作中,要保持其它位不变。
#define BIT3 (0x1 << 3)
static int a;
void set_bit3 (void)
{
a |= BIT3;
}
void clear_bit3 (void)
{
a &= ~BIT3;
}
- 问题二:不用临时变量交换两个数的值
通过按位异或实现:#include <stdio.h>
int main(int argc, char *argv[])
{
int a = 2, b = 6;
a = a ^ b;
b = b ^ a;
a = a ^ b;
printf("a = %d b = %d/n", a, b);
return 0;
}
结果如下:
a = 6 b = 2
或者:
#include <stdio.h>
int main(int argc, char *argv[])
{
int a = 2, b = 6;
a = a + b;
b = a - b;
a = a - b;
printf("a = %d b = %d/n", a, b);
return 0;
}
结果如下:
a = 6 b = 2
解答:
参看:C语言再学习 – 位操作
六、编译
问题:
- 问题一:GCC编译过程?
整个过程中可以划分为以下的4步流程:
(1)预处理/预编译: 主要用于包含头文件的扩展,以及执行宏替换等 //加上 -E
(2)编译:主要用于将高级语言程序翻译成汇编语言,得到汇编语言 //加上 -S
(3)汇编:主要用于将汇编语言翻译成机器指令,得到目标文件 //加上 -c
(4)链接:主要用于将目标文件和标准库链接,得到可执行文件 //加上 -o - 问题二:交叉编译和GCC编译有什么区别?
本地编译:在当前编译平台下编译出来的程序只能在当前平台下运行。
交叉编译:在当前编译平台下,编译出来的程序能运行在体系结构不同的另一种目标平台上,但是编译平台本身却不能运行该程序。
gcc编译:
#file libmosquitto.so.1
libmosquitto.so.1: ELF 32-bit LSB shared object, Intel 80386, version 1 (SYSV), dynamically linked,
BuildID[sha1]=0xb05795243eded68d65abe39b12212099c849965b, not stripped
arm-none-linux-gnueabi-gcc 交叉编译:
#file libmosquitto.so.1
libmosquitto.so.1: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked, not stripped
解答:
参看:C语言再学习 – GCC编译过程
七、栈溢出
问题:
- 问题一:栈溢出产生原因?
(1)局部数组变量空间太大
(2)函数出现无限递归调用或者递归层次太深 - 问题二:栈溢出解决方法?
(1)动态内存分配
(2)增大栈空间
(3)找到使用递归的地方,并消除BUG
解答:
参看:C语言再学习 – Stack Overflow(堆栈溢出)
八、指令
问题:
- 问题一:如何在目录下查找一个文件?
find . -name test.c - 问题二:如何列出匹配的文件名?
grep -l ‘main’ *.c
将列出当前目录下所有以”.c”结尾且文件中包含’main’字符串的文件名。
解答:
参看:C语言再学习 – Linux下find命令用法
参看:C语言再学习 – grep 命令(转)
其他指令:
参看:UNIX再学习 – ps、top、kill 指令
参看:C语言再学习 – Xargs用法详解
参看:C语言再学习-- readelf、objdump、nm使用详解
参看:C语言再学习 – dmesg 命令
参看:C语言再学习 – Linux 中常用基本命令
参看:C语言再学习 – vim常用快捷键(转)
参看:C语言再学习 – 常用快捷键
九、数据结构及算法
问题:
- 问题一:二分查找、冒泡排序、快速排序、单链表插入、时间复杂度
- 问题二:什么是平衡二叉树?
左右子树都是平衡二叉树 且左右子树的深度差值的绝对值不大于1。 - 问题三:冒泡排序算法的时间复杂度是什么?
O(n^2)
用大 O 记号表示算法的时间性能,将基本语句执行次数的数量级放入大 O 记号中。
大 O 中的 O 的意思就是"order of"(大约是)。
解答:
参看:数据结构与算法 – 算法
十、进程
问题:
解答:
参看:UNIX再学习 – 进程环境
1、进程的概念主要有两点:
第一,进程是一个实体。 每一个进程都有它自己的地址空间,一般情况下,包括文本区域(text region)、数据集区域(data region)和堆栈(stack region)。文本区域存储处理执行的代码;数据区域存储变量和基础讷航执行期间使用的动态分配的内存;堆栈区域存储着活动过程调用的指令和本地变量。
第二,进程是一个“执行中的程序”。 程序是一个没有生命的实体,只有处理器赋予程序生命时(操作系统执行它),它才能成为一个活动的实体,我们称其为进程。
2、程序和进程的区别:
而程序是指令和数据的有序集合,其本身没有任何运行的含义,是一个静态的概念。而进程是程序在处理机上的一次执行过程,它是一个动态的概念。程序可以作为一种软件资料长期存在,而进程是一定生命周期的。程序时永久的,进程是暂时的。进程更能真是地描述并发,而程序不能。进程具有创建其他进程的功能,而程序没有。同一个程序同时运行于若干个数据集合上,它将属于若干个不同的进程,也就是说同一个程序可以对应多个进程。在传统的操作系统中,程序并不能独立运行,作为资源分配和独立运行的基本单元都是进程。
3、进程的特征
动态性: 进程的实质是程序在多道程序系统中的一次执行过程,进程是动态产生,动态消亡的。
并发性: 任何进程都可以同其他进程一起并发执行。
独立性: 进程是一个能独立运行的基本单位,同时也是系统分配资源和调度的独立单位。
异步性: 由于进程间的相互制约,使进程具有执行的间断性,即进程按各自独立的,不可预知的速度向前推进。
结构特征: 进程有程序、数据、和进程控制块三部分组成。
多个不同的进程可以包含相同的程序: 一个程序在不同的数据集里就构成不同的进程,能得到不同的结果;但是执行过程中,程序不能发生改变。
4、进程终止
有 8 种方式使进程终止,其中 5 种为正常终止,它们是:
(1)从 main 返回
(2)调用 exit
(3)调用 _exit 或 _Exit
(4)最后一个线程从其启动例程返回
(5)从最后一个线程调用 pthread_exit
异常终止有 3 种方式,它们是:
(6)调用 abort
(7)接到一个信号
(8)最后一个线程对取消请求做出响应。
十一、线程
问题:
解答:
参看:UNIX再学习 – 线程
线程和进程的关系:
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个主线程。它们共享进程的地址空间;而进程有自己独立的地址空间。
(2)同一进程内的所有线程共享该进程的所有资源。
(3)线程作为调度和分配的基本单位,进程作为拥有资源的基本单位。
(4)进程是拥有资源的一个独立单位,线程不拥有系统资源,但可以访问隶属于进程的资源。
(5)在创建或撤销进程时,由于系统要为之分配和回收资源,导致系统的开销大于创建或撤销线程时的开销。
(6)不仅进程之间可以并发执行,同一个进程的多个线程之间也可并发执行。
十二、线程同步
问题:
- 问题一:线程同步有几种方法?
线程同步方式:互斥量、读写锁、条件变量、自旋锁。 - 问题二:什么是死锁?
所谓死锁: 是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。 - 问题三:死锁的四种产生条件是什么?
虽然进程在运行过程中,可能发生死锁,但死锁的发生必须具备一定的条件,死锁的发生必须具有以下四个必要条件。
(1)互斥条件
指进程对所分配的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用完释放。
(2)请求和保持条件
只进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持不放。
(3)不剥夺条件
只进程已获得的资源,在未使用之前,不能被剥夺,只能在使用完时由自己释放。
(4)环路等待条件
只在发生死锁时,必然在一个进程 – 资源的环形链,即进程集合{P0, P1, P2 …, Pn} 中的 P0 正在等待一个 P1 占用的资源;P1 正在等待 P2 占用的资源,…,Pn正在等待已被 P0 占用的资源。 - 问题四:如何避免死锁?
在有些情况下死锁是可以避免的。三种用于避免死锁的技术:
(1)加锁顺序(线程按照一定的顺序加锁)
(2)加锁时限(线程尝试获取锁的时候加上一定的时限,超过时限则放弃对该锁的请求,并释放自己占有的锁)
(3)死锁检测
解答:
参看:UNIX再学习 – 线程同步
十三、进程间通信
问题:
- 问题一:进程间通信有几种方式?
进程间通信 (IPC)方式有:
(1)管道
(2)消息队列
(3)信号量
(4)共享存储
(5)套接字(socket)
其中消息队列、信号量、共享存储统称为 XSI IPC通信方式。
解答:
参看:UNIX再学习 – 进程间通信之管道
参看:UNIX再学习 – XSI IPC通信方式
参看:UNIX再学习 – 网络IPC:套接字
简单介绍以下 :
信号量:广泛用于进程或线程间的同步和互斥
消息队列:是消息的链表,存放在内存中,由内核维护
管道:最简单、数据只能读取?次半双?、匿名管道只能是有?缘的关系间通信:
命名管道:?于没有?缘关系之间的进程间通信
共享内存:效率?、不需要太多次的数据拷?,可以直接进?读写,缺点是不能保证数据同步,只能借助信号量保证同步
信号:简单、携带的信息量少,使?在特定的场景,优先级?。建议不要使?信号进?进程间通信,因为信号的优先级?会打破原有进程的执?过程
socket:主要?于?络中的进程间通信,通信过程以及数据复杂,但安全可靠。
十四、TCP和UDP
问题:
- 问题一:TCP和UDP的区别?
(1)UDP 不提供客户机与服务器的连接,而TCP 提供客户机与服务器的连接;
(2)UDP 不保证数据传输的可靠性和有序性,而TCP 保证数据传输的可靠性和有序性;
(3)UDP 不提供流量控制,而TCP 提供流量控制;
(4)UDP 是记录式传输协议,而TCP 是流式传输协议;
(5)UDP 是全双工的,TCP 也是全双工的。
解答:
参看:UNIX再学习 – TCP/UDP 客户机/服务器
十五、TCP协议中的三次握手和四次挥手
问题:
解答:
参看:TCP协议中的三次握手和四次挥手(图解)
三次握手:
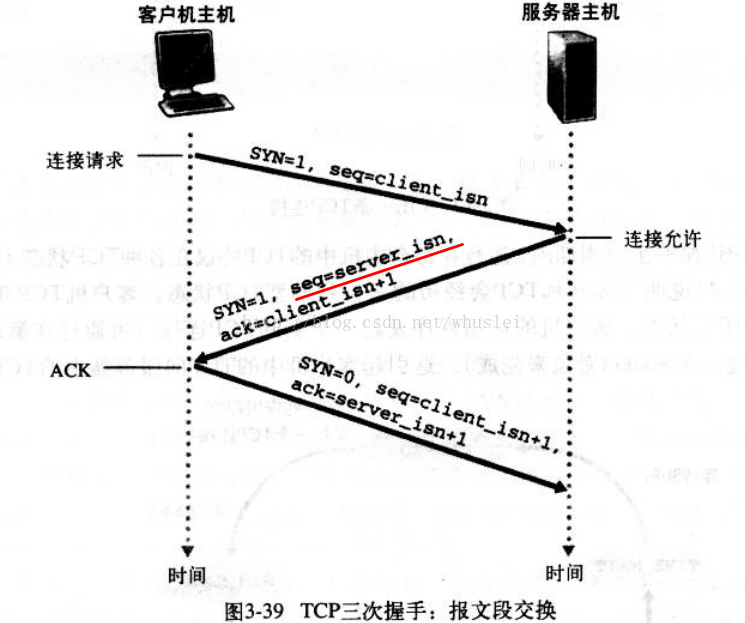
- (1)首先Client端发送连接请求报文,
- (2)Server段接受连接后回复ACK报文,并为这次连接分配资源。
- (3)Client端接收到ACK报文后也向Server段发送ACK报文,并分配资源,
这样TCP连接就建立了。
四次挥手:
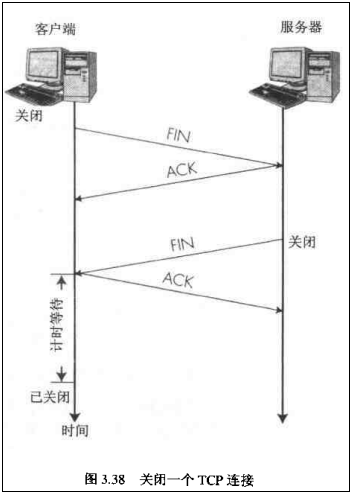
- (1)假设Client端发起中断连接请求,也就是发送FIN报文。
- (2)Server端接到FIN报文后,意思是说"我Client端没有数据要发给你了",但是如果你还有数据没有发送完成,则不必急着关闭Socket,可以继续发送数据。所以你先发送ACK,“告诉Client端,你的请求我收到了,但是我还没准备好,请继续你等我的消息”。这个时候Client端就进入FIN_WAIT状态,继续等待Server端的FIN报文。
- (3)当Server端确定数据已发送完成,则向Client端发送FIN报文,“告诉Client端,好了,我这边数据发完了,准备好关闭连接了”。
- (4)Client端收到FIN报文后,"就知道可以关闭连接了,但是他还是不相信网络,怕Server端不知道要关闭,所以发送ACK后进入TIME_WAIT状态,如果Server端没有收到ACK则可以重传。“,Server端收到ACK后,“就知道可以断开连接了”。Client端等待了2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,我Client端也可以关闭连接了。
Ok,TCP连接就这样关闭了!
【问题1】为什么连接的时候是三次握手,关闭的时候却是四次握手?
- 答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,“你发的FIN报文我收到了”。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
【问题2】为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
- 答:虽然按道理,四个报文都发送完毕,我们可以直接进入CLOSE状态了,但是我们必须假象网络是不可靠的,有可以最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。
十六、ISO/OSI 网络协议模型
问题:
解答:
参看:UNIX再学习 – 网络与网络协议
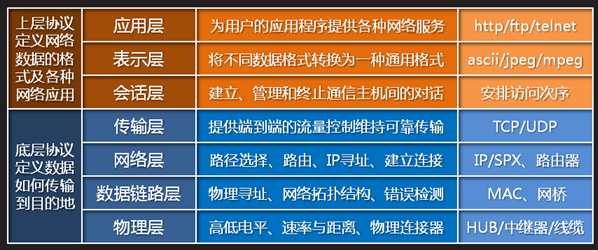
主要关注:
应用层:HTTP/FTP等
传输层:TCP/UDP协议
网络层:IP协议 ICMP协议
MQTT:使用TCP/IP提供基础网络连接。
十七、linux启动流程
问题:
解答:
参看:S5PV210开发 – 启动流程
iROM启动流程:
S5PV210启动过程分为BL0、BL1、BL2三个阶段,S5PV210内部有96Kb的IRAM和64Kb的IROM。S5PV210启动过程如下图:
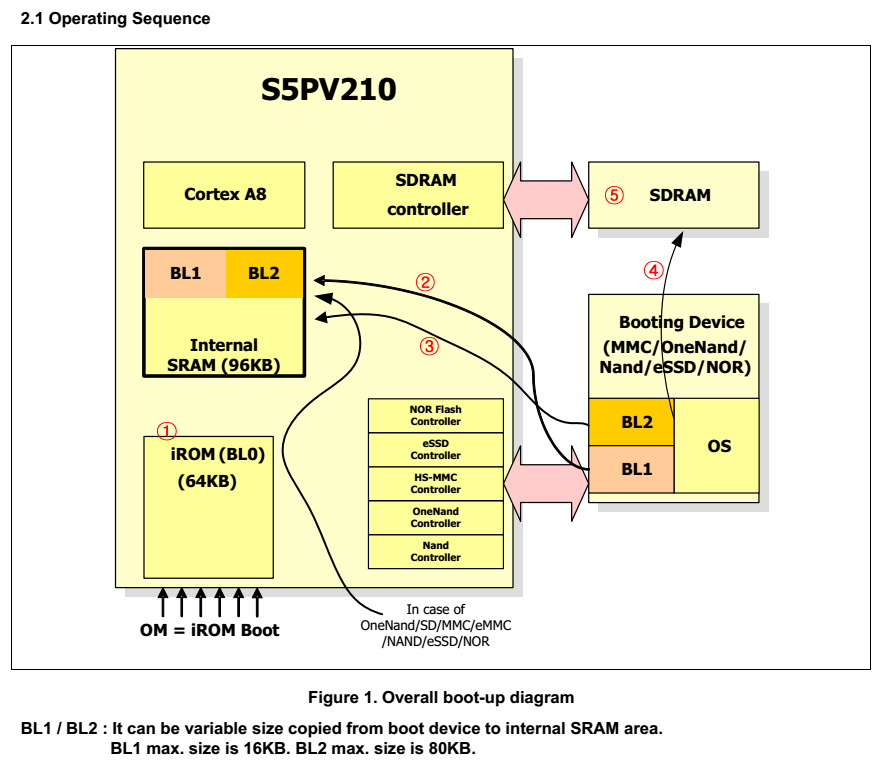
注释:其中 BL1 最大 16KB,BL2 最大 80KB
第一步:iROM初始化,初始化系统时钟、特殊设备控制寄存器和启动设备
第二步:iROM启动代码加载BL1(bootloader)到iRAM,在安全启动模式下iROM对BL1进行整体校验。
第三步:执行BL1,BL1加载BL2(剩余的bootloader)到iRAM,BL1将会对BL2进行整体校验。