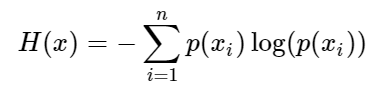from tensorflow.examples.tutorials.mnist.input_data import read_data_sets
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
mnist= read_data_sets('./MNIST_data',one_hot=True)
input_size = 784
output_size = 10
x = tf.placeholder(tf.float32,[None,input_size])
y = tf.placeholder(tf.float32,[None,output_size])
w = tf.Variable(tf.random_normal(shape=(input_size,output_size),dtype=tf.float32))
bias = tf.Variable(tf.zeros(output_size,dtype=tf.float32))
y_predict=tf.nn.softmax(tf.matmul(x,w)-bias)
loss=tf.reduce_mean(
-tf.reduce_sum(y * tf.log(y_predict),axis=1)
)
opt=tf.train.GradientDescentOptimizer(learning_rate=0.1)
train_op = opt.minimize(loss)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
iter = 5001
all_cost = []
for i in range(iter):
x_batch,y_batch = mnist.train.next_batch(100)
t,cost = sess.run([train_op,loss],feed_dict={x:x_batch,y:y_batch})
all_cost.append(cost)
if i%100 == 0:
print(f"Ек{i}ДЮбЕСЗ".center(50,'='))
print(f'Ы№ЪЇжЕЮЊ:{cost}')
plt.plot(range(iter) ,all_cost)
plt.xlabel('Times')
plt.ylabel('Loss')
plt.show()
mnist.test.images
mnist.test.labels
y_pre = sess.run(y_predict,feed_dict={x:mnist.test.images})
y_pre_labels = np.argmax(y_pre,axis=1)
print("зюКѓвЛеХЭМЕФгыдЄВтжЕЮЊ:",y_pre_labels[9999])
y_real_labels = np.argmax(mnist.test.labels,axis=1)
print("зюКѓвЛеХЭМЦЌЕФжЕЮЊ:",plt.imshow(mnist.test.