现象
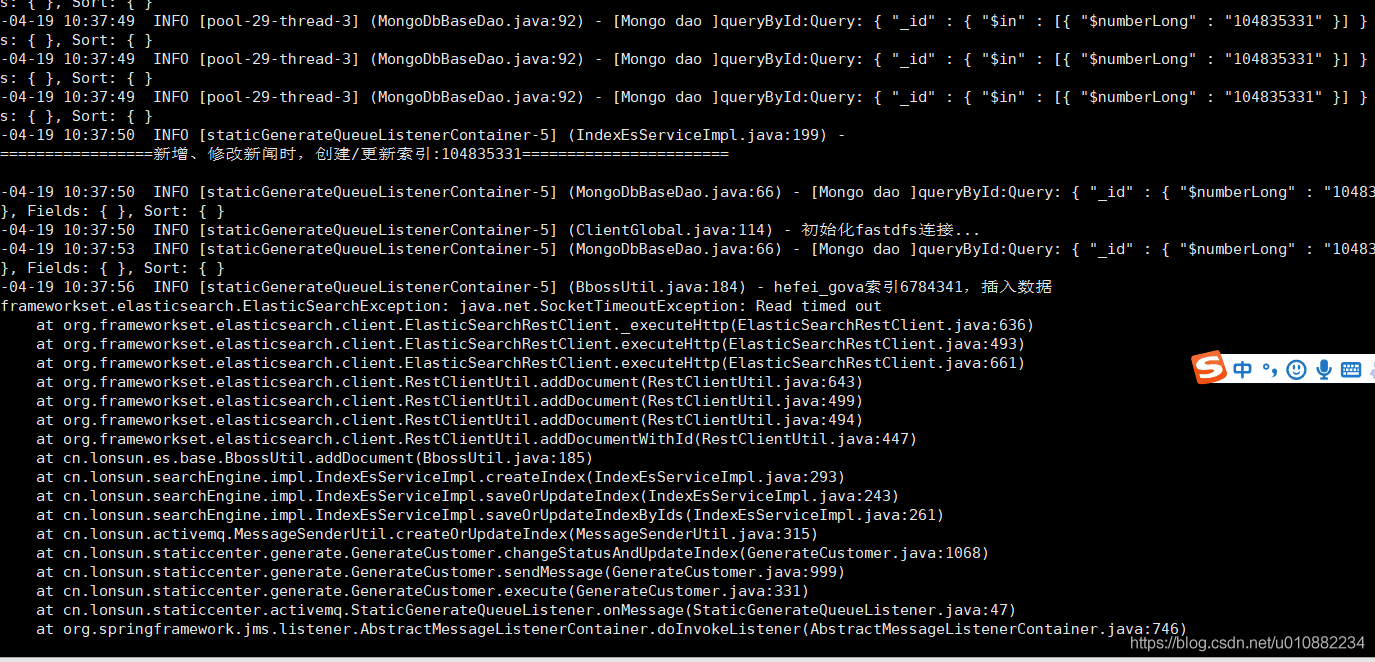
- 前一天晚上重建了部分索引,大概几万条吧;第二天早上发现搜索有问题。
- 使用Bboss封装的http接口查询、更新、删除索引失败
- 使用es的java api查询是可以的,更新删除没有测试
- 报错:
ElasticSearchException: Socket Timeout for 120000ms - 3个节点,一主二副,jvm参数配置为16G。
- 索引分片为3,副本为2,
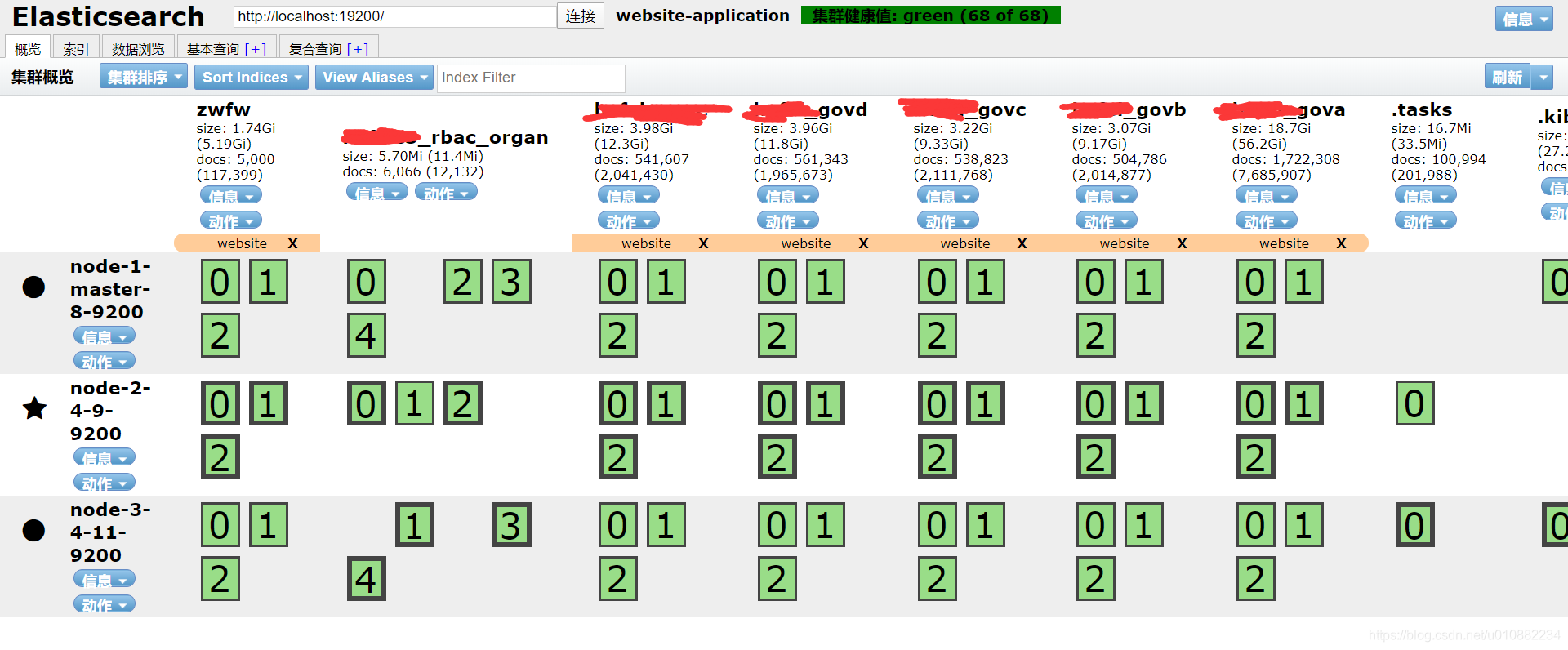
{"settings":{"index":{"number_of_shards":3,"number_of_replicas":2}}} - 使用head插件查看,发现集群状态是GREEN,绿色健康状态
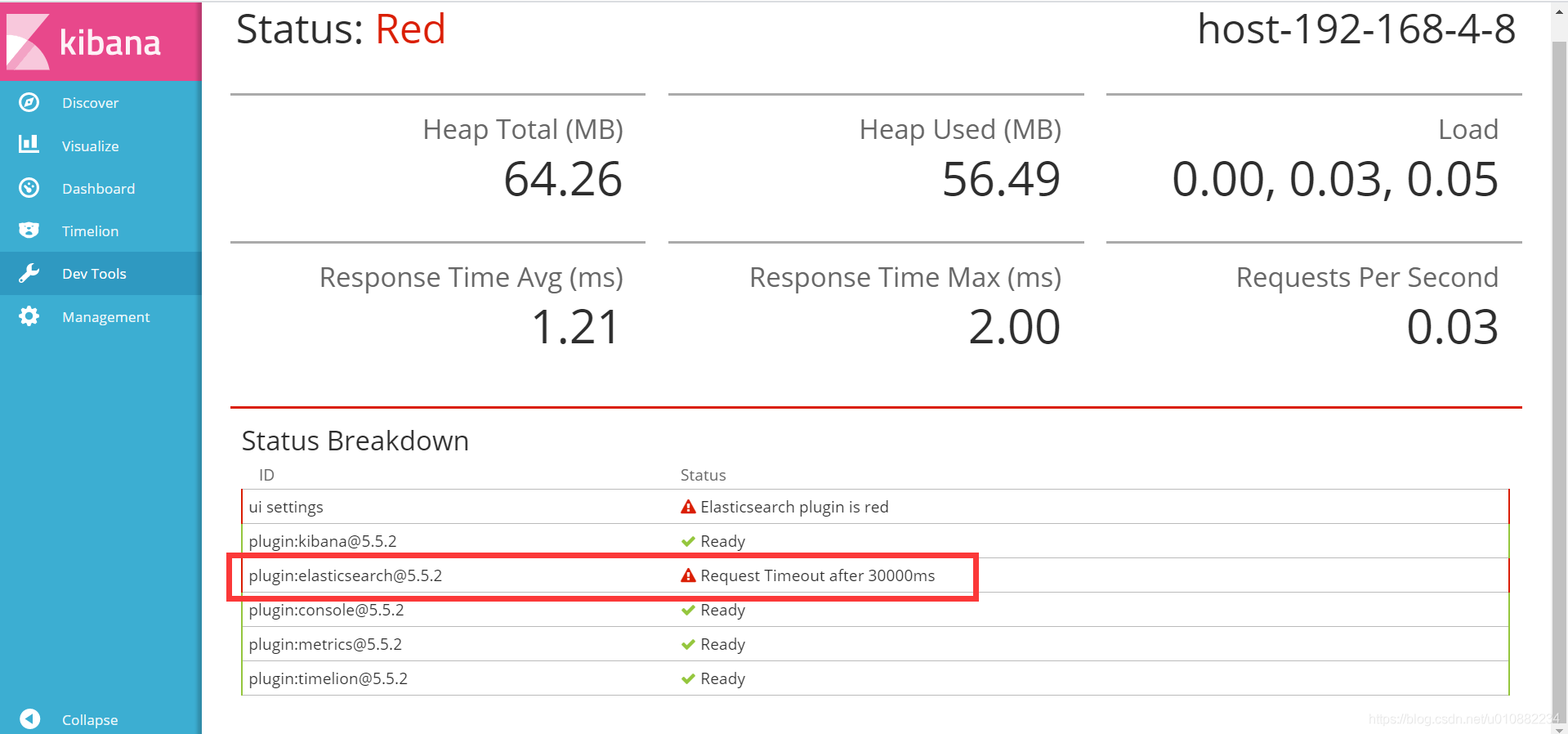
- 使用kibana查看,发现集群是RED状态,显示插件错误,连接超时
Elasticsearch plugin is red,Request timeout after 30000ms。 - 在网上搜了后,找到了官方论坛的一个帖子(链接),和我现象一样。
- 确认是集群状态问题,为了解决问题,只有先重启了。3个节点逐个重启的,每个重启后,稍微等待2分钟,让集群分片同步,当集群变为GREEN时,重启下一个节点。
- 重启第一个节点后,查询获取索引正常了,更新和删除索引仍然报错
- 重启完3个节点后,所有操作恢复正常
- 重启后某个索引数据量, 75G – 》 56G,感觉数据丢失了(
惊恐) - 随机找了一部分数据,搜索,发现数据都在,有点搞不清楚状况,难道是删除了一部分重复的没同步好的数据?(
暂未明白原因)