Ubuntu18.04 安装部署Hadoop & Hbase
OS: Ubuntu18.04 Server
VMware
本文所需所有数据包均需从官网下载
配置ssh免密登陆
ssh localhost
exit
cd ~/.ssh/
ssh-keygen -t rsa
连续敲击三次回车
其中,第一次回车是让KEY存于默认位置,以方便后续的命令输入。第二次和第三次是确定passphrase,相关性不大。之后再输入:
cat ./id_rsa.pub >> ./authorized_keys
ssh localhost
配置Java环境
安装JDK
解压JDK并重命名
tar -vxzf jdk-8u251-linux-x64.tar.gz
sudo mv jdk-8u251-linux-x64 java
将解压好的JDK传输到自己的文件夹
sudo cp -r java /usr/local
配置JDK
设置环境变量
vim /etc/profile
在末尾添加
JAVA_HOME=/usr/local/java
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
export JAVA_HOME
export PATH
重新加载环境变量的配置文件
source /etc/profile
检测
java -version
结果
java version "1.8.0_251" Java(TM) SE Runtime Environment (build 1.8.0_251-b08) Java HotSpot(TM) 64-Bit Server VM (build 25.251-b08, mixed mode
安装配置Hadoop
安装Hadoop
解压并重命名
tar -vxzf hadoop-2.9.2.tar.gz
mv hadoop-2.9.2 hadoop
移动文件夹
sudo cp -r hadoop /usr/local
修改文件拥有者为当前用户
sudo chown -R 当前用户名 ./hadoop
设置环境变量
sudo vim /etc/profile
添加以下内容
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
重载
source /etc/profile
检测
hadoop version
返回结果:
Hadoop 2.9.2 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 826afbeae31ca687bc2f8471dc841b66ed2c6704 Compiled by ajisaka on 2018-11-13T12:42Z Compiled with protoc 2.5.0 From source with checksum 3a9939967262218aa556c684d107985 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-2.9.2.jar
修改配置文件
xml修改的部分均为
<configuration>
</configuration>
内的内容
切换文件目录
cd /usr/local/hadoop/etc/hadoop/
在 hadoop-env.sh 中更改 JAVA_HOME
sudo vim hadoop-env.sh
注释掉
export JAVA_HOME=${JAVA_HOME}
添加
export JAVA_HOME=/usr/local/java
core-site.xml
sudo vim core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://0.0.0.0:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
hdfs-site.xml
sudo vim hdfs-site.xml
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
测试,启动
格式化namenode
hadoop namenode -format
启动hdfs
start-all.sh
查看相应的进程
jps
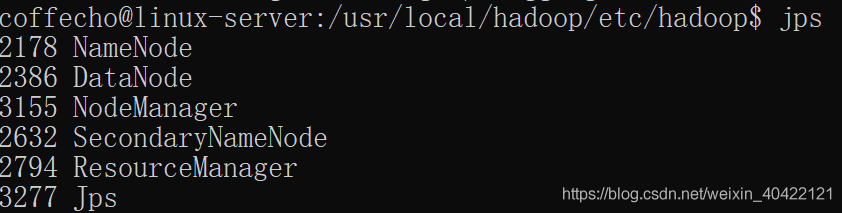
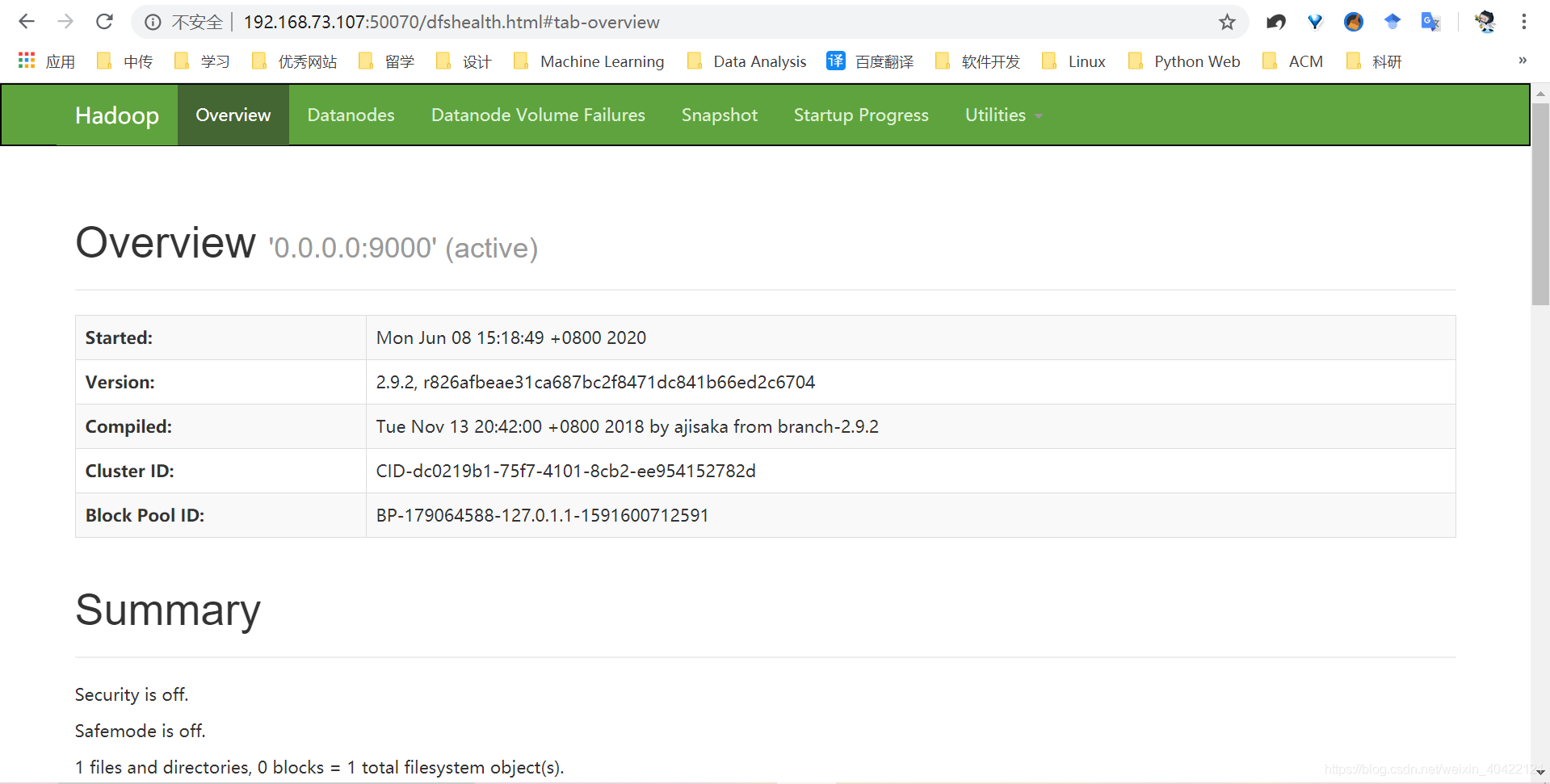
访问测试
192.168.73.107:50070
安装配置Hbase
安装Hbase
解压与重命名
tar -vxzf hbase-1.4.13-bin.tar.gz
mv hbase-1.4.13 hbase
移动文件夹
sudo cp -r hbase /usr/local
设置环境变量
sudo vim /etc/profile
export HBASE_HOME=/usr/local/hbase
export HBASE_CONF_DIR=$HBASE_HOME/conf
export HBASE_CLASS_PATH=$HBASE_CONF_DIR
export PATH=$PATH:$HBASE_HOME/bin
重载
source /etc/profile
检测安装版本
hbase version

修改配置文件
xml修改的部分均为
<configuration>
</configuration>
内的内容
进入文件目录
cd /usr/local/hbase/conf
hbase-env.sh中更改JAVA_HOME
sudo vim hbase-env.sh
添加
export JAVA_HOME=/usr/local/java
export HBASE_MANAGES_ZK=false
修改hbase-site.xml
sudo vim hbase-site.xml
修改
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///usr/local/hbase/hbase-tmp</value>
</property>
</configuration>
启动Hbase
start-hbase.sh
查看运行情况
jps
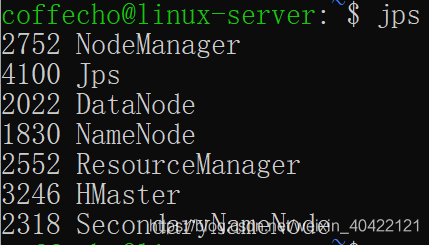
HMaster一定要有
简单使用Hbase
进入交互界面
hbase shell
进行一些基本数据库操作
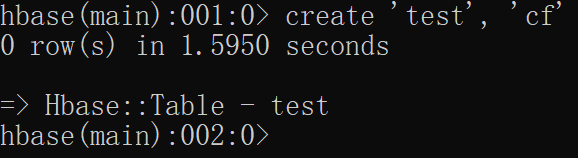
创建表
使用create命令创建一个新表.你必须规定表名和列族名
create 'test', 'cf'
显示表信息
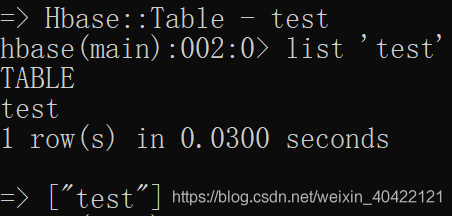
使用list 命令可以显示表信息
list 'test'
使用 describe 命令显示表的详细信息
describe 'test'

向表中加入数据
使用 put 命令
put 'test', 'row1', 'cf:a', 'value1'
put 'test', 'row2', 'cf:b', 'value2'
put 'test', 'row3', 'cf:c', 'value3'
扫描表
使用scan 命令扫描整个表取得数据
scan 'test'

取一行数据
使用get指令
get 'test', 'row1'

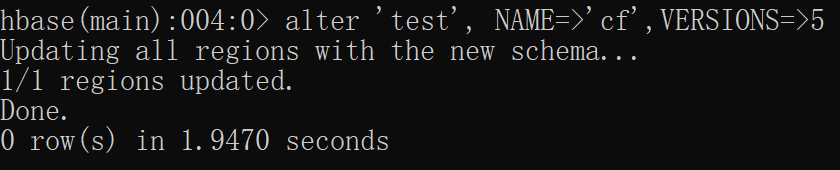
修改表模式
使用alter命令,如修改存储版本数
disable 'test'
alter 'test', NAME=>'cf',VERSIONS=>5
enable 'test'
其他命令
disable table, drop table,enable table 等
思考题
- 请问伪分布和分布式的含义有何不同?就本实验,你是如何理解在一台计算机上做到“伪分布”的?
利用0.0.0.0(本机所有IP地址)为一个节点,制造出“伪分布”
- 在1.2小节进行安装SSH并设置SSH无密码登陆,请问这个安装的目的是什么?
用本地账户进行远程登陆,实现“伪分布”的效果
- 如果继续向Hbase的test表中put行键为”row1”,值为其它字符串的数据,put ‘test’ ,’row1’, ‘cf:a’, ‘value6’,会发生什么?如果采用语句get ‘test’, ‘row1’, {COLUMN=>‘cf:a’, VERSIONS=>3} 进行查询,分析你得到的结果。put与关系数据库的插入有何不同?
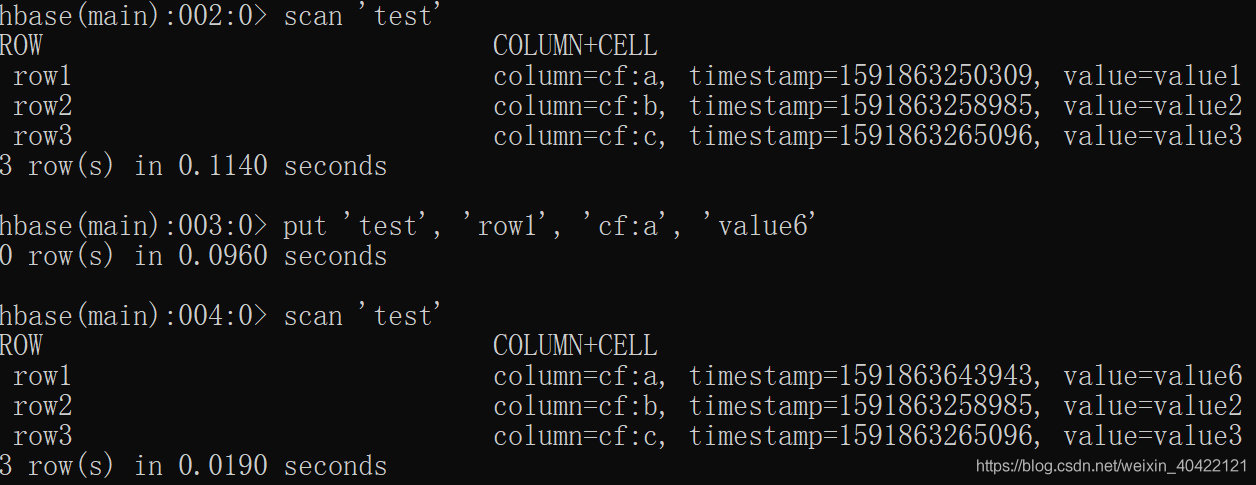
新值会被覆盖

会保留历史结果,查询的话显示最新覆盖内容
参考网址
Ubuntu 18.04 安装 Hadoop系统环境
cs