select
createtime,
month1,lag(irank,1,0) over(order by irank) as lag1,
month2,lag(irank,2,0) over(order by irank) as lag2,
month2,lag(irank,3,0) over(order by irank) as lag3,
month2,lag(irank,4,0) over(order by irank) as lag4,
month2,lag(irank,5,0) over(order by irank) as lag5
from
(select
createtime
,cast(split(viewstr,',')[0] as bigint) as month1
,cast(split(viewstr,',')[1] as bigint) as month2
,cast(split(viewstr,',')[2] as bigint) as month3
,cast(split(viewstr,',')[3] as bigint) as month4
,cast(split(viewstr,',')[4] as bigint) as month5
,ROW_NUMBER() OVER(ORDER BY createtime) AS irank
from
(select
createtime
,wm_concat(cast(avg_view as string),',') as viewstr
from tablename
group by createtime
) tmp
) tmp1
上述sql结果如图:

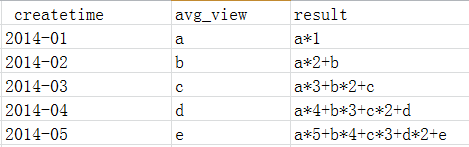
再将sql内的monthN*legN再横向累加即可
- 总结:这种思路可以实现但是缺点显而易见,太麻烦了。后来看到同事的数据有88个月,我裂开!要写多少行啊。放弃!
归结上述思路,发现繁琐的步骤就再横向拉平那块,88个月split要写88个,上面的leg又是88个。hive中对于这种繁琐的操作应该是有内置函数的。之前有写过内置函数的总结篇。HIVE窗口函数合集,发现果然有。
利用开窗函数的window子句其中的累加到当前行。只需要使用两次即可:
SELECT
createtime,avg_view,sample1,
sum(sample1) over(order by createtime rows between UNBOUNDED PRECEDING and CURRENT ROW ) as sample2
FROM
(select
createtime,avg_view,
sum(avg_view) over(order by createtime rows between UNBOUNDED PRECEDING and CURRENT ROW ) as sample1
from tablename
group by createtime,avg_view
) t
group by createtime,avg_view,sample1;
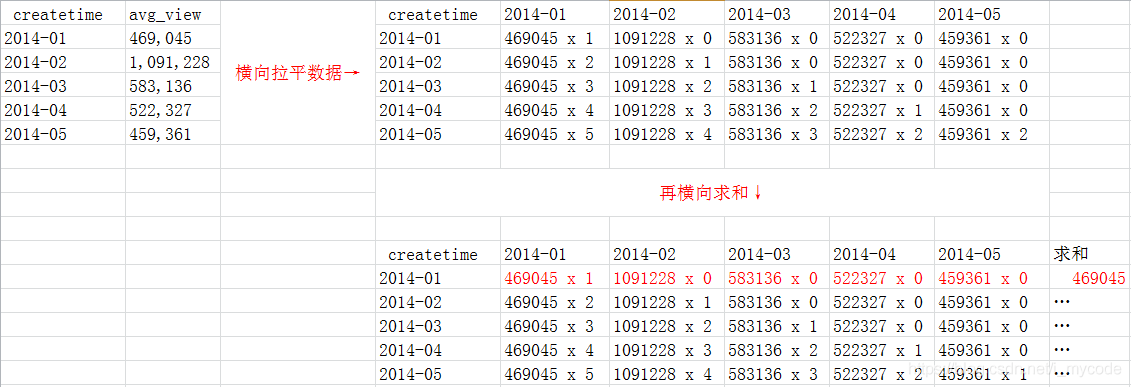
第一次使用得到第一行累加到当前行的统计值sample1。再次将sample1累加一次第一行到当前行即得到最终结果。如下图所示:

总结:同事使用excel完成的思路也是这样,累加两次。excel真香!
cs