һ��tensorboard�ļ�Ҫ����
TensorBoard��һ�������İ�������pytorch�еģ�������������þ��ǿ��ӻ���ģ���еĸ��ֲ����ͽ����
�����ǰ�װ��
��װ TensorBoard ����Щʵ�ó���ʹ�����Խ� PyTorch ģ�ͺ�ָ���¼��Ŀ¼�У��Ա��� TensorBoard UI �н��п��ӻ��� PyTorch ģ�ͺ������Լ� Caffe2 ����� Blob ��֧�ֱ�����ͼ��ֱ��ͼ��ͼ�κ�Ƕ����ӻ���
SummaryWriter ������������¼�����Թ� TensorBoard ʹ�úͿ��ӻ�����Ҫ��ڡ�
��һ�����ӣ�����������У����ص��ע�����е�ע�Ͳ��֣�
import torch
import torchvision
from torchvision import datasets, transforms
# ���ӻ�����, SummaryWriter�����þ��ǣ����������ض��ĸ�ʽ�洢������õ����Ǹ���־�ļ�����
from torch.utils.tensorboard import SummaryWriter
# ��һ����ʵ��������ע����д·������Ĭ��д�뵽 ./runs/ Ŀ¼
writer = SummaryWriter()
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = datasets.MNIST('mnist_train', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
model = torchvision.models.resnet50(False)
# �� ResNet ģ�Ͳ��ûҶȶ����� RGB
model.conv1 = torch.nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
images, labels = next(iter(trainloader))
grid = torchvision.utils.make_grid(images)
# �ڶ��������ö���ķ��������ļ��д�����
writer.add_image('images', grid, 0)
writer.add_graph(model, images)
writer.close()
�������֮�����ǾͿ������ļ����¿������DZ���������ˣ�Ȼ�����ǾͿ���ʹ�� TensorBoard ������п��ӻ����� TensorBoard Ӧ�ÿ�ͨ�����·�ʽ���У��������У���
tensorboard --logdir=runs
������

�������ĵ�ַ��ճ����������Ϳ��Կ������ӻ��Ľ���ˣ�������ʾ��
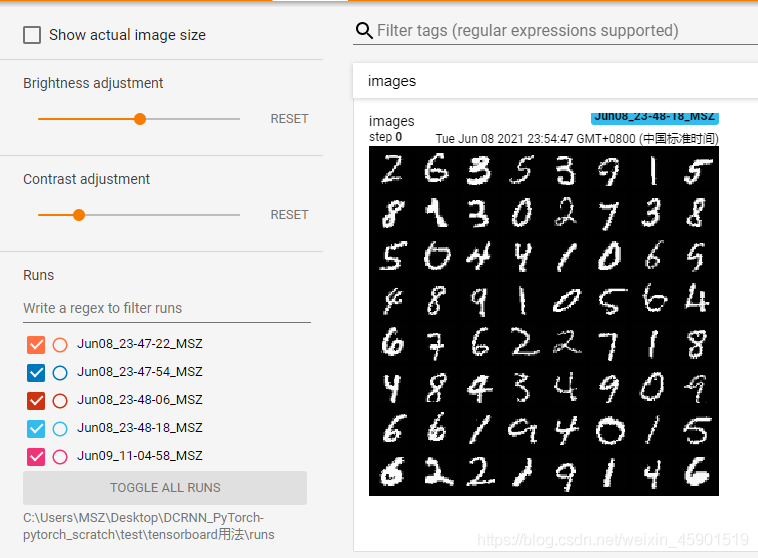
���ſ���
һ��ʵ����Լ�¼�ܶ���Ϣ�� Ϊ�˱��� UI ���Һ��õؽ�������࣬���ǿ���ͨ����ͼ���зֲ���������ͼ���з����� ���磬����ʧ/ѵ�����͡���ʧ/���ԡ�����������һ�𣬶���ȷ��/ѵ�����͡�ȷ��/���ԡ����� TensorBoard �����зֱ���顣
�����ٿ�һ��������������������Ļ���
from torch.utils.tensorboard import SummaryWriter
import numpy as np
# ��һ����ʵ��������ע����д����Ĭ���� ./run/ �ļ�����
writer = SummaryWriter()
for n_iter in range(100):
# �ڶ��������ö���ķ��������ļ��д�����
writer.add_scalar('Loss/train', np.random.random(), n_iter)
writer.add_scalar('Loss/test', np.random.random(), n_iter)
writer.add_scalar('Accuracy/train', np.random.random(), n_iter)
writer.add_scalar('Accuracy/test', np.random.random(), n_iter)
writer.close()
�������(��������)��
������������tensorboard --logdir=run��run�DZ�������ݵ�����·����
ʵ������
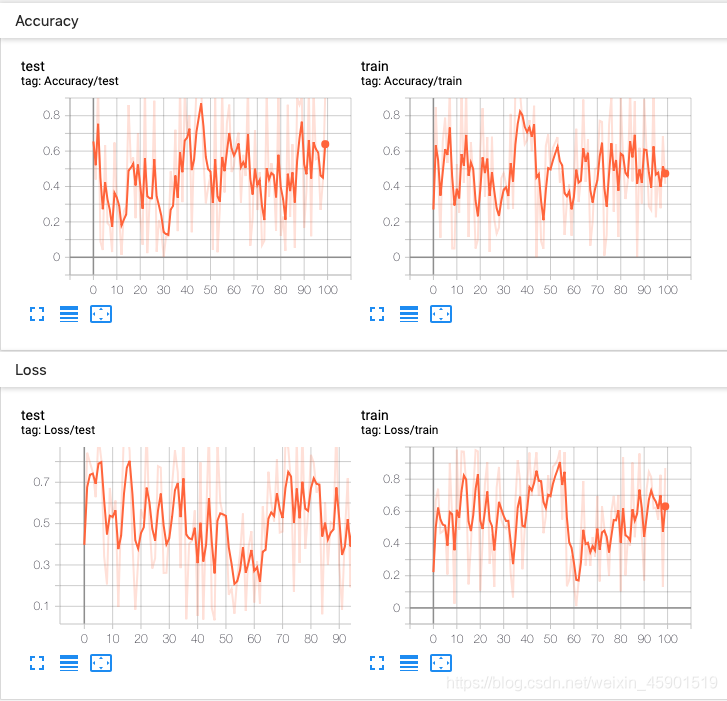
���ˣ��������tensorboard���˳�������ʶ��Ҳ֪������ô��pytorch�� ����ģ�������й����е�һЩ����������֪������ô��tensorboard������������
���ǣ����ǻ�û��ϸ��ǰ���ᵽ�ļ�����������˽��������ǿ��⼸�������ľ���ʹ�á�
����torch.utils.tensorboard�漰�ļ�������
2.1 SummaryWriter()��
API��
class torch.utils.tensorboard.writer.SummaryWriter(log_dir=None, comment='',
purge_step=None, max_queue=10, flush_secs=120, filename_suffix='')
���ã������ݱ��浽 log_dir �ļ����� �Թ� TensorBoard ʹ�á�
SummaryWriter ���ṩ��һ���� API�������ڸ���Ŀ¼�д����¼��ļ�������������ժҪ���¼��� �����첽�����ļ����ݡ� ������ѵ�������ѵ��ѭ���е���ֱ�ӽ��������ӵ��ļ��ķ��������������ѵ���ٶȡ�
������SummaryWriter()��Ĺ��캯����
def __init__(log_dir=None, comment='', purge_step=None, max_queue=10, flush_secs=120,
filename_suffix='')
���ã�����һ�� SummaryWriter ���������¼���ժҪд���¼��ļ��С�
����˵����
log_dir (�ַ�����������Ŀ¼λ���� Ĭ��ֵΪ run/CURRENT_DATETIME_HOSTNAME ��ÿ�����к���ġ� ʹ�÷ֲ��ļ��нṹ�������ɱȽ���������� ���� Ϊÿ����ʵ�鴫�ݡ� runs / exp1������ runs / exp2���ȣ��Ա�������֮����бȽϡ�comment(�ַ�������ע�� log_dir �����ӵ�Ĭ��ֵlog_dir�� ���������log_dir����˲�����Ч��purge_step (python��int )������־��¼�ڲ��� T + X T+X T+X �������ڲ��� T T T ��������ʱ������� global_step ���ڻ���ڵ������¼��� ������ TensorBoard ���� ��ע�⣬������ʵ��ͻָ���ʵ��Ӧ������ͬ��log_dir��max_queue (python��int )���ڡ����ӡ�����֮һǿ��ˢ�µ�����֮ǰ��δ���¼���ժҪ�Ķ��д�С�� Ĭ��ֵΪʮ����Ŀ��flush_secs (python��int )����������¼���ժҪˢ�µ����̵�Ƶ��(����Ϊ��λ���� Ĭ��ֵΪÿ������һ�Ρ�filename_suffix (�ַ������������ӵ� log_dir Ŀ¼�е������¼��ļ������� �� tensorboard.summary.writer.event_file_writer.EventFileWriter ���й��ļ�������ĸ�����ϸ��Ϣ��
���ӣ�
from torch.utils.tensorboard import SummaryWriter
# ʹ���Զ����ɵ��ļ������ƴ���summary writer
writer = SummaryWriter()
# folder location: runs/May04_22-14-54_s-MacBook-Pro.local/
# ʹ��ָ�����ļ������ƴ���summary writer
writer = SummaryWriter("my_experiment")
# folder location: my_experiment
# ����һ������ע�͵� summary writer
writer = SummaryWriter(comment="LR_0.1_BATCH_16")
# folder location: runs/May04_22-14-54_s-MacBook-Pro.localLR_0.1_BATCH_16/
2.2 add_scalar()����
API��
add_scalar(tag, scalar_value, global_step=None, walltime=None)
���ã��������������ӵ�summary
����˵����
tag (string) �� ���ݱ�ʶ��scalar_value (float or string/blobname) �� Ҫ�����ֵglobal_step (int) ��Ҫ��¼��ȫ�ֲ���ֵ������� x����walltime (float)����ѡ�����¼����������������Ĭ�ϵ� walltime(time.time(����
���ӣ�
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
x = range(100)
for i in x:
writer.add_scalar('y_2x', i * 2, i)
writer.close()
�����
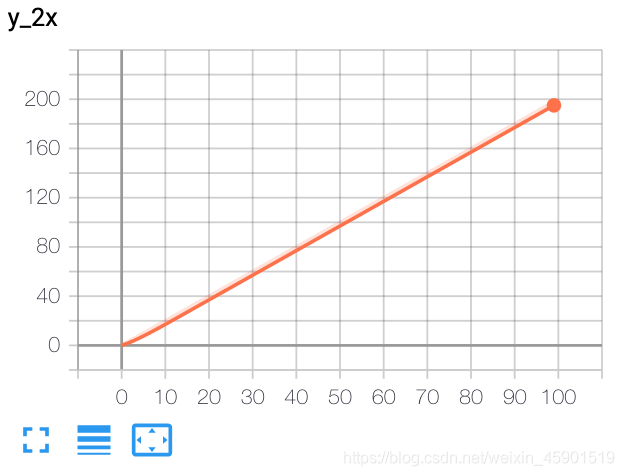
2.3 add_scalars()����
API��
add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None)
���ã�����������������ӵ� summary �С�
����˵����
main_tag (string) ����ǵĸ�����tag_scalar_dict (dict) ���洢��ǩ�Ͷ�Ӧֵ�ļ�ֵ��global_step (int) ��Ҫ��¼��ȫ�ֲ���ֵwalltime (float) ����ѡ�����Ĭ��ʱ�� Walltime(time.time(������
���ӣ�
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
r = 5
for i in range(100):
writer.add_scalars('run_14h', {'xsinx':i*np.sin(i/r),
'xcosx':i*np.cos(i/r),
'tanx': np.tan(i/r)}, i)
writer.close()
# �˵��ý�����ֵ���ӵ����б�ǵ�ͬһ������ͼ��
# 'run_14h' �� TensorBoard �ı�������
�����
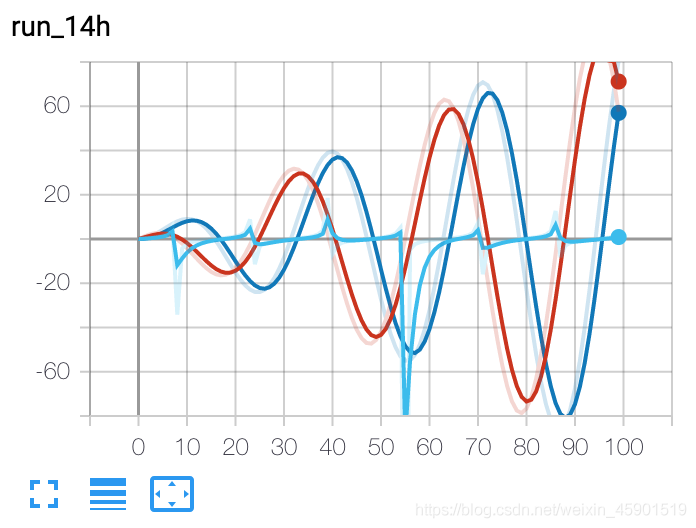
2.4 add_histogram()
add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)
���ã���ֱ��ͼ���ӵ� summary �С�
����˵����
tag (string)�� ���ݱ�ʶ��values (torch.Tensor, numpy.array, or string/blobname) ������ֱ��ͼ��ֵglobal_step (int) ��Ҫ��¼��ȫ�ֲ���ֵbins (string) �� One of {��tensorflow','auto', ��fd', ��}. ��������������������ʽ��������������λ���ҵ�����ѡ�https://docs.scipy.org/doc/numpy/reference/generated/numpy.histogram.htmlwalltime (float) �C Optional override default walltime (time.time()) seconds after epoch of event
���ӣ�
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter()
for i in range(10):
x = np.random.random(1000)
writer.add_histogram('distribution centers', x + i, i)
writer.close()
�����
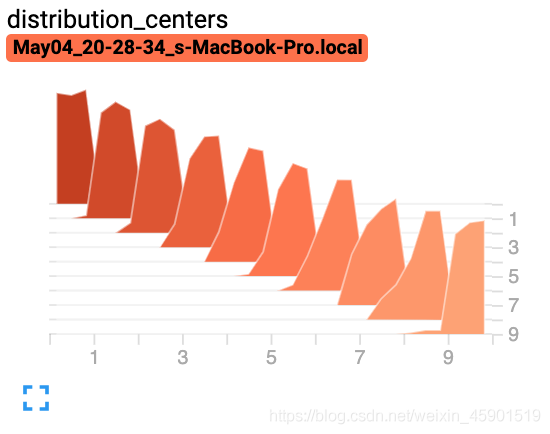
���õ����������Щ�����ڸ���ĺ���˵�� ����������鿴��https://pytorch.org/docs/stable/tensorboard.html#torch-utils-tensorboard
jsjbwy