�������������һ�����ӵ���ṹ����������������Ӧ�ý�����������Ȼ���������˺ܶ���������壬�����Ƕ�������˽����Ѹ�ٵط�����Щ���塣��һ���Һ�ϲ�������ӣ�

��ȷ�Ľ��������ӡ�with���͡�pizza����������Ľ�������with���͡�eat����ϵ����һ��
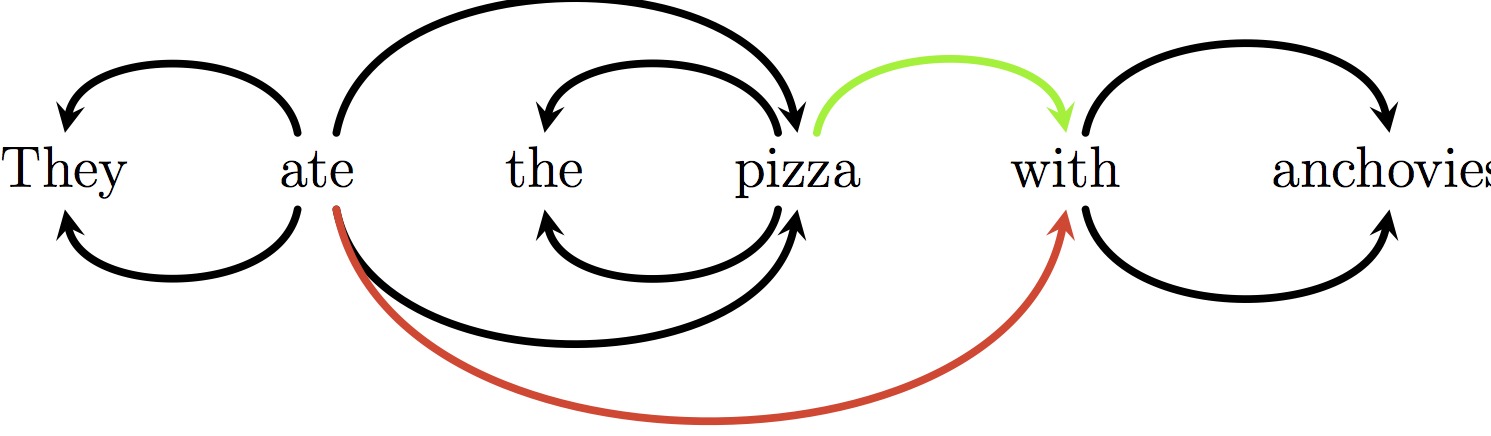
��ȥ��һЩ�꣬��Ȼ���Դ�����NLP�����������������ȡ���˺ܴ�Ľ�չ�����ڣ�СС�� Python ʵ�ֿ��ܱȹ㷺Ӧ�õ� Stanford ���������ֵø���ɫ��
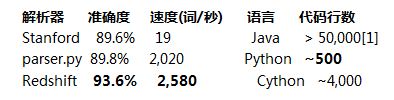
����ʣ�µIJ����������������⣬���Ŵ����˽�Ϊ�����ļ��ʵ�֡�parser.py �����е�ǰ 200 �������˴��Եı�ע�ߺ�ѧϰ�ߣ������������dz���Ϥ NLP ������о����������о���ƪ����֮ǰ����Ӧ���Զ���
Cython ϵͳ�� Redshift ��Ϊ��Ŀǰ���о���д�ġ��������ѧ�ĺ�ͬ���ں��Ҽƻ����·ݶ������иĽ�������һ����;��Ŀǰ�İ汾�й��� GitHub �ϡ�
��������
������ֻ�����������һ��ָ���Ƿdz����Ƶģ�
Set volume to zero when I'm in a meeting, unless John's school calls.
���Ž����ʵ��IJ������á��� Android ϵͳ�ϣ������Ӧ�� Tasker �����������飬�� NL �ӿڻ����һЩ�����տ��Ա༭�������ʾ��������˽����Ϊ��������˼�����ҿ������������뷨���������ر����Ƶġ�
������кܶ�������Ҫ�������һЩ����ľ䷨��̬�����DZ�Ҫ�ġ�������Ҫ֪����
Unless John's school calls, when I'm in a meeting, set volume to zero
�ǽ���ָ�����һ�ַ�ʽ����
Unless John's school, call when I'm in a meeting
��������ȫ��ͬ����˼��
��������������һ�������뵥�ʼ�Ĺ�ϵͼ��ʹ������ø����ס���ϵͼ�����νṹ������ߣ�ÿ���ڵ㣨���ʣ����ҽ���һ���뻡��ͷ����������
�÷�ʾ����
>>> parser = parser.Parser()
>>> tokens = "Set the volume to zero when I 'm in a meeting unless John 's school calls".split()
>>> tags, heads = parser.parse(tokens)
>>> heads
[-1, 2, 0, 0, 3, 0, 7, 5, 7, 10, 8, 0, 13, 15, 15, 11]
>>> for i, h in enumerate(heads):
... head = tokens[heads[h]] if h >= 1 else 'None'
... print(tokens[i] + ' <-- ' + head])
Set <-- None
the <-- volume
volume <-- Set
to <-- Set
zero <-- to
when <-- Set
I <-- 'm
'm <-- when
in <-- 'm
a <-- meeting
meeting <-- in
unless <-- Set
John <-- 's
's <-- calls
school <-- calls
calls <-- unless
һ�ֹ۵���ͨ������������Ƶ����ַ���Ӧ����������һЩ���������ӳ����������������ӳ�����
����������������������ȷ�����ɹ�������ע��ָ�Ͼ����ġ������û���Ķ�ָ�ϲ��Ҳ���һ������ѧ�ң��Ͳ����жϽ����Ƿ���ȷ����ʹ���������Ե���ֺ���١�
���磬������Ľ����д���һ�������� Stanford ��ע��ָ�Ϲ涨����John's school calls�� ���ڽṹ���������ⲿ�ֵĽṹ��ָ��ע������ν���һ�������ڡ�John's school clothes�������ӡ�
��һ��ֵ�����뿼�ǡ������Ͻ��������Ѿ��ƶ��������ԡ���ȷ���Ľ���Ӧ���෴���������Υ��Լ�����г�ֵ��������Ž���������ø������ѣ���Ϊ�����������>����һ���Իή�͡���2���������ǿ��Բ��Ծ��飬�������Ǻܸ���ͨ����ת���Ի�����ơ�
����ȷʵ��Ҫ�����еIJ��졪�����Dz�ϣ��������ͬ�Ľṹ����������������á�ע��ָ������Щ����ʹ����Ӧ����Ч����Щ��������������Ԥ��֮��ȡ��ƽ�⡣
ӳ����
�ھ�������ʲô���ӵĹ�ϵͼʱ�����ǿ��Խ���һ���ر���Ч�ļ��Խ�Ҫ�����Ĺ�ϵͼ�ṹ�������ơ�����������ѧ�Է��������ƣ��ڼ����㷨���ⷽ��Ҳ�����á��ֵ�>Ӣ�Ľ��������У�������ѭԼ����������ϵͼ����ӳ������
�������˸��⣬ÿ�����ʶ���һ����ͷ��
ӳ���ϵ�����ÿ��������ϵ ��a1, a2���� ��b1, b2������� a1 < b2, ��ô a2 >= b2�����仰˵��������ϵ���ܽ��档�����ܴ���һ�� a1 b1 a2 b2 ���� b1 a1 b2 a2 ��ʽ��������ϵ��
�ڽ�����ӳ���������зḻ�����ף�����������ͼ�����������Զ�����һЩ���ҽ�Ҫ�����Ľ����㷨����ӳ��������
̰���Ļ���ת���Ľ���
���ǵ�����������ַ��������б���Ϊ���룬���������ϵͼ�бߵĻ�ͷ�����б�������� i ����ͷԪ���� j, ������ϵ����һ���� ��j, i��������ת�����������>������״̬ת���������� N �����ʵ�����ӳ�䵽 N ����ͷ������������顣
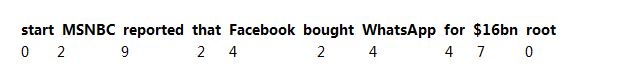
��ͷ�����ʾ�� MSNBC �Ļ�ͷ��MSNBC �ĵ���������1��reported �ĵ���������2�� head[1] == 2����Ӧ���Ѿ�����Ϊʲô���νṹ��˷��㡪������������һ�� DAG �ṹ�����ֽṹ�еĵ��ʿ��ܰ��������ͷ�����νṹ�����ٹ�����
��Ȼ heads ���Ա�ʾΪһ�����飬����ȷʵϲ������һ���������ʽ�����ʽ������Է����Ч����ȡ������Parse �����������
class Parse(object):
def __init__(self, n):
self.n = n
self.heads = [None] * (n-1)
self.lefts = []
self.rights = []
for i in range(n+1):
self.lefts.append(DefaultList(0))
self.rights.append(DefaultList(0))
def add_arc(self, head, child):
self.heads[child] = head
if child < head:
self.lefts[head].append(child)
else:
self.rights[head].append(child)
�������һ��������Ҳ��Ҫ���پ����е�λ�á�����ͨ���� words ����������һ������������ջ����ʵ�֣�ջ�п���ѹ�뵥�ʣ����õ��ʵĻ�ͷʱ���������ʡ��������ǵ�״̬���ݽṹ�ǻ�����
- һ������ i, ��ڷ����б���
- ������Ϊֹ��������еļ����������ϵ
- һ���������� i ֮ǰ�����ĵ��ʵ�ջ��������Ϊ��Щ���������˻�ͷ��
�������̵�ÿһ����Ӧ�������ֲ���֮һ��
SHIFT = 0; RIGHT = 1; LEFT = 2
MOVES = [SHIFT, RIGHT, LEFT]
def transition(move, i, stack, parse):
global SHIFT, RIGHT, LEFT
if move == SHIFT:
stack.append(i)
return i + 1
elif move == RIGHT:
parse.add_arc(stack[-2], stack.pop())
return i
elif move == LEFT:
parse.add_arc(i, stack.pop())
return i
raise GrammarError("Unknown move: %d" % move)
LEFT �� RIGHT ��������������ϵ����ջ���� SHIFT ѹջ�����ӻ����� i ֵ��
��ˣ����������һ����ջ��ʼ����������Ϊ0��û��������ϵ��¼��ѡ��һ����Ч�IJ�����Ӧ�õ���ǰ״̬������ѡ�������Ӧ��ֱ��ջΪ���һ���������������������յ㡣��û�������Ǻ������������㷨�ġ�������һ�����ӣ�����ӳ�������������ͨ��ѡ����ȷ��ת�����б��������������
�����Ǵ����еĽ���ѭ����
class Parser(object):
...
def parse(self, words):
tags = self.tagger(words)
n = len(words)
idx = 1
stack = [0]
deps = Parse(n)
while stack or idx < n:
features = extract_features(words, tags, idx, n, stack, deps)
scores = self.model.score(features)
valid_moves = get_valid_moves(i, n, len(stack))
next_move = max(valid_moves, key=lambda move: scores[move])
idx = transition(next_move, idx, stack, parse)
return tags, parse
def get_valid_moves(i, n, stack_depth):
moves = []
if i < n:
moves.append(SHIFT)
if stack_depth >= 2:
moves.append(RIGHT)
if stack_depth >= 1:
moves.append(LEFT)
return moves
�����Ա�ǵľ��ӿ�ʼ������״̬��ʼ����Ȼ��״̬ӳ�䵽һ����������ģ�����ֵ��������ϡ�����Ѱ�ҵ÷���ߵ���Ч������Ӧ�õ�״̬�С�
���������ģ�ͺʹ��Ա�ע�е�һ���������������ȡ������ʹ������ģ�����ֵĹ۵�е�������Ӧ�ø�ϰ��ƪ���¡�����������ģ����ι�������ʾ��
class Perceptron(object)
...
def score(self, features):
all_weights = self.weights
scores = dict((clas, 0) for clas in self.classes)
for feat, value in features.items():
if value == 0:
continue
if feat not in all_weights:
continue
weights = all_weights[feat]
for clas, weight in weights.items():
scores[clas] += value * weight
return scores
���������ÿ����������Ȩ����͡���ͨ������ʾΪһ�������Ȼ���ҷ��ִ����ܶ���ʱ�Ͳ�̫�ʺ��ˡ�
�����������RedShift�����������ѡԪ�أ�������ֻ��ѡ����õ�һ�������ǽ���עЧ�ʺͼ���������ȷ�ԡ�����ֻ�����˵�һ�ķ��������ǵ��������Խ�����ȫ̰���ģ�������Ա��һ�������ǽ�������ѡ���ÿһ����
��������Ķ��˴��Ա�ǣ�����ܻᷢ������������ԡ������������ǽ���������ӳ�䵽һ��ʹ�á���ƽ������������б�����⣬���߷ǽṹ����ѧϰ�㷨��ͨ��̰����������
������
������ȡ�������Ǻܳ�ª���������������ָ�����������е�һЩ��ʶ��
- �����е�ǰ�������� ��n0, n1, n2��
- ��ջ�е�ջ������������ ��s0, s1, s2��
- s0 ����ߵ��������� (s0b1, s0b2);
- s0 ���ұߵ��������� (s0f1, s0f2);
- n0 ����ߵ��������� (n0b1, n0b2);
����ָ��������12����ʶ�ĵ��ʱ������Ա�ע���ͱ�ʶ���������Һ�����Ŀ��
��Ϊʹ�õ�������ģ�ͣ�����ָ����ԭ��������ɵ���Ԫ�顣
def extract_features(words, tags, n0, n, stack, parse):
def get_stack_context(depth, stack, data):
if depth >;= 3:
return data[stack[-1]], data[stack[-2]], data[stack[-3]]
elif depth >= 2:
return data[stack[-1]], data[stack[-2]], ''
elif depth == 1:
return data[stack[-1]], '', ''
else:
return '', '', ''
def get_buffer_context(i, n, data):
if i + 1 >= n:
return data[i], '', ''
elif i + 2 >= n:
return data[i], data[i + 1], ''
else:
return data[i], data[i + 1], data[i + 2]
def get_parse_context(word, deps, data):
if word == -1:
return 0, '', ''
deps = deps[word]
valency = len(deps)
if not valency:
return 0, '', ''
elif valency == 1:
return 1, data[deps[-1]], ''
else:
return valency, data[deps[-1]], data[deps[-2]]
features = {}
# Set up the context pieces --- the word, W, and tag, T, of:
# S0-2: Top three words on the stack
# N0-2: First three words of the buffer
# n0b1, n0b2: Two leftmost children of the first word of the buffer
# s0b1, s0b2: Two leftmost children of the top word of the stack
# s0f1, s0f2: Two rightmost children of the top word of the stack
depth = len(stack)
s0 = stack[-1] if depth else -1
Ws0, Ws1, Ws2 = get_stack_context(depth, stack, words)
Ts0, Ts1, Ts2 = get_stack_context(depth, stack, tags)
Wn0, Wn1, Wn2 = get_buffer_context(n0, n, words)
Tn0, Tn1, Tn2 = get_buffer_context(n0, n, tags)
Vn0b, Wn0b1, Wn0b2 = get_parse_context(n0, parse.lefts, words)
Vn0b, Tn0b1, Tn0b2 = get_parse_context(n0, parse.lefts, tags)
Vn0f, Wn0f1, Wn0f2 = get_parse_context(n0, parse.rights, words)
_, Tn0f1, Tn0f2 = get_parse_context(n0, parse.rights, tags)
Vs0b, Ws0b1, Ws0b2 = get_parse_context(s0, parse.lefts, words)
_, Ts0b1, Ts0b2 = get_parse_context(s0, parse.lefts, tags)
Vs0f, Ws0f1, Ws0f2 = get_parse_context(s0, parse.rights, words)
_, Ts0f1, Ts0f2 = get_parse_context(s0, parse.rights, tags)
# Cap numeric features at 5?
# String-distance
Ds0n0 = min((n0 - s0, 5)) if s0 != 0 else 0
features['bias'] = 1
# Add word and tag unigrams
for w in (Wn0, Wn1, Wn2, Ws0, Ws1, Ws2, Wn0b1, Wn0b2, Ws0b1, Ws0b2, Ws0f1, Ws0f2):
if w:
features['w=%s' % w] = 1
for t in (Tn0, Tn1, Tn2, Ts0, Ts1, Ts2, Tn0b1, Tn0b2, Ts0b1, Ts0b2, Ts0f1, Ts0f2):
if t:
features['t=%s' % t] = 1
# Add word/tag pairs
for i, (w, t) in enumerate(((Wn0, Tn0), (Wn1, Tn1), (Wn2, Tn2), (Ws0, Ts0))):
if w or t:
features['%d w=%s, t=%s' % (i, w, t)] = 1
# Add some bigrams
features['s0w=%s, n0w=%s' % (Ws0, Wn0)] = 1
features['wn0tn0-ws0 %s/%s %s' % (Wn0, Tn0, Ws0)] = 1
features['wn0tn0-ts0 %s/%s %s' % (Wn0, Tn0, Ts0)] = 1
features['ws0ts0-wn0 %s/%s %s' % (Ws0, Ts0, Wn0)] = 1
features['ws0-ts0 tn0 %s/%s %s' % (Ws0, Ts0, Tn0)] = 1
features['wt-wt %s/%s %s/%s' % (Ws0, Ts0, Wn0, Tn0)] = 1
features['tt s0=%s n0=%s' % (Ts0, Tn0)] = 1
features['tt n0=%s n1=%s' % (Tn0, Tn1)] = 1
# Add some tag trigrams
trigrams = ((Tn0, Tn1, Tn2), (Ts0, Tn0, Tn1), (Ts0, Ts1, Tn0),
(Ts0, Ts0f1, Tn0), (Ts0, Ts0f1, Tn0), (Ts0, Tn0, Tn0b1),
(Ts0, Ts0b1, Ts0b2), (Ts0, Ts0f1, Ts0f2), (Tn0, Tn0b1, Tn0b2),
(Ts0, Ts1, Ts1))
for i, (t1, t2, t3) in enumerate(trigrams):
if t1 or t2 or t3:
features['ttt-%d %s %s %s' % (i, t1, t2, t3)] = 1
# Add some valency and distance features
vw = ((Ws0, Vs0f), (Ws0, Vs0b), (Wn0, Vn0b))
vt = ((Ts0, Vs0f), (Ts0, Vs0b), (Tn0, Vn0b))
d = ((Ws0, Ds0n0), (Wn0, Ds0n0), (Ts0, Ds0n0), (Tn0, Ds0n0),
('t' + Tn0+Ts0, Ds0n0), ('w' + Wn0+Ws0, Ds0n0))
for i, (w_t, v_d) in enumerate(vw + vt + d):
if w_t or v_d:
features['val/d-%d %s %d' % (i, w_t, v_d)] = 1
return features
ѵ��
ѧϰȨ�غʹ��Ա�עʹ������ͬ���㷨����ƽ����֪���㷨��������Ҫ�����ǣ�����һ������ѧϰ�㷨������һ����һ�����룬���ǽ���Ԥ�⣬�����ʵ�𰸣����Ԥ���������������Ȩ�أ���
ѭ��ѵ���������������ģ�
class Parser(object):
...
def train_one(self, itn, words, gold_tags, gold_heads):
n = len(words)
i = 2; stack = [1]; parse = Parse(n)
tags = self.tagger.tag(words)
while stack or (i + 1) < n:
features = extract_features(words, tags, i, n, stack, parse)
scores = self.model.score(features)
valid_moves = get_valid_moves(i, n, len(stack))
guess = max(valid_moves, key=lambda move: scores[move])
gold_moves = get_gold_moves(i, n, stack, parse.heads, gold_heads)
best = max(gold_moves, key=lambda move: scores[move])
self.model.update(best, guess, features)
i = transition(guess, i, stack, parse)
# Return number correct
return len([i for i in range(n-1) if parse.heads[i] == gold_heads[i]])
ѵ������������Ȥ�IJ����� get_gold_moves�� ͨ��Goldbery �� Nivre ��2012�������ǵ�������������ܿ��ܻ�����������������ָ�����Ǵ��˺ܶ��ꡣ
�ڴ��Ա�ע�����У������Ѵ�ң���ѵ���ڼ䣬��Ҫȷ�����ݵ����������Ԥ������Ϊ��ǰ��ǵ���������������������ƽ��ǡ������ڼ�ֻ��Ԥ���ǣ���������ǻ���ѵ�������лƽ����еģ�ѵ�������Ͳ���Ͳ��Ի�������һ�£���˽���õ������Ȩ�ء�
����������������ٵ������Dz�֪����δ���Ԥ�����У�ͨ�����ûƽ�����ṹ�������ֿ���ת��Ϊ���Ĺ������У��ȵȣ�ʹ��ѵ�����Թ��������÷��صĶ������У���ִ֤���˶������õ��ƽ����������ϵ��
�����ǣ����������������κ�û�����Żƽ�����е�״̬ʱ�����Dz�֪����ν��������ġ���ȷ���˶���һ��������������˴������Dz�֪����δ�ʵ����ѵ����
����һ�������⣬��Ϊ����ζ��һ�����������ʼ������������ֹͣ�ڲ�����ѵ�����ݵ��κ�һ��״̬�������³��ָ���Ĵ���
����̰�����������ԣ������Ǿ���ģ�һ��ʹ�÷������ԣ���һ����Ȼ�ķ�ʽ���ṹ��Ԥ�⡣
�����е����ͻ��һ����һ������������Щ����������ƺ����Զ����ġ�����Ҫ���ľ��Ƕ���һ���������˺������ʡ��ж��ٻƽ��������ϵ���Դ�����״̬�ָ���������ܶ��������������������ν���ÿ���˶����������ʣ����ж��ٻƽ��������ϵ���Դ�����״̬�ָ�������������õIJ�����������һЩ�Ļƽ������ʵ�֣���ô�����Ǵ��ŵġ�
������Ҫ���ܶණ����
���������� Oracle��state��:
Oracle(state) = | gold_arcs �� reachable_arcs(state) |
������һ���������ϣ�ÿ�ֲ�������һ����״̬��������Ҫ֪����
shift_cost = Oracle(state) �C Oracle(shift(state))
right_cost = Oracle(state) �C Oracle(right(state))
left_cost = Oracle(state) �C Oracle(left(state))
���ڣ�����һ�ֲ�������0��Oracle(state)���ʣ���ǰ�������·���ijɱ��Ƕ���?�����·���ĵ�һ����ת�ƣ����ң���������
��ʵ֤�������ǿ��Եó� Oracle ���˺ܶ����ϵͳ����������ʹ�õĹ���ϵͳ������Ʒ ���� Arc Hybrid �� Goldberg �� Nivre ��2013������ġ�
���ǰ�oracleʵ��Ϊһ������0-�ɱ����˶��ķ�����������ʵ��һ�����ܵ�Oracle(state)������Է�ֹ������һ�Ѱ���ĸ��Ʋ�����ϣ�������е���������̫�������⣬����е�����ϣ���ٸ��ʵĻ�������Բο� Goldberg �� Nivre �����ġ�
def get_gold_moves(n0, n, stack, heads, gold):
def deps_between(target, others, gold):
for word in others:
if gold[word] == target or gold[target] == word:
return True
return False
valid = get_valid_moves(n0, n, len(stack))
if not stack or (SHIFT in valid and gold[n0] == stack[-1]):
return [SHIFT]
if gold[stack[-1]] == n0:
return [LEFT]
costly = set([m for m in MOVES if m not in valid])
# If the word behind s0 is its gold head, Left is incorrect
if len(stack) >= 2 and gold[stack[-1]] == stack[-2]:
costly.add(LEFT)
# If there are any dependencies between n0 and the stack,
# pushing n0 will lose them.
if SHIFT not in costly and deps_between(n0, stack, gold):
costly.add(SHIFT)
# If there are any dependencies between s0 and the buffer, popping
# s0 will lose them.
if deps_between(stack[-1], range(n0+1, n-1), gold):
costly.add(LEFT)
costly.add(RIGHT)
return [m for m in MOVES if m not in costly]
���С���̬ oracle��ѵ�����̻�����ܴ�ľ��Ȳ��졪��ͨ��Ϊ1-2%��������ʱ�ķ�ʽû�����𡣾ɵġ���̬oracle��̰��ѵ�������Ѿ���ȫ��ʱ��û���κ������������ˡ�
�ܽ�
�Ҹо������Լ������ر�����Щ�������ر����ء��Ҳ�������ʲô���ij������ʵ�֡�
����Ϊ����������˵����õĽ�����������൱�����Ǻ���Ȼ�ġ�200,000 �е�Java���о�Ϊ�ˡ�
���ǣ�����ʵ��һ����һ�㷨ʱ���㷨���������̡ܶ�����ֻʵ��һ���㷨ʱ����д֮ǰ��ȷʵ֪��Ҫдʲô���㲻��Ҫ��ע�κβ���Ҫ�ľ��кܴ�����Ӱ��ij�����
ע��
[1] ����IJ�ȷ����μ���Stanford�������Ĵ�������������jar�ļ�װ����200k��С���ݣ�����������ͬ��ģ�͡��Ⲣ����Ҫ������50k�����ƺ��ǰ�ȫ�ġ�
[2]���磬��ν�����John's school of music calls��?����Ҫȷ�ϡ�John's school������͡�John's school calls������John's school of music calls������ͬ�Ľṹ���Կ��Է������IJ�ͬ�ġ���ۡ��������������������䷨�����Ĺؼ�;���������뵽ÿ������Ϊ���в�ͬ��״��������������Ҫ���벻ͬ�IJ�ۡ���ÿ������Ҳ��һ��������ͬ��״�IJ�ۡ���������ͼŪ���ʲô������������ʲô�ط�����˿��Ը�����������������һ��ġ�
[3]������ʹ���ˡ����ѧϰ�������� Stanford ���������°汾���˰汾ȷ�Ը��ߡ����ǣ�����ģ�͵�ȷ����������õ��ƽ���Լ���������档����һƪΰ������£����뷨��һ�����������ʵ�֣������������Dz������Ƚ���ʵ������Ҫ��
[4]һ��ϸ�ڣ�Stanford ������ϵʵ�����Ǹ����ƽ������ṹ���Զ����ɵġ��ο������Stanford����ת����ҳ�棺http://nlp.stanford.edu/software/stanford-dependencies.shtml��
���ݲ²�
�����������������Դ����㷨�ǿ�ѧ�����Ҫ��Ȥ���������Ҫ��дһ���������������������䴦������ι��������ۣ���ô�������������Ҫ�������ֽ������������г�ֵ�֤�ݣ�������ʶ�Է�˼�����������Dz���������룬˵������ɱ�������������
��������Ŀ�ѧ������ȣ���ǰ�㷨ʤ�����������ܸ��ߴ�ң�ʤ�����ؾ����ǣ�
���������ڵ���������������
����������ѵ������һ�����������µIJ������衣
��������䴦������ϵ���������ˡ����ڴ�������Щ���̵�ͻ���Ƿ����һЩ��������ѧ����Ľ�����
�ο���Ŀ
NLP ����������ȫ���š�����������Ķ������������ҵ���http://aclweb.org/anthology/��
���������Ľ������Ƕ�̬oracle arc-hybrid ϵͳ��ʵ�֣�
Goldberg, Yoav; Nivre, Joakim
Training Deterministic Parsers with Non-Deterministic Oracles
TACL 2013
Ȼ�����ұ�д���Լ���������arc-hybrid ϵͳ��������������
Kuhlmann, Marco; Gomez-Rodriguez, Carlos; Satta, Giorgio
Dynamic programming algorithms for transition-based dependency parsers
ACL 2011
������������˶�̬oracleѵ��������
A Dynamic Oracle for Arc-Eager Dependency Parsing
Goldberg, Yoav; Nivre, Joakim
COLING 2012
��Zhang �� Clark �о���������ʱ���������������ת��Ϊ�����Ľ�������ȷ���ϵ��ش�ͻ�ơ����Ƿ����˺ܶ����ģ�����ѡ�������ǣ�
Zhang, Yue; Clark, Steven
Syntactic Processing Using the Generalized Perceptron and Beam Search
Computational Linguistics 2011 (1)
����һƪ��Ҫ�������������ƪ�������������£���ƪ���½�һ�������ȷ�ԣ�
Zhang, Yue; Nivre, Joakim
Transition-based Dependency Parsing with Rich Non-local Features
ACL 2011
��Ϊ�����������ѧϰ��ܣ�����ĸ�֪��������ƪ����
Collins, Michael
Discriminative Training Methods for Hidden Markov Models: Theory and Experiments with Perceptron Algorithms
EMNLP 2002
ʵ��ϸ��
���¿�ͷ�Ľ�������˻������ձ����Ͽ��22����Stanford ������ִ�����£�
java -mx10000m -cp "$scriptdir/*:" edu.stanford.nlp.parser.lexparser.LexicalizedParser \
-outputFormat "penn" edu/stanford/nlp/models/lexparser/englishFactored.ser.gz $*
Ӧ����һ��С�ĺ���������Stanford ������Ϊ�������ӵļ����ǣ�ʹ���ַ��� PTB ��ǣ�
"""Stanford parser retokenises numbers. Split them."""
import sys
import re
qp_re = re.compile('\xc2\xa0')
for line in sys.stdin:
line = line.rstrip()
if qp_re.search(line):
line = line.replace('(CD', '(QP (CD', 1) + ')'
line = line.replace('\xc2\xa0', ') (CD ')
print line
�ɴ˲�����PTB��ʽ���ļ�ת����ʹ�� Stanford ת������������ϵ��
for f in $1/*.mrg; do
echo $f
grep -v CODE $f > "$f.2"
out="$f.dep"
java -mx800m -cp "$scriptdir/*:" edu.stanford.nlp.trees.EnglishGrammaticalStructure \
-treeFile "$f.2" -basic -makeCopulaHead -conllx > $out
done
�Ҳ������Ķ�ȡ�ˣ�����Ӧ��ֻ��ʹ���������һ�����ã���һ��Ŀ¼�µ�ÿ��.mrg�ļ�ת����һ��CoNULL��ʽ�� Stanford ���������ļ���
�����Ҵӻ������ձ����Ͽ��22��ת���˻ƽ��������������ȷ�ķ�����ָ����δ��DZ�ʶ��δ��ǵĸ����������绡ͷ������
Ϊ��ѵ�� parser.py���ҽ��������ձ����Ͽ� 02-21 �Ļƽ�� PTB ���ṹ�����ͬһ��ת���ű��С�
һ���Ա�֮��Stanford ģ�ͺ� parser.py ��ͬһ������н���ѵ����������֪���𰸵ij��в��Լ��Ͻ���Ԥ�⡣ȷ����ָ���Ǵ�Զ�����ȷ������״ʡ�
��һ�� 2.4Ghz �� Xeon �������ϲ����ٶȡ����ڷ������Ͻ�����ʵ�飬Ϊ Stanford �������ṩ�˸����ڴ档parser.py ϵͳ���ҵ�MacBook Air���������á���parser.py ��ʵ���У���ʹ����PyPy�������ڵĻ���ȣ�CPython��Լ����һ�롣
parser.py �������֮���һ��ԭ����������δ��ǽ���������������ʵ�飬����ǵĽ�����������400����ȷ����ߴ�Լ1%��������ܷ������ݣ�ʹ������Ӧ�ѱ�ǵĽ������Զ�����˵���ǺܺõĶ������ᡣ
RedShift �������Ľ���ǴӰ汾 b6b624c9900f3bf ȡ���ģ��������£�
./scripts/train.py -x zhang+stack -k 8 -p ~/data/stanford/train.conll ~/data/parsers/tmp
./scripts/parse.py ~/data/parsers/tmp ~/data/stanford/devi.txt /tmp/parse/
./scripts/evaluate.py /tmp/parse/parses ~/data/stanford/dev.conll
jsjbwy