import requests
from lxml import etree
from fake_useragent import UserAgent
import time
import re
import random
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser;",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36",
]
def save(long_str):
try:
with open(f"exhibition.csv", "a+", encoding="utf-8") as f:
f.write(long_str)
except Exception as e:
print(e)
def get_detail(url):
try:
headers = {"User-Agent": random.choice(USER_AGENTS)}
res = requests.get(url=url, headers=headers)
text = res.text
html = etree.HTML(text)
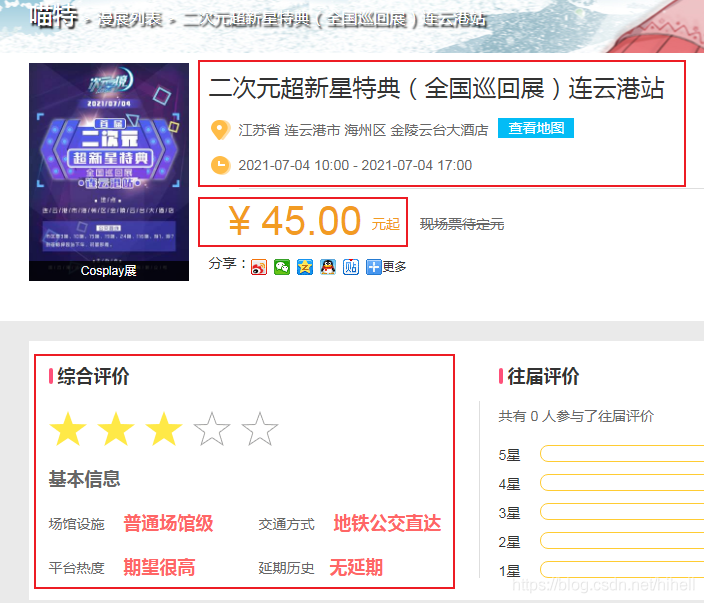
address_detail = html.xpath("//span[@class='fl mr10']/text()")[0]
time_interval = html.xpath(
"//div[@class='h25 line25 s6 f14 w100s mb10']/text()")[3].strip()
ticket_price = html.xpath("//b[@class='f40']/text()")[0]
score_url = html.xpath("//div[@class='mt10']/img/@src")[0]
score = re.search(
r"//static.nyato.cn/expo-image/stars/star-(\d\.\d).png", score_url).group(1)
other = ",".join(html.xpath(
"//span[@class='sf6 f18 fwb ml15']/text()"))
return ticket_price, time_interval, address_detail, score, other
except Exception as e:
print("����ҳBUG")
print(url)
time.sleep(4)
get_detail(url)
print(e)
def run(url):
try:
headers = {"User-Agent": random.choice(USER_AGENTS)}
res = requests.get(url=url, headers=headers)
text = res.text
html = etree.HTML(text)
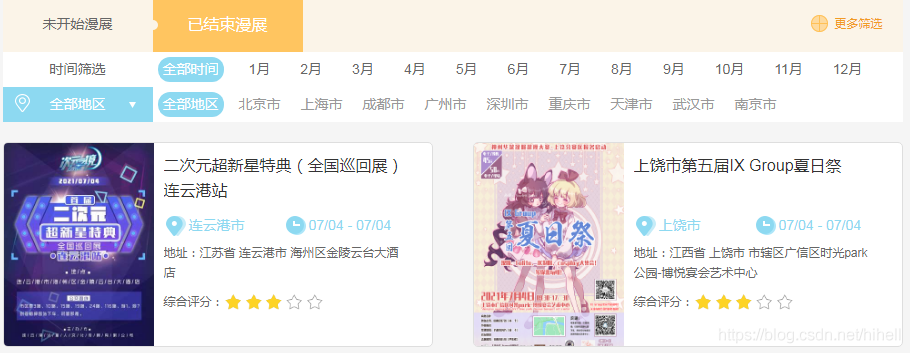
lis = html.xpath("//ul[@class='w980 pt20']/li")
for li in lis:
href = li.xpath(".//a/@href")[0]
title = li.xpath(".//a/@title")[0]
city = li.xpath(".//span[@class='w120 fl']/text()")[0].strip()
ticket_price, time_interval, address_detail, score, other = get_detail(
href)
long_str = f"{href},{title},{city},{ticket_price},{time_interval},{address_detail},{score},{other}\n"
save(long_str)
except Exception as e:
print("�б�ҳBUG")
print(url)
time.sleep(4)
run(url)
print(e)
if __name__ == '__main__':
urls = []
for i in range(1, 1313):
urls.append(f"https://www.nyato.com/manzhan/?type=expired&p={i}")
for url in urls:
print(f"����ץȡ{url}")
run(url)
print("ȫ����ȡ���")
������������ȡ��չ����ʱ,������ re ģ��,���ַ�����ȡ������,�������ʽ�������Ի��DZȽϸߵġ�
ͨ������ֱ�Ӵ�ͼƬ��ַ�н�������ȡ����,��������������������ԭ����,����ͼƬ�й����ѭ,ͼƬ��������,������ͼƬ�ɷ������Ӷ��ɡ�
//static.nyato.cn/expo-image/stars/star-3.0.png
//static.nyato.cn/expo-image/stars/star-3.5.png
���������ͨ����ͬ������ҳ,�鿴ҳ��Դ���á�
������������ȡ�÷ֲ��ֵĴ��롣
score_url = html.xpath("//div[@class='mt10']/img/@src")[0]
score = re.search(r"//static.nyato.cn/expo-image/stars/star-(\d\.\d).png", score_url).group(1)
��ƪ���͵��ص������� lxml ģ��ʹ�� XPath ��ȡ���ݲ��֡��漰���Ĵ�������,�����ص��ע�����б�����:
// ��ƥ��ѡ��ĵ�ǰ�ڵ�ѡ���ĵ��еĽڵ�;[@class=xxxx] ƥ������;@src ��ȡ����ֵ;text() ƥ���ǩ�ڲ����֡�
������Ҫ���յ�,���� ./ ѡȡ��ǰ�ڵ�,../ ѡȡ��ǰ�ڵ�ĸ��ڵ㡣
address_detail = html.xpath("//span[@class='fl mr10']/text()")[0]
time_interval = html.xpath("//div[@class='h25 line25 s6 f14 w100s mb10']/text()")[3].strip()
ticket_price = html.xpath("//b[@class='f40']/text()")[0]
score_url = html.xpath("//div[@class='mt10']/img/@src")[0]
ץȡ���չʾʱ��
����ץȡ������,�Ѿ��ϴ��� CSDN ����Ƶ��,Դ������ڴ���Ƶ����
�����������ص�ַ:https://codechina.csdn.net/hihell/python120,NO12��
��������ȡ�����в����ĸ���ѧϰ����,���ֻ��Ҫ����,��ȥ����Ƶ������~��
- 10000+��չ��ʷ����,��ʡ¥ N Ԫ,ʣ�µ� 10000+˽����Ƥ����ȡ
��ȡ��Դ����ѧϰʹ��,��Ȩɾ��
�齱ʱ��
�������� 100,�����ȡһ�����˶���,
��ȡ 29.9 Ԫ��Python ��Ϸ���硷ר�� 1 �۹���ȯһ��,ֻ�� 2.99 Ԫ��
�����dz���д���ĵ� 176 / 200 �졣
������ע��,�����ҡ������ҡ��ղ�������
����Ķ�
- 10 �д��뼯 2000 ����Ůͼ,Python ���� 120 ��,������;
- �ܺ���˵����û������������,�Ͻ��� Python ѧϰһ��,û�뵽
- ���� Python ��ҹ������ 100G ͼƬ,ֻΪ�˷�ֹ��վ����ʧ
- 5000 �Ÿ����ֽ��ͼ(�ֻ���),�� Python �ڷ��ɵı�Ե����̽��һ��
- ����������֮��,��������,�Ȳ��������� Python ����Ѷ����������,������
cs