class Solution:
def maximalSquare(self, matrix):
print('==np.array(matrix):\n', np.array(matrix))
h = len(matrix)
w = len(matrix[0])
max_side = 0
dp = [[0 for j in range(w)] for i in range(h)]
print('==dp:', np.array(dp))
for i in range(h):
for j in range(w):
if matrix[i][j] == '1' and i>0 and j>0:
dp[i][j] = min(dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]) + 1
max_side = max(max_side, dp[i][j])
elif i==0:
dp[i][j] = int(matrix[i][j])
max_side = max(max_side, dp[i][j])
elif j==0:
dp[i][j] = int(matrix[i][j])
max_side = max(max_side, dp[i][j])
else:
pass
print('==dp:', np.array(dp))
# print(max_side)
return max_side**2
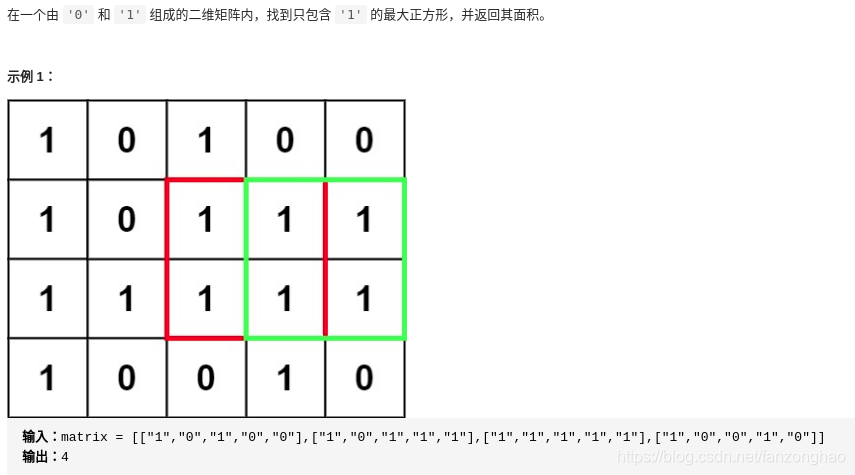
matrix = [["1", "0", "1", "0", "0"], ["1", "0", "1", "1", "1"], ["1", "1", "1", "1", "1"], ["1", "0", "0", "1", "0"]]
sol = Solution()
sol.maximalSquare(matrix)

201.统计全为 1 的正方形子矩阵

思路:动态规划 if 0, dp[i][j] =0
if 1, dp[i][j] = min(dp[i-1][j-1],dp[i-1][j],dp[i][j-1])+1
为1的时候 res自加1,再加上dp[i][j]增加的部分,也可以看成是dp的和
class Solution:
def countSquares(self, matrix):
print('==np.array(matrix)\n', np.array(matrix))
h = len(matrix)
w = len(matrix[0])
dp = [[0 for i in range(w)] for j in range(h)]
print('==np.array(dp):', np.array(dp))
res = 0
for i in range(h):
for j in range(w):
if matrix[i][j] == 1 and i > 0 and j > 0:
res += 1
dp[i][j] = min(dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]) + 1
res += dp[i][j] - 1 # 减去1代表增加的矩形个数
elif i==0:
dp[i][j] = matrix[i][j]
if matrix[i][j] == 1:
res+=1
elif j==0:
dp[i][j] = matrix[i][j]
if matrix[i][j] == 1:
res+=1
else:
pass
print('==np.array(dp):', np.array(dp))
print('==after res:', res)
return res
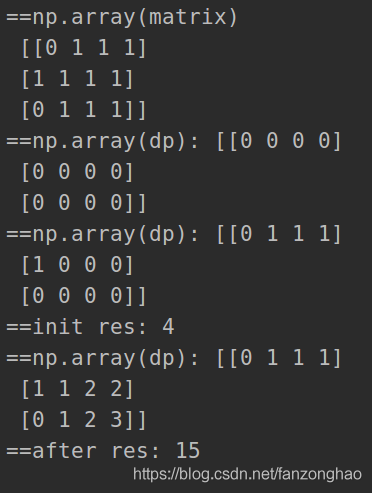
matrix = [
[0, 1, 1, 1],
[1, 1, 1, 1],
[0, 1, 1, 1]
]
sol = Solution()
sol.countSquares(matrix)
202.平方数之和

思路:双指针 左右收缩即可
class Solution:
def judgeSquareSum(self, c: int) -> bool:
from math import sqrt
right = int(sqrt(c))
left = 0
while(left <= right):
sum_ = left**2 + right**2
if (sum_ == c):
return True
elif sum_ > c:
right -= 1
else:
left += 1
return False
c++实现:
?
class Solution {
public:
bool judgeSquareSum(int c) {
long left = 0, right = sqrt(c);
while(left <= right){
long sum_ = left*left + right*right;
if(sum_ == c){
return true;
}
else if(sum_ > c){
right--;
}
else{
left++;
}
}
return false;
}
};
203.分发饼干

思路:排序加贪心 先给胃口小的饼干
#思路:排序加贪心 先让胃口小的孩子满足
class Solution:
def findContentChildren(self, g, s):
print('==g:', g)
print('==s:', s)
g = sorted(g)#孩子
s = sorted(s)#饼干
res = 0
for j in range(len(s)):#遍历饼干 先给胃口小的分配
if res<len(g):
if g[res]<=s[j]:
res+=1
print('==res:', res)
return res
g = [1,2]
s = [1,2,3]
# g = [1, 2, 3]
# s = [1, 1]
sol = Solution()
sol.findContentChildren(g, s)
204.三角形最小路径和

?思路:动态规划
class Solution:
def minimumTotal(self, triangle: List[List[int]]) -> int:
for i in range(1, len(triangle)):
for j in range(len(triangle[i])):
if j == 0:
triangle[i][j] = triangle[i-1][j] + triangle[i][j]
elif j == i:
triangle[i][j] = triangle[i-1][j-1] + triangle[i][j]
else:
triangle[i][j] = min(triangle[i-1][j-1], triangle[i-1][j]) + triangle[i][j]
return min(triangle[-1])
c++:
class Solution {
public:
int minimumTotal(vector<vector<int>>& triangle) {
int h = triangle.size();
for(int i = 1; i < triangle.size(); i++){
for(int j = 0; j < triangle[i].size(); j++){
if(j == 0){
triangle[i][j] = triangle[i-1][j] + triangle[i][j];
}
else if(j == i){
triangle[i][j] = triangle[i-1][j-1] + triangle[i][j];
}
else{
triangle[i][j] = min(triangle[i-1][j-1], triangle[i-1][j]) + triangle[i][j];
}
}
}
return *min_element(triangle[h - 1].begin(), triangle[h - 1].end());
}
};
205.同构字符串

思路:hash 构造映射关系
class Solution:
def isIsomorphic(self, s: str, t: str) -> bool:
if len(s) != len(t):
return False
dic = {}
for i in range(len(s)):
if s[i] not in dic:#未出现过
if t[i] in dic.values():#value已经出现过之前构造的dict中了
return False
dic[s[i]] = t[i]
else:#出现过
if dic[s[i]]!=t[i]:
return False
return True
# s = "egg"
# t = "add"
s="ab"
t="aa"
sol = Solution()
sol.isIsomorphic(s, t)
206.单词接龙 II

思路:构建图 然后bfs
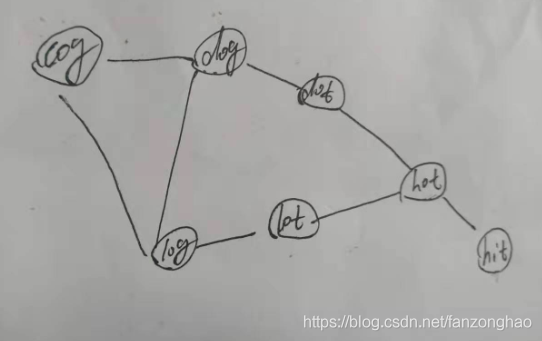
class Solution:
def findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:
cost = {}
for word in wordList:
cost[word] = float("inf")
cost[beginWord] = 0
# print('==cost:', cost)
# neighbors = collections.defaultdict(list)
neighbors = {}
ans = []
#构建图
for word in wordList:
for i in range(len(word)):
key = word[:i] + "*" + word[i + 1:]
if key not in neighbors:
neighbors[key] = []
neighbors[key].append(word)
else:
neighbors[key].append(word)
# print('==neighbors:', neighbors)
q = collections.deque([[beginWord]])
# q = [[beginWord]]
# print('====q:', q)
#bfs
while q:
# path = q.popleft()
path = q.pop()
# print('===path:', path)
cur = path[-1]
if cur == endWord:
ans.append(path.copy())
else:
for i in range(len(cur)):
new_key = cur[:i] + "*" + cur[i + 1:]
if new_key not in neighbors:
continue
for neighbor in neighbors[new_key]:
# print('==cost[cur] + 1, cost[neighbor]:', cost[cur] + 1, cost[neighbor])
if cost[cur] + 1 <= cost[neighbor]:
q.append(path + [neighbor])
cost[neighbor] = cost[cur] + 1
# print('==ans:', ans)
return ans
208.最后一块石头的重量

思路1:while循环 排序从大到小 一直取前两块石头进行比较
class Solution:
def lastStoneWeight(self, stones):
while len(stones)>=2:
stones = sorted(stones)[::-1]
if stones[0]==stones[1]:
stones=stones[2:]
else:
stones = [stones[0]-stones[1]]+stones[2:]
print('===stones:', stones)
return stones[-1] if len(stones) else 0
stones = [2, 7, 4, 1, 8, 1]
# stones = [2, 2]
sol = Solution()
res= sol.lastStoneWeight(stones)
print('==res:', res)
更简洁写法:
class Solution:
def lastStoneWeight(self, stones: List[int]) -> int:
while len(stones) >= 2:
stones = sorted(stones)
stones.append(stones.pop() - stones.pop())
return stones[0]
思路2:堆队列,也称为优先队列
import heapq
class Solution:
def lastStoneWeight(self, stones):
h = [-stone for stone in stones]
heapq.heapify(h)
print('==h:', h)
while len(h) > 1:
a, b = heapq.heappop(h), heapq.heappop(h)
if a != b:
heapq.heappush(h, a - b)
print('==h:', h)
return -h[0] if h else 0
stones = [2, 7, 4, 1, 8, 1]
# stones = [2, 2]
sol = Solution()
res= sol.lastStoneWeight(stones)
print('==res:', res)

210.无重叠区间

class Solution:
def eraseOverlapIntervals(self, intervals):
n = len(intervals)
if n<=0:
return 0
intervals = sorted(intervals, key=lambda x: x[-1])
print('==intervals:', intervals)
res = [intervals[0]]
for i in range(1, n):
if intervals[i][0] >= res[-1][-1]:
res.append(intervals[i])
print(res)
return n - len(res)
# intervals = [[1, 2], [2, 3], [3, 4], [1, 3]]
# intervals = [[1,100],[11,22],[1,11],[2,12]]
intervals = [[0, 2], [1, 3], [2, 4], [3, 5], [4, 6]]
sol = Solution()
sol.eraseOverlapIntervals(intervals)

212.种花问题

思路:判断是否是1或0,1就一种情况,0有两种情况
100 先判断1
?01000,要判断i为0时,i+1是否为1,否则说明就是001这种情况
# 100 先判断1
# 01000,要判断i为0时,i+1是否为1,否则说明就是001这种情况
class Solution:
def canPlaceFlowers(self, flowerbed, n):
i = 0
res = 0
while i<len(flowerbed):
if flowerbed[i]==1:
i+=2
else:
if i+1<len(flowerbed) and flowerbed[i+1]==1:
i+=3
else:
res+=1
i+=2
return True if res>=n else False
# flowerbed = [1,0,0,0,1]
# n = 1
# flowerbed = [1,0,0,0,1]
# n = 2
# flowerbed = [1,0,0,0,0,0,1]
# n = 2
flowerbed = [1,0,0,0,1,0,0]
n = 2
sol = Solution()
res= sol.canPlaceFlowers(flowerbed, n)
print('==res:', res)
216.较大分组的位置
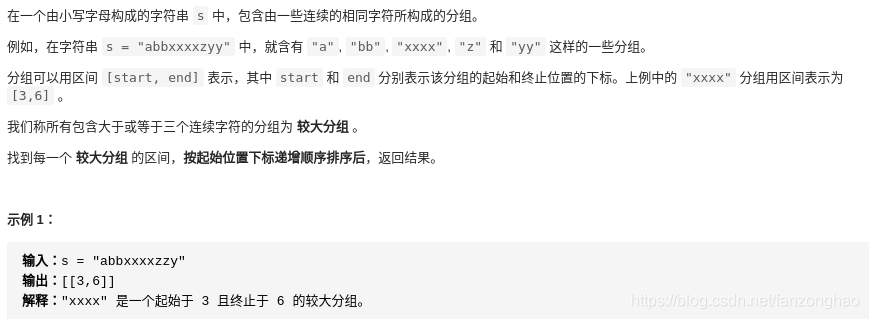
其实就是再求聚类
思路1:动态规划
class Solution:
def largeGroupPositions(self, s):
dp = [0] * len(s)
for i in range(1, len(s)):
if s[i] == s[i - 1]:
dp[i] = 1
dp.append(0)
print('==dp:', dp)
index = [j for j in range(len(dp)) if dp[j] == 0]
print('index:', index)
res = []
for k in range(len(index) - 1):
if index[k + 1] - index[k] >= 3:
res.append([index[k], index[k + 1] - 1])
print('=res:', res)
return res
s = "abbxxxxzzy"
sol = Solution()
sol.largeGroupPositions(s)
思路2:双指针
# 双指针
class Solution:
def largeGroupPositions(self, s):
res = []
left, right = 0, 0
while left < len(s):
right = left + 1
while right < len(s) and s[right] == s[left]:
right += 1
if right - left >= 3:
res.append([left, right - 1])
# 左指针跑到右指针位置
left = right
print('==res:', res)
return res
s = "abbxxxxzzy"
# s = "abcdddeeeeaabbbcd"
sol = Solution()
sol.largeGroupPositions(s)
217.省份数量

思路:
可以把 n 个城市和它们之间的相连关系看成图, #
城市是图中的节点,相连关系是图中的边,
?给定的矩阵isConnected 即为图的邻接矩阵,省份即为图中的连通分量。
利用dfs将一个数组view遍历过的城市置位1。
# dfs
# 可以把 nn 个城市和它们之间的相连关系看成图,
# 城市是图中的节点,相连关系是图中的边,
# 给定的矩阵isConnected 即为图的邻接矩阵,省份即为图中的连通分量。
class Solution:
def travel(self, isConnected, i, n):
self.view[i] = 1 # 表示已经遍历过
for j in range(n):
if isConnected[i][j] == 1 and not self.view[j]:
self.travel(isConnected, j, n)
def findCircleNum(self, isConnected):
n = len(isConnected)
self.view = [0] * n
res = 0
for i in range(n):
if self.view[i] != 1:
res += 1
self.travel(isConnected, i, n)
print('==res:', res)
return res
# isConnected = [[1, 1, 0],
# [1, 1, 0],
# [0, 0, 1]]
isConnected = [[1,0,0],
[0,1,0],
[0,0,1]]
sol = Solution()
sol.findCircleNum(isConnected)
218.旋转数组

思路1:截断拼接,注意的是一些边界条件需要返回原数组
class Solution:
def rotate(self, nums: List[int], k: int) -> None:
if len(nums)<=1 or k==0 or k%len(nums)==0:
return nums
n = len(nums)
k = k%n
# print(nums[-k:]+nums[:n-k])
nums[:] = nums[-k:]+nums[:n-k]
return nums
思路2:先左翻转,在右翻转,在整体翻转?
class Solution:
def reverse(self, i, j, nums):#交换位置的
while i < j:#
nums[i], nums[j] = nums[j], nums[i]
i += 1
j -= 1
def rotate(self, nums, k):
"""
Do not return anything, modify nums in-place instead.
"""
n = len(nums)
k %= n #有大于n的数
self.reverse(0, n - k - 1, nums) #左翻
self.reverse(n - k, n - 1, nums) #右翻
self.reverse(0, n - 1, nums) #整体翻
print(nums)
return nums
# nums = [1,2,3,4,5,6,7]
# k = 3
nums = [1,2,3,4,5,6]
k = 11
sol = Solution()
sol.rotate(nums, k)

219.汇总区间
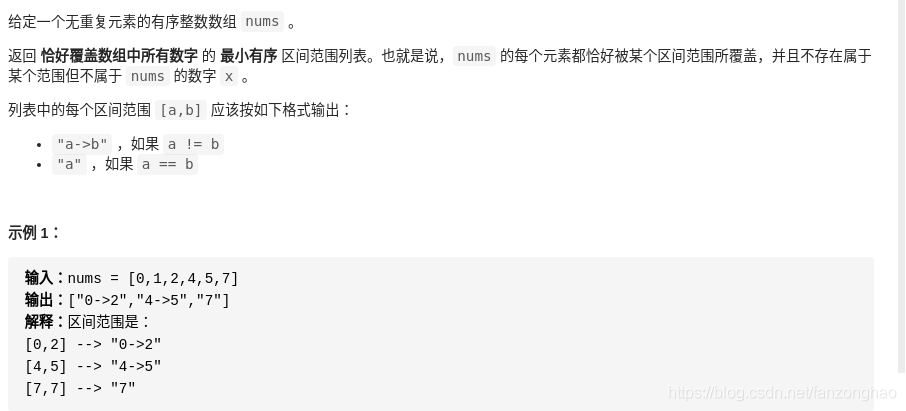
思路:双指针
class Solution:
def summaryRanges(self, nums):
res = []
left =0
right = 0
while right<len(nums):
right = left+1
while right<len(nums) and nums[right] - nums[right-1] == 1:
right+=1
if right -1>left:
res.append(str(nums[left]) + "->" + str(nums[right-1]))
else:
res.append(str(nums[left]))
left = right
print(res)
return res
nums = [0,1,2,4,5,7]
sol = Solution()
sol.summaryRanges(nums)
220.冗余连接

思路:并查集
#并查集:合并公共节点的,对相邻节点不是公共祖先的进行合并
class Solution:
def find(self, index): # 查询
if self.parent[index] == index: # 相等就返回
return index
else:
return self.find(self.parent[index]) # 一直递归找到节点index的祖先
def union(self, i, j): # 合并
self.parent[self.find(i)] = self.find(j)
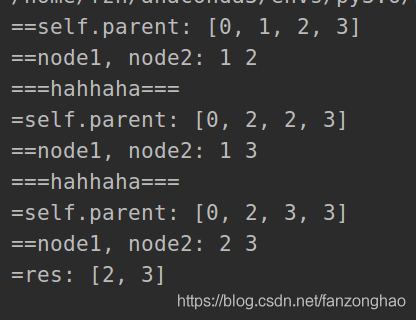
def findRedundantConnection(self, edges):
nodesCount = len(edges)
self.parent = list(range(nodesCount + 1))
print('==self.parent:', self.parent)
for node1, node2 in edges:
print('==node1, node2:', node1, node2)
if self.find(node1) != self.find(node2):#相邻的节点公共祖先不一样就进行合并
print('===hahhaha===')
self.union(node1, node2)
print('=self.parent:', self.parent)
else:
return [node1, node2]
return []
edges = [[1, 2], [1, 3], [2, 3]]
sol = Solution()
res = sol.findRedundantConnection(edges)
print('=res:', res)
223.可被 5 整除的二进制前缀

思路:二进制移位 在和5求余
class Solution:
def prefixesDivBy5(self, A: List[int]) -> List[bool]:
res = [False]*len(A)
value = 0
for i in range(len(A)):
value = (value<<1) + A[i]
# print(value)
if value%5==0:
res[i]=True
return res
225.移除最多的同行或同列石头

思路1:?其实主要是算连通域的个数,当满足同行或者同列就算联通,
?输出的结果就是石头个数减去连通域个数,第一种解法超时
# 其实主要是算连通域的个数,当满足同行或者同列就算联通,
# 输出的结果就是石头个数减去连通域个数
#第一种直接dfs会超时
import numpy as np
class Solution:
def dfs(self, rect, i, j, h, w):
if i < 0 or i >= h or j < 0 or j >= w or rect[i][j] != 1:
return
rect[i][j] = -1
for i_ in range(h):
self.dfs(rect, i_, j, h, w)
for j_ in range(w):
self.dfs(rect, i, j_, h, w)
def removeStones(self, stones):
n = 10
rect = [[0 for _ in range(n)] for _ in range(n)]
print(len(rect))
for stone in stones:
rect[stone[0]][stone[-1]] = 1
print('before np.array(rect):', np.array(rect))
h, w = n, n
graphs = 0
for i in range(h):
for j in range(w):
if rect[i][j] == 1:
graphs += 1
self.dfs(rect, i, j, h, w)
print('after np.array(rect):', np.array(rect))
print(graphs)
return len(stones) - graphs
stones = [[0, 0], [0, 1], [1, 0], [1, 2], [2, 1], [2, 2]]
sol = Solution()
res = sol.removeStones(stones)
print('===res:', res)

思路2:并查集
class Solution:
# 并查集查找
def find(self, x):
if self.parent[x] == x:
return x
else:
return self.find(self.parent[x])
#合并
def union(self,i, j):
self.parent[self.find(i)] = self.find(j)
def removeStones(self, stones):
# 因为x,y所属区间为[0,10^4]
# n = 10001
n = 10
self.parent = list(range(2 * n))
for i, j in stones:
self.union(i, j + n)
print('==self.parent:', self.parent)
# 获取连通区域的根节点
res = []
for i, j in stones:
res.append(self.find(i))
print('=res:', res)
return len(stones) - len(set(res))
stones = [[0, 0], [0, 1], [1, 0], [1, 2], [2, 1], [2, 2]]
sol = Solution()
res = sol.removeStones(stones)
print('===res:', res)
226..缀点成线

思路:判断斜率 将除换成加
class Solution:
def checkStraightLine(self, coordinates):
n = len(coordinates)
for i in range(1, n-1):
if (coordinates[i+1][1]-coordinates[i][1])*(coordinates[i][0]-coordinates[i-1][0])=(coordinates[i][1]-coordinates[i-1][1])*(coordinates[i+1][0]-coordinates[i][0]):
return False
return True
coordinates = [[1,2],[2,3],[3,4],[4,5],[5,6],[6,7]]
sol = Solution()
sol.checkStraightLine(coordinates)
227.账户合并

思路:并查集
#思想是搜索每一行的每一个邮箱,如果发现某一行的某个邮箱在之前行出现过,那么把该行的下标和之前行通过并查集来合并,
class Solution(object):
def find(self, x):
if x == self.parents[x]:
return x
else:
return self.find(self.parents[x])
def union(self,i, j):
self.parents[self.find(i)] = self.find(j)
def accountsMerge(self, accounts):
# 用parents维护每一行的父亲节点
# 如果parents[i] == i, 表示当前节点为根节点
self.parents = [i for i in range(len(accounts))]
print('==self.parents:', self.parents)
dict_ = {}
# 如果发现某一行的某个邮箱在之前行出现过,那么把该行的index和之前行合并(union)即可
for i in range(len(accounts)):
for email in accounts[i][1:]:
if email in dict_:
self.union(dict_[email], i)
else:
dict_[email] = i
print('===self.parents:', self.parents)
print('=== dict_:', dict_)
import collections
users = collections.defaultdict(set)
print('==users:', users)
res = []
# 1. users:表示每个并查集根节点的行有哪些邮箱
# 2. 使用set:避免重复元素
# 3. 使用defaultdict(set):不用对每个没有出现过的根节点在字典里面做初始化
for i in range(len(accounts)):
for account in accounts[i][1:]:
users[self.find(i)].add(account)
print('==users:', users)
# 输出结果的时候注意结果需按照字母顺序排序(虽然题目好像没有说)
for key, val in users.items():
res.append([accounts[key][0]] + sorted(list(val)))
return res
accounts = [["John", "johnsmith@mail.com", "john00@mail.com"],
["John", "johnnybravo@mail.com"],
["John", "johnsmith@mail.com", "john_newyork@mail.com"],
["Mary", "mary@mail.com"]]
# [["John", 'john00@mail.com', 'john_newyork@mail.com', 'johnsmith@mail.com'],
# ["John", "johnnybravo@mail.com"],
# ["Mary", "mary@mail.com"]]
sol = Solution()
res= sol.accountsMerge(accounts)
print(res)

228.连接所有点的最小费用

思路1: 其实就是求最小生成树,首先想到的是kruskal 但是时间复杂度较高,超时
# 其实就是求最小生成树:采用kruskal 但是时间复杂度较高,超时
class Solution:
def minCostConnectPoints(self, points):
edge_list = []
nodes = len(points)
for i in range(nodes):
for j in range(i):
dis = abs(points[i][0] - points[j][0]) + abs(points[i][1] - points[j][1])
edge_list.append([i, j, dis])
print('==edge_list:', edge_list)
edge_list = sorted(edge_list, key=lambda x: x[-1])
print('==edge_list:', edge_list)
group = [[i] for i in range(nodes)]
print('==group:', group)
res = 0
for edge in edge_list:
for i in range(len(group)):
if edge[0] in group[i]:
m = i # 开始节点
if edge[1] in group[i]:
n = i # 结束节点
if m != n:
# res.append(edge)
res += edge[-1]
group[m] = group[m] + group[n]
group[n] = []
print(group)
print('==res:', res)
return res
points = [[0, 0], [2, 2], [3, 10], [5, 2], [7, 0]]
sol = Solution()
sol.minCostConnectPoints(points)

思路2: 其实就是求最小生成树,首先想到的是prim 但是时间复杂度较高,超时
# prim算法 超出时间限制
class Solution:
def minCostConnectPoints(self, points):
# edge_list = []
nodes = len(points)
Matrix = [[0 for i in range(nodes)] for j in range(nodes)]
for i in range(nodes):
for j in range(nodes):
dis = abs(points[i][0] - points[j][0]) + abs(points[i][1] - points[j][1])
# edge_list.append([i, j, dis])
Matrix[i][j] = dis
# print('===edge_list:', edge_list)
print('==Matrix:', Matrix)
selected_node = [0]
candidate_node = [i for i in range(1, nodes)] # 候选节点
print('==candidate_node:', candidate_node)
# res = []
res = 0
while len(candidate_node):
begin, end, minweight = 0, 0, float('inf')
for i in selected_node:
for j in candidate_node:
if Matrix[i][j] < minweight:
minweight = Matrix[i][j]
begin = i # 存储开始节点
end = j # 存储终止节点
# res.append([begin, end, minweight])
print('==end:', end)
res += minweight
selected_node.append(end) # 找到权重最小的边 加入可选节点
candidate_node.remove(end) # 候选节点被找到 进行移除
print('==res:', res)
return res
points = [[0, 0], [2, 2], [3, 10], [5, 2], [7, 0]]
# points = [[-1000000, -1000000], [1000000, 1000000]]
sol = Solution()
sol.minCostConnectPoints(points)