���ı���:DIRECT MULTI-HOP ATTENTION BASED GRAPH NEURAL NETWORKS
��������:
����ͼ����������ѧϰ�������ע:

ժҪ
��ͼ������(GNN)��������ע��������(self-attention)����ʵ��ͼ��ʾѧϰ�����Ƚ�(state-of-the-ar)���ܡ� Ȼ����ע�������ƽ�����������ӵĽڵ�֮����м���,��ͼ��ʾ��ȡ������������ӽڵ㡣
��ע��������ȱ��Ϊ: ����ע�������㲻�ܿ����ṩ��ͼ�ṹ��������Ϣ�Ķ����ھ�(�������ڵ���2���ھ�)�Խڵ��ʾѧϰ��Ӱ�졣 ��ƪ�������������ͼ��ʾѧϰ�Ļ���ֱ�Ӷ���ע�������Ƶ�ͼ������(DAGN),���ǽ������ڽӵ���������Ϣ����ע����ֵ����ķ���,����ÿһ�����Զ�̽�����
DAGN��ע������ֵ�����ڽڵ���չ�������ڽڵ�(�����ھ�),����ÿ����Ϣ���ݲ�ĸ���Ұ������ǰ�ķ�����ͬ,DAGN��ע������ֵʱ������ɢ����(diffusion prior)�ķ���,����Ч�ؼ���ڵ��֮�������·��Ȩ�ء���������DAGN��ÿһ��ĸ���Χ�ṹ��Ϣ,���˽������Ϣ��ע�����ֲ���
����
ͼע��������(Graph Attention Network,GAT)�����ģ�ͽ�ע�����Ӧ����ͼ�����硣���Ǹ���ij����ֱ�����ӵĽڵ����ע��������,ʹ��ģ���ܹ��������ǵ�ע���������������ϵ���Ϣ,ע��������������Ϊ��һ��Ȩ�ء�
Ȼ��,���ֽ�����ij�������ӵĽڵ��ע������ζ��һ���ڵ����ֻ��ע���Ľ���(һ���ھ�,��ֱ���ھ�)������������һ���ʾ, ��������Ϣ���ݲ�ĸ���Ұ�����ڵ���ͼ�ṹ����Ȼ���Ӷ��ͼע����������������Զ����ھӵĸ���Ұ,ѧϰ�ǵ����ھӵ������,����Щ���ͼע��������ͨ�����ڹ���ƽ������������,����GAT���еı�ע����Ȩ�ؽ����ڽڵ��ʾ����,��������ͼ�ṹ�����������ġ���֮,����ע���������������̽��ͼ�ṹ��Ϣ��ע����Ȩ��֮������Ե���������ǰ�Ĺ���(Xu et al.,2018;Klicpera et al.,2019b)�Ѿ���ʾ���ڵ�����ִ�ж�����Ϣ���ݵ�����,�������ڵ�����̽��ͼ�ṹ��Ϣ�������,ͬʱ��Щ�������ǻ���ͼע�������Ƶġ�
���������һ�ֻ���ֱ�Ӷ���ע�������Ƶ�ͼ������(DAGN),��ͨ��һ����ӱ��ͼע������ɢ��(��ͼ)�Թ�ϵͼ���ݽ��и�Ч�Ķ�����ע����(multi-hop self-attention)���㡣
ͼע������ɢ��������Ϊ:
- ���ȼ�����ϵ�ע����Ȩ��(ij����ֱ�������ӵĽڵ��֮���ע����,��ʵ��ͷ��ʾ)
- Ȼ�����ñ��ϵ�ע����Ȩ��ͨ��һ��ע������ɢ����(attention diffusion process )�����������ڵ������ע����Ȩ��(ij���߲�ֱ�������ӵĽڵ��֮���ע�����������ھӵ�ע����,������ͷ��ʾ)
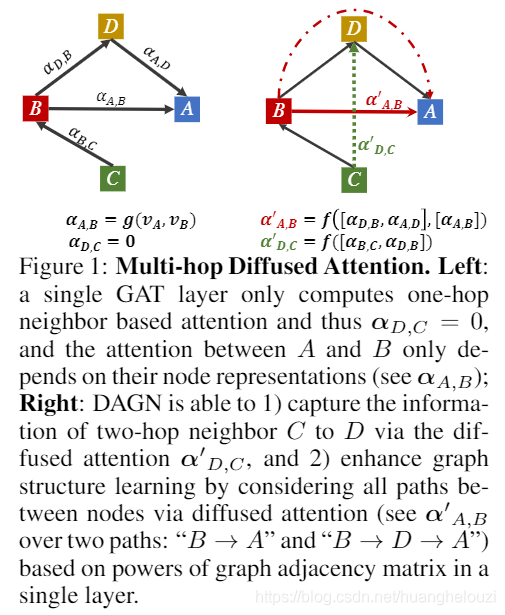
���������DAGNģ����Ҫ�������ŵ� :
- DAGN��ÿһ���в���ڵ�֮���Զ�̽���(�����ھ�֮��Ľ�����Ϣ),��ģ�Ϳ��ڶ����ھ�ʵ����Ч��Զ����Ϣ���ݡ�
- DAGN�е�ע�����������������йء�GAT�е�ע����ֵ��ȡ����ֱ�����ӽڵ�֮�����һ��Ľڵ��ʾ,δ���ӽڵ�֮���ע����ֵΪ0��������ѡ���Ķ��������ڵ��κ�һ�Կɴ�ڵ�,DAGN��ͨ�����ܽڵ��֮�����п���·��(���ȡ�1)�ϵ�ע�����÷�������ע������ ����,�ӱ�transformer �ܹ��л������,DAGN��֤����ʹ�ò��һ����ǰ������Խ�һ��������ܡ�
����
DAGN��ϵ�ṹ
DAGN������GNN�Ļ�����,ͬʱ�ں���ͼע�������ƺ���ɢ����(Graph Attention and Diffusion technique)������,DAGN�ĺ����Ƕ���ע������ɢ(Multi-hop Attention Diffusion)��DAGN��ϵ�ṹ����ͼ��ʾ��
ÿ��DAGN�����ע�����������,ע������ɢ���,�������һ�����,ǰ���������2���������������ɡ�DAGN����Զѵ��Թ���һ�����ģ�͡�����ͼ�ұ���ͼ,չʾ����ͨ��ע������ɢ����ʵ�������������йص�ע����������
v
i
,
v
j
,
v
p
,
v
q
��
V
v_i,v_j,v_p,v_q��V
vi?,vj?,vp?,vq?��V��ͼ�еĽڵ㡣
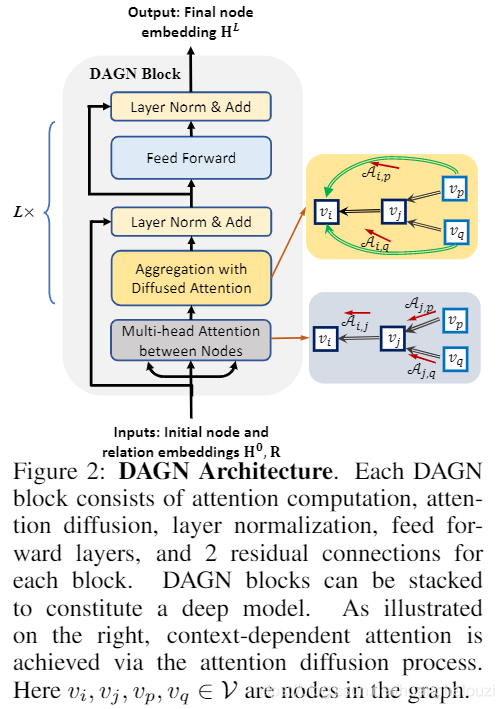
����ע������ɢ
�������Ƚ���ע������ɢ,��������DAGNÿһ���ע������������ɢ�������ӵ�������һ����Ԫ��
(
v
i
,
r
k
,
v
j
)
(v_i,r_k,v_j)
(vi?,rk?,vj?),����
v
i
,
v
j
v_i,v_j
vi?,vj?Ϊ�ڵ�
i
i
i�ͽڵ�
j
j
j,
r
k
r_k
rk?Ϊ�ڵ�
i
i
i�ͽڵ�
j
j
j֮������͡� DAGN���ȼ������б��ϵ�ע�����÷�,Ȼ��ע������ɢģ��ͨ����ɢ����,���ڱ�ע������������δ����ֱ�����ӵĽڵ��֮���ע����ֵ��
��ע��������
�ڵ�
l
l
l��,Ϊÿ����Ԫ��
(
v
i
,
r
k
,
v
j
)
(v_i,r_k,v_j)
(vi?,rk?,vj?)����һ��������Ϣ��Ϊ�˼�����
v
j
v_j
vj?��
l
+
1
l+1
l+1��ı�ʾ,���д���Ԫ�鵽
v
j
v_j
vj?��������Ϣ���ۺϳ�һ����Ϣ,Ȼ�������ڸ���
v
l
+
1
v_{l+1}
vl+1?��
����,һ����
(
v
i
,
r
k
,
v
j
)
(v_i,r_k,v_j)
(vi?,rk?,vj?)��ע�����÷������¹�ʽ����

ÿ��������������
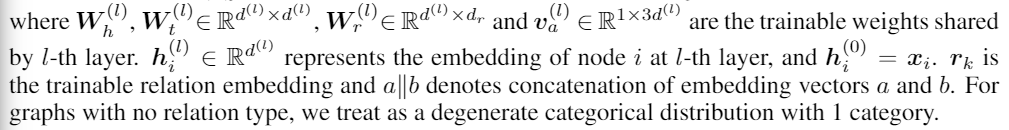
��ͼG��ÿһ������Ӧ��������ʽ,���ǿɵõ�һ��ע�����÷־���
S
(
l
)
S^{(l)}
S(l)
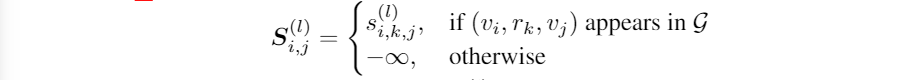
���ͨ����ע�����÷־���
S
(
l
)
S^{(l)}
S(l)ִ����ʽsoftmax�����ע��������
A
(
l
)
A^{(l)}
A(l):
A
(
l
)
=
s
o
f
t
m
a
x
(
S
(
l
)
)
A^{(l)}= softmax(S^{(l)})
A(l)=