else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
这一部分的源码大体上已如注释所描述,至此整个 putVal 方法的大体逻辑实现相信你也已经清晰了,好好回味一下.
下面我们对这部分中的某些方法的实现细节再做一些深入学习.
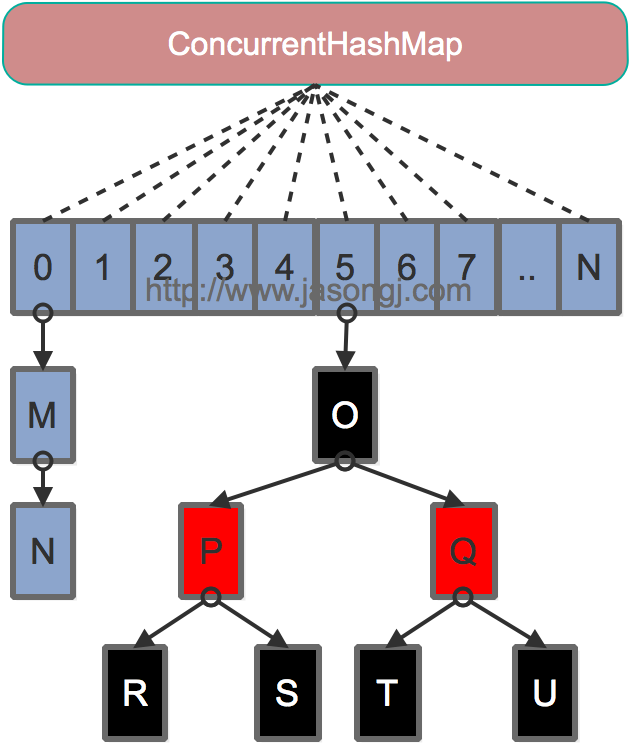
首先需要介绍一下,ForwardingNode 这个节点类型

这个节点内部保存了一个 nextTable 引用,它指向一张 hash 表;
在扩容操作中,我们需要对每个桶中的结点进行分离和转移;
如果某个桶结点中所有节点都已经迁移完成了(已经被转移到新表 nextTable);
那么会在原 table 表的该位置挂上一个 ForwardingNode 结点,说明此桶已经完成迁移.
ForwardingNode继承自 Node 结点,并且它唯一的构造函数将构建一个k/v/next 都为 null 的结点,反正它就是个标识,无需那些属性;
但是 hash 值却为 MOVED.
所以,我们在 putVal 方法中遍历整个 hash 表的桶结点,如果遇到 hash 值等于 MOVED,说明已经有线程正在扩容 rehash 操作,整体上还未完成,,过我们要插入的桶的位置已经完成了所有节点的迁移
由于检测到当前哈希表正在扩容,于是让当前线程去协助扩容.
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
Node<K,V>[] nextTab; int sc;
if (tab !=