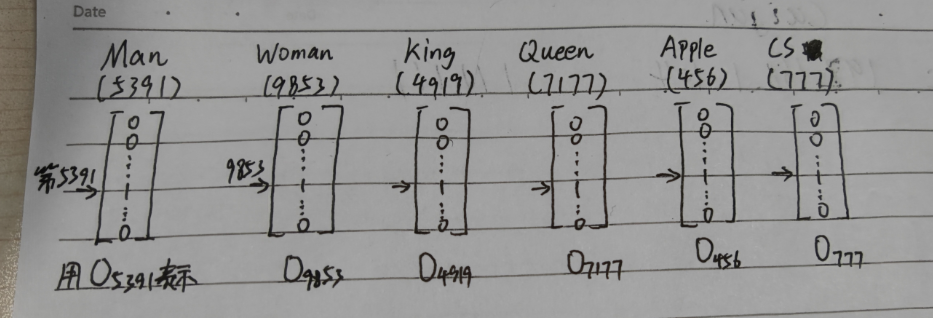
我们可以根据词的总量创建一个n行一列的矩阵,在某个词出现的地方标注为1,其余都用0填充,这样就可以唯一表示某个词了(如上图中的Man),这就是One-Hot编码的基本原理
设想你已经有一个训练好的语言模型,可以预测句子下一个词是什么,如:
我想喝可口()#模型会判断出完整句子为“我想喝可口可乐”
但是换一下
我想喝百事()#这时候你的模型可能不知道“百事”与“可口”之间的联系,自然它不会输出“我想喝百事可乐”的结果
这种情况我们称为泛化性差。
那么想要提高泛化性,我们势必要获得词语之间的关系
一种自然的思路就是增加维度
高维词语表征
这里为什么不说一种具体的方法呢?因为我还是想从举例入手,避免一步太大扯着蛋
废话不多说,还是上图
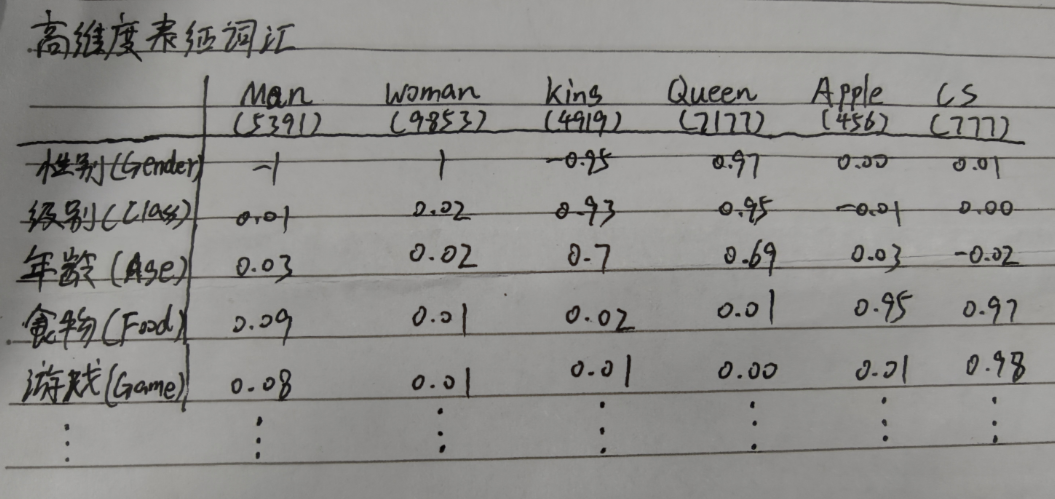
我们还是沿用之前的例子,只是这里我们加入了Apple和CS两个新词
这次试试用特征化的表示方法来表示这些词,因此,我们的学习对象从词的唯一表示变成了词的特征
例如,我们想知道这些词语与性别(gender)这个特征之间的关系
因为Man和Woman本质上就是性别的指代,这两个词应该最接近性别(gender)特征,所以我们假设男人的性别值是-1,女人的是1。
King和男人是非常相关的则可设为-0.95,Queen则与女人非常相关,可设为0.97,Apple和CS则与性别没什么关系,这显然是符合我们认知的。
注意:这里的数字只是为了说明相关性,不是由某种计算得出的(暂时不是),你也可以把King设成-0.91
图中其余特征表示原理类似
又如游戏(Game)与CS这个词相关性大,因此CS的数值为0.98,而其余的就很低,表明他们与游戏这个特征没什么关系
那么好了,现在我们把特征扩展到500个
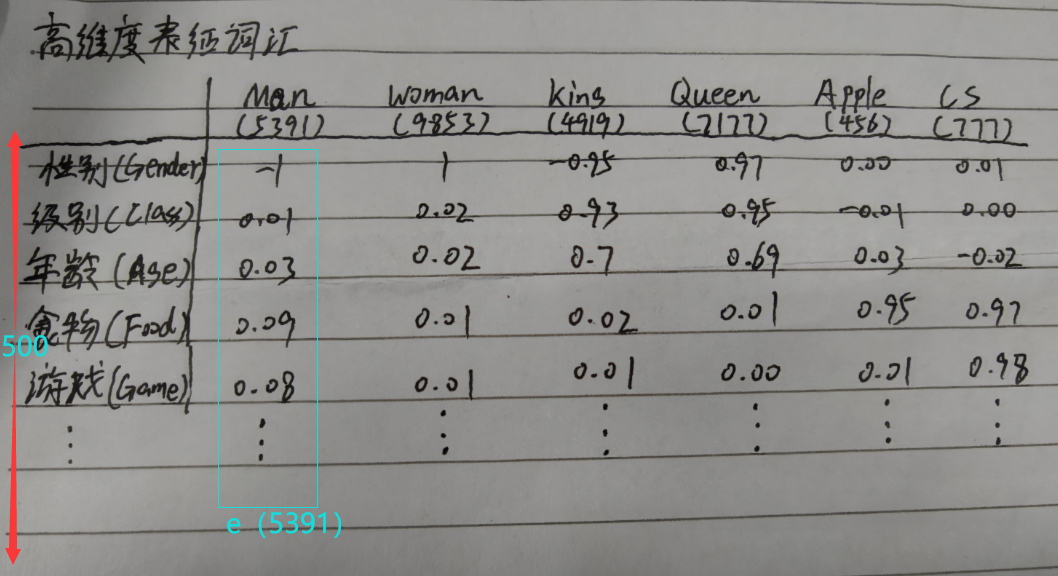
也就是说,我们有了500个维度去衡量一个词语
此时右边出现了一些由数值构成的奇怪阵列(你在看glove之类的模型时经常会看见这种东西)
现在,我们还是用一个矩阵表示一个词,这个矩阵的大小为500行1列,该矩阵由某个词的特征构成从而具有唯一性,这个矩阵被还可称为嵌入向量
由此,Man就可以表示为e_5391,同理可以表示其他词汇
因此,高维表征会比One-Hot有更好的泛化能力。
这种用300维的特征去表示一个词语的方法就称为词嵌入(word embeddings),至于为什么叫嵌入,我猜可能与高维图像的表示有关,类似于一种嵌套。