启动leaf-server 模块的 LeafServerApplication项目就跑起来了 号段模式获取分布式自增ID的测试url :http://localhost:8080/api/segment/get/leaf-segment-test 监控号段模式:http://localhost:8080/cache
leaf.snowflake.enable=true
leaf.snowflake.zk.address=127.0.0.1
leaf.snowflake.port=2181
snowflake模式获取分布式自增ID的测试url:http://localhost:8080/api/snowflake/get/test
9. 滴滴(Tinyid)
Tinyid由滴滴开发,Github地址:https://github.com/didi/tinyid
Tinyid是一个ID生成器服务,它提供了REST API和Java客户端两种获取方式,如果使用Java客户端获取方式的话,官方宣称能单实例能达到1kw QPS(Over10 million QPSper single instance when using the java client.)
Tinyid教程 的原理非常简单,通过数据库表中的数据基本是就能猜出个八九不离十,就是经典的segment模式,和美团的leaf原理几乎一致。原理图如下所示,以同一个bizType为例,每个tinyid-server会分配到不同的segment,例如第一个tinyid-server分配到(1000, 2000],第二个tinyid-server分配到(2000, 3000],第3个tinyid-server分配到(3000, 4000]: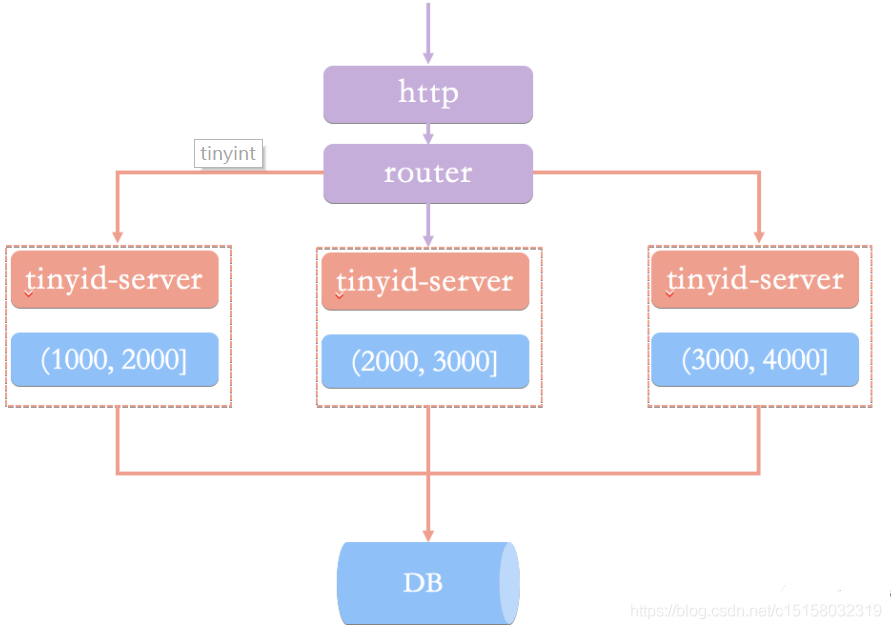
再以第一个tinyid-server为例,当它的segment用了20%(核心源码:segmentId.setLoadingId(segmentId.getCurrentId().get() + idInfo.getStep() * Constants.LOADING_PERCENT / 100);,LOADING_PERCENT的值就是20),即设定loadingId为20%的阈值,例如当前id是10000,步长为10000,那么loadingId=12000。那么当请求分布式ID分配到12001时(或者重启后),即超过loadingId,就会返回一个特殊code:new Result(ResultCode.LOADING, id);tinyid-server根据ResultCode.LOADING这个响应码就会异步分配下一个segment(4000, 5000],以此类推。
10. 梨花算法
改进的雪花算法,弱依赖时间,对毫秒不敏感,可以允许2分钟即120秒的时钟回拨(实际上可以根据业务场景设置更长或更短的容错时间),可以轻松避免润秒问题。workerid默认从配置文件获取,代码架构可方便扩展workerid分配算法,能处理workerid冲突问题。可提前消费1秒。。。
返回结果用原生long返回,异常使用小于0(<0)的数表示。
workerid有重复时,会有重号风险。应该选择合适的workerid分配方案避免。
支持批获取ID号.
梨花算法,原文介绍链接。
源码:
https://github.com/automvc/bee/blob/master/src/main/java/org/teasoft/bee/distribution/GenId.java
11. 不依赖时间的梨花算法OneTimeSnowflakeId:
进一步改进第10点提到的梨花算法。
通过代码调用生成ID插入DB的,需要整体有序性。不依赖时间的梨花算法,Workerid应放在序号的上一段,且应用SerialUniqueId算法,使ID不依赖于时间自动递增。使用不依赖时间的梨花算法,应保证各节点大概均衡轮流出号,这样入库的ID会比较有序,因此每个段号内的序列号不能太多。
支持批获取ID号。可以一次取一批ID(即一个范围内的ID一次就可以获取了)。是不是可以取代依赖DB的号段模式呢!!
可间隔时间缓存时间值到文件,供重启时设置回初值用。若不缓存,则重启时,又用目前的时间点,重设开始的ID。只要平均不超过419w/s,重启时造成的时钟回拨都不会有影响(但却浪费了辛苦攒下的每秒没用完的ID号)。要是很多时间都超过419w/s,证明你有足够的能力做这件事:间隔时间缓存时间值到文件。
详细代码,可查看源码:
https://github.com/automvc/honey/blob/master/src/main/java/org/teasoft/honey/distribution/OneTimeSnowflakeId.java
12. 连续单调递增全局唯一的ID生成算法SerialUniqueId
不依赖于时间,也不依赖于任何第三方组件,只是启动时,用一个时间作为第一个ID设置的种子,设置了初值ID后,就可获取并递增ID。在一台DB内与传统的一样,连续单调递增(而不只是趋势递增),而代表DB的workerid作为DB的区号放在高位(类似电话号码的国际区号),从所有DB节点看,则满足分布式DB生成全局唯一ID。本地(C8 I7 16g)1981ms可生成1亿个ID号,利用上批获取,分隔业务,每秒生成过10亿个ID号不成问题,能满足双11的峰值要求。
可用作分布式DB内置生成64位long型ID自增主键(数据库能更新功能,为我们生成第一个ID最好。不能的话,我们就自己根据算法设置第一个ID)。只要按本算法设置了记录的ID初值,然后默认让数据库表id主键自增就可以(如MYSQL)。这样,不管是多少个节点插入到该DB的数据,记录的ID都是连续单调递增的。而从全局看,因为workerid不一样,多个数据库间的ID又不会重复。像中国的号码是:12345678,美国的号码也是12345678,但国际区号不一样,号码也就不一样。比如这样100-12345678,101-12345678。
有的人设计软件系统时,即使当初设计的是单体系统,为了让以后DB能适应分布式环境,主键不会重复,使用了UUID的字符生成形式,从而牺牲了数字id的优越性能。其实何须这样呢!只需要按本算法设置了记录的ID初值,然后默认让数据库表id主键自增就可以啦。DB表id主键自增不能用在分布式场景――这是之前的一种错误认识。
可以一次取一批ID(即一个范围内的ID一次就可以获取了)。是不是可以取代依赖DB的号段模式呢!!
对于单点问题,提供高可用解决方案。将该算法打包成一个服务替换<依赖DB的号段模式>中的DB即可,服务与服务调用,无数据库IO开销,从而提高了性能。 (但这样就不能连续单调了,但也总比之前的号段模式,要依赖DB好吧!)。
使用国际电话号码作类比说明。只不过是用二进制还看得比较清楚。
国际区号+本国(地区)号码
为什么在一个国家或地区的电话号码不会重复?为什么在国际上一个国家或地区的电话号码还是不会重复?国际区号放在电话号码的最高位部分,只要一国内电话号码不会重复,不同国家用不同的区号,在国际上,电话号码还是不会重复。连续单调递增唯一ID生成算法与这个例子也类似。
绝对全局连续单调递增的DB表主键解决方案??:
绝对全局连续单调递增的方案不存在。如(1,2,3,…10)分到5个DB,则每个库的ID为:
DB1(1,6), DB2(2,7), DB3(3,8), DB4(4,9), DB5(5,10)
或者:
DB1(1,2), DB2(3,4), DB3(5,6), DB4(7,8), DB5(9,10)
要么总体有序,在各个库趋势递增;要么各个库内连续有序,但各部分DB1<DB2<DB3(因为区分DB的区号放在高位)。
绝对连续单调递增,全局唯一的方案,如下:
只能是在新增一个库时,就分配一个库的workerid. 然后在初始化表时,设置初始ID开始用的值,以后由DB自动增长。Workerid的分配可统一放在一个配置文件,由工具检测到某个表是空表,且使用的主键对应的是Java的long型时,设置初始ID开始用的值。
当用作表ID的主键时,可以在表结构创建时,设置不同数据源表主键开始用的ID初值。风险几乎没有,保证100%不重号。
内存生成时,可间隔一定时间(如3分钟)缓存当前ID值到文件,供重启时设置回初值用。新ID初始值=缓存的ID值+间隔时间会生成的ID数量最大值。重启会浪费一个间隔时间生成的ID号。
源码:
https://github.com/automvc/bee/blob/master/src/main/java/org/teasoft/bee/distribution/GenId.java
https://github.com/automvc/honey/blob/master/src/main/java/org/teasoft/honey/distribution/SerialUniqueId.java