yolov4
АйЖШЭјХЬppt:https://pan.baidu.com/s/1lDHreC-iCR9jQ7WyDhx0qA?_at_=1624432312136
ЬсШЁТы:7c28
YOLO-v4ЫуЗЈЪЧдкдгаYOLOФПБъМьВтМмЙЙЕФЛљДЁЩЯ,ВЩгУСЫНќаЉФъCNNСьгђжазюгХауЕФгХЛЏВпТд,ДгЪ§ОнДІРэЁЂжїИЩЭјТчЁЂЭјТчбЕСЗЁЂМЄЛюКЏЪ§ЁЂЫ№ЪЇКЏЪ§ЕШИїИіЗНУцЖМгазХВЛЭЌГЬЖШЕФгХЛЏ,УЛгаРэТлЩЯЕФДДаТЁЃ
ЂйТлЮФжївЊгавдЯТШ§ЕуЙБЯз:
1.ПЊЗЂСЫвЛИіИпаЇЖјЧПДѓЕФФЃаЭ,ЪЙЕУШЮКЮШЫЖМПЩвдЪЙгУвЛеХ1080TiЛђеп2080Ti GPUШЅбЕСЗвЛИіГЌМЖПьЫйКЭОЋШЗЕФФПБъМьВтЦїЁЃ
2.бщжЄСЫвЛЯЕСаstate-of-the-artЕФФПБъМьВтЦїбЕСЗЗНЗЈЕФгАЯьЁЃ
3.аоИФСЫstate-of-the-artЗНЗЈ,ЪЙЕУЫћУЧдкЪЙгУЕЅИіGPUНјаабЕСЗЪБИќМггааЇКЭЪЪХф,АќРЈCBN,PAN,SAMЕШЁЃ
ЂкзїепАббЕСЗЕФЗНЗЈЗжГЩСЫСНРр:
1.Bag of freebies:жЛИФБфбЕСЗВпТдЛђепжЛдіМгбЕСЗГЩБО,БШШчЪ§ОндіЧПЁЃ
2.Bag of specials:ВхМўФЃПщКЭКѓДІРэЗНЗЈ,ЫќУЧНіНідіМгвЛЕуЭЦРэГЩБО,ЕЋЪЧПЩвдМЋДѓЕиЬсЩ§ФПБъМьВтЕФОЋЖШЁЃ
0 еЊвЊ
ФПЧАгаКмЖрПЩвдЬсИпCNNзМШЗадЕФЫуЗЈЁЃетаЉЫуЗЈЕФзщКЯдкХгДѓЪ§ОнМЏЩЯНјааВтЪдЁЂЖдЪЕбщНсЙћНјааРэТлбщжЄЖМЪЧЗЧГЃБивЊЕФЁЃгааЉЫуЗЈжЛдкЬиЖЈЕФФЃаЭЩЯгааЇЙћ,ВЂЧвжЛЖдЬиЖЈЕФЮЪЬтгааЇ,ЛђепжЛЖдаЁЙцФЃЕФЪ§ОнМЏгааЇ;ШЛЖјгааЉЫуЗЈ,БШШчbatch-normalizationКЭresidual-connections,ЖдДѓЖрЪ§ЕФФЃаЭЁЂШЮЮёКЭЪ§ОнМЏЖМЪЪгУЁЃЮвУЧШЯЮЊетбљЭЈгУЕФЫуЗЈАќРЈ:Weighted-Residual-Connections(WRC), Cross-Stage-Partial-connections(CSP), Cross mini-Batch Normalization(CmBN), Self-adversarial-training(SAT)вдМАMish-activationЁЃЮвУЧЪЙгУСЫаТЕФЫуЗЈ:WRC, CSP, CmBN, SAT, Mish activation, Mosaic data augmentation, CmBN, Dropblock regularization?КЭCIoU lossвдМАЫќУЧЕФзщКЯ,ЛёЕУСЫзюгХЕФаЇЙћ:дкMS COCOЪ§ОнМЏЩЯЕФAPжЕЮЊ43.5%(65.7% AP50),дкTesla V100ЩЯЕФЪЕЪБЭЦРэЫйЖШЮЊ65FPSЁЃ

1 НщЩм
ДѓВПЗжЛљгкCNNЕФФПБъМьВтЦїжївЊжЛЪЪгУгкЭЦМіЯЕЭГЁЃОйР§РДЫЕ,ЭЈЙ§ГЧЪаЯрЛњбАевУтЗбЭЃГЕЮЛжУЕФЯЕЭГЪЙгУзХТ§ЫйЕЋЪЧИпОЋЖШЕФФЃаЭ,ШЛЖјЦћГЕХізВОЏИцШДЪЙгУзХПьЫйЕЋЪЧЕЭОЋЖШЕФФЃаЭЁЃЬсИпЪЕЪБФПБъМьВтЦїЕФОЋЖШВЛОФмЙЛгІгУдкЭЦМіЯЕЭГЩЯ,ЖјЧвЛЙФмгУгкЖРСЂЕФСїГЬЙмРэвдМАНЕЕЭШЫдБЪ§СПЩЯЁЃФПЧАДѓВПЗжИпОЋЖШЕФЩёОЭјТчВЛНіВЛФмЪЕЪБдЫаа,ВЂЧвашвЊНЯДѓЕФmini-batch-sizeдкЖрИіGPUsЩЯНјаабЕСЗЁЃЮвУЧЙЙНЈСЫНідквЛПщGPUЩЯОЭПЩвдЪЕЪБдЫааЕФCNNНтОіСЫетИіЮЪЬт,ВЂЧвЫќжЛашвЊдквЛПщGPUЩЯНјаабЕСЗЁЃ

ЮвУЧЙЄзїЕФжївЊФПБъОЭЪЧЩшМЦвЛИіНідкЕЅИіМЦЫуЯЕЭГ(БШШчЕЅИіGPU)ЩЯОЭПЩвдПьЫйдЫааЕФФПБъМьВтЦїВЂЧвЖдВЂааМЦЫуНјаагХЛЏ,ВЂЗЧМѕЕЭМЦСПМЦЫуСПРэТлжИБъ(BFLOP)ЁЃЮвУЧЯЃЭћетИіМьВтЦїФмЙЛЧсЫЩЕФбЕСЗКЭЪЙгУЁЃОпЬхРДЫЕОЭЪЧШЮКЮвЛИіШЫНіНіЪЙгУвЛИіGPUНјаабЕСЗКЭВтЪдОЭПЩвдЕУЕНЪЕЪБЕФ,ИпОЋЖШЕФвдМАСюШЫаХЗўЕФФПБъМьВтНсЙћ,е§ШчдкЭМЦЌ1жаЫљЪОЕФYOLOv4ЕФНсЙћЁЃЮвУЧЕФЙБЯззмНсШчЯТ:
(1)ЮвУЧЬсГіСЫвЛИіИпаЇЧвЧПДѓЕФФПБъМьВтФЃаЭЁЃШЮКЮШЫПЩвдЪЙгУвЛИі1080TiЛђеп2080TiЕФGPUОЭПЩвдбЕСЗГівЛИіПьЫйВЂЧвИпОЋЖШЕФФПБъМьВтЦїЁЃ
(2)ЮвУЧдкМьВтЦїбЕСЗЕФЙ§ГЬжа,ВтЪдСЫФПБъМьВтжазюИпЫЎзМЕФBag-of-FreebiesКЭBat-of-SpecialsЗНЗЈЁЃ
(3)ЮвУЧИФНјСЫзюИпЫЎзМЕФЫуЗЈ,ЪЙЕУЫќУЧИќМгИпаЇВЂЧвЪЪКЯгкдквЛИіGPUЩЯНјаабЕСЗ,БШШчCBN, PAN, SAMЕШЁЃ
2 ЯрЙиЙЄзї
2.1 ФПБъМьВтФЃаЭ
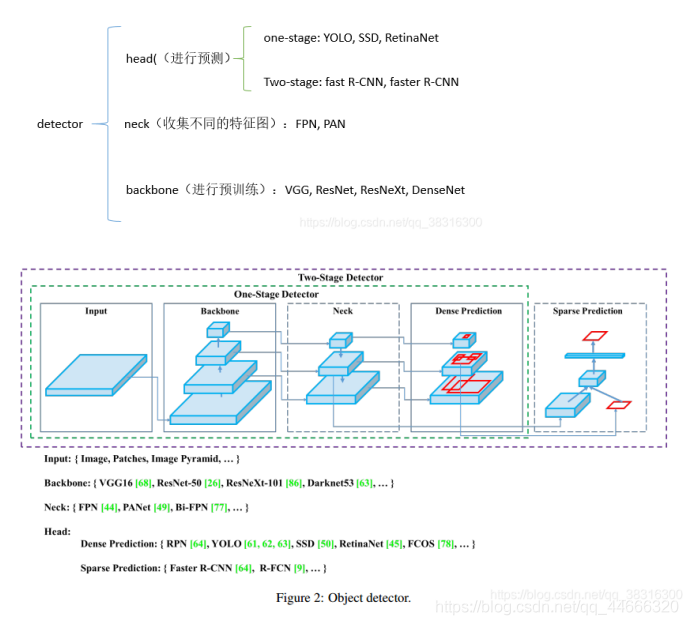
МьВтЦїЭЈГЃгЩСНВПЗжзщГЩ:backboneКЭheadЁЃЧАепдкImageNetЩЯНјаадЄбЕСЗ,КѓепгУРДдЄВтРрБ№аХЯЂКЭФПБъЮяЬхЕФБпНчПђЁЃдкGPUЦНЬЈЩЯдЫааЕФМьВтЦї,ЫќУЧЕФbackboneПЩФмЪЧVGG, ResNet, ResNetXt,ЛђепЪЧDenseNetЁЃдкCPUЦНЬЈЩЯдЫааЕФМьВтЦї,ЫќУЧЕФbackboneПЩФмЪЧSqueezeNet,MobileNetЛђепЪЧShuffleNetЁЃЖдгкheadВПЗж,ЭЈГЃЗжЮЊСНРр:one-stageКЭtwo-stageЕФФПБъМьВтЦїЁЃTwo-stageЕФФПБъМьВтЦїЕФДњБэЪЧR-CNNЯЕСа,АќРЈ:fast R-CNN, faster R-CNN,R-FCNКЭLibra R-CNN. ЛЙгаЛљгкanchor-freeЕФTwo-stageЕФФПБъМьВтЦї,БШШчRepPointsЁЃOne-stageФПБъМьВтЦїЕФДњБэФЃаЭЪЧYOLO, SSDКЭRetinaNetЁЃдкзюНќМИФъ,ГіЯжСЫЛљгкanchor-freeЕФone-stageЕФЫуЗЈ,БШШчCenterNet, CornerNet, FCOSЕШЕШЁЃдкзюНќМИФъ,ФПБъМьВтЦїдкbackboneКЭheadжЎМфЛсВхШывЛаЉЭјТчВу,етаЉЭјТчВуЭЈГЃгУРДЪеМЏВЛЭЌЕФЬиеїЭМЁЃЮвУЧНЋЦфГЦжЎЮЊФПБъМьВтЦїЕФneckЁЃЭЈГЃ,вЛИіneckгЩЖрИіbottom-upТЗОЖКЭtop-downТЗОЖзщГЩЁЃЪЙгУетжжЛњжЦЕФЭјТчАќРЈFeature Pyramid Network(FPN),Path Aggregation Network(PAN),BiFPNКЭNAS-FPNЁЃ

2.2 Bag of freebies
ЭЈГЃРДЫЕ,ФПБъМьВтЦїЖМЪЧНјааРыЯпбЕСЗЕФ(бЕСЗЕФЪБКђЖдGPUЪ§СПКЭЙцИёВЛЯожЦ)ЁЃвђДЫ,баОПепзмЪЧЯВЛЖбяГЄБмЖЬ,ЪЙгУзюКУЕФбЕСЗЪжЖЮ,вђДЫПЩвддкВЛдіМгЭЦРэГЩБОЕФЧщПіЯТ,ЛёЕУзюКУЕФМьВтОЋЖШЁЃЮвУЧНЋжЛИФБфбЕСЗВпТдЛђепжЛдіМгбЕСЗГЩБОЕФЗНЗЈГЦжЎЮЊЁАbag of freebies"ЁЃдкФПБъМьВтжаОГЃЪЙгУВЂЧвТњзуbag of freebiesЕФЖЈвхЕФЫуЗЈГЦЪЧЂйЪ§ОндіЙуЁЃЪ§ОндіЙуЕФФПЕФЪЧдіМгЪфШыЭМЦЌЕФПЩБфад,вђДЫФПБъМьВтФЃаЭЖдДгВЛЭЌГЁОАЯТЛёШЁЕФЭМЦЌгазХИќИпЕФТГАєадЁЃОйР§РДЫЕ,photometric distoitionsКЭgeometric distortionsЪЧгУРДЪ§ОндіЧПЗНЗЈЕФСНИіГЃгУЕФЪжЖЮЁЃдкДІРэphotometric distortionжа,ЮвУЧЛсЕїећЭМЯёЕФССЖШ,ЖдБШЖШ,ЩЋЕї,БЅКЭЖШвдМАдыЩљЁЃЖдгкgeometric distortion,ЮвУЧЛсЫцЛњдіМгГпЖШБфЛЏ,ВУМє,ЗзЊвдМАа§зЊЁЃ
ЩЯУцЬсМАЕФЪ§ОндіЙуЕФЪжЖЮЖМЪЧЯёЫиМЖБ№ЕФЕїећ,ЫќБЃСєСЫЕїећЧјгђЕФЫљгадЪМЯёЫиаХЯЂЁЃДЫЭт,вЛаЉбаОПепНЋЪ§ОндіЙуЕФжиЕуЗХдкСЫЂкФЃФтФПБъЮяЬхекЕВЮЪЬтЩЯЁЃЫћУЧдкЭМЯёЗжРрКЭФПБъМьВтЩЯвбОШЁЕУСЫВЛДэЕФНсЙћЁЃОпЬхРДЫЕ,random eraseКЭCutOutПЩвдЫцЛњбЁдёЭМЯёЩЯЕФОиаЮЧјгђ,ШЛКѓНјааЫцЛњШкКЯЛђепЪЙгУСуЯёЫижЕРДНјааШкКЯЁЃЖдгкhide-and-seekКЭgrid mask,ЫћУЧЫцЛњЕиЛђепОљдШЕидквЛЗљЭМЯёжабЁдёЖрИіОиаЮЧјгђ,ВЂЧвЪЙгУСуРДДњЬцОиаЮЧјгђжаЕФЯёЫижЕЁЃШчЙћНЋЯрЫЦЕФИХФюгУРДЬиеїЭМжа,ГіЯжСЫDropOut, DropConnectКЭDropBlockЗНЗЈЁЃДЫЭт,вЛаЉбаОПепЬсГівЛЦ№ЪЙгУЖреХЭМЯёНјааЪ§ОндіЧПЕФЗНЗЈЁЃОйР§РДЫЕ,MixUpЪЙгУСНеХЭМЦЌНјааЯрГЫВЂЧвЪЙгУВЛЭЌЕФЯЕЪ§БШНјааЕўМг,ШЛКѓЪЙгУЫќУЧЕФЕўМгБШРДЕїећБъЧЉЁЃЖдгкCutMix,ЫќНЋВУМєЕФЭМЦЌИВИЧЕНЦфЫћЭМЦЌЕФОиаЮЧјгђ,ШЛКѓИљОнЛьКЯЧјгђЕФДѓаЁЕїећБъЧЉЁЃГ§СЫЩЯУцЬсМАЕФЗНЗЈ,style transfer GANвВгУРДЪ§ОндіЙу,CNNПЩвдбЇЯАШчКЮгааЇЕФМѕЩйЮЦРэЦЋВюЁЃ
вЛаЉКЭЩЯУцЫљЬсМАЕФВЛЭЌЕФЗНЗЈгУРДНтОіЪ§ОнМЏжаЕФгявхЗжВМПЩФмДцдкЦЋВюЕФЮЪЬтЁЃДІРэгявхЗжВМЦЋВюЕФЮЪЬт,вЛИіЗЧГЃживЊЕФЮЪЬтОЭЪЧдкВЛЭЌРрБ№жЎМфДцдкЪ§ОнВЛЦНКт,ВЂЧветИіЮЪЬтдкtwo-stageФПБъМьВтЦїжа,ЭЈГЃЪЙгУhard negative example miningЛђепonline hard example miningРДНтОіЁЃЕЋЪЧexample mining ЗНЗЈВЂВЛЪЪгУгкone-stageЕФФПБъМьВтЦї,вђЮЊетжжРраЭЕФМьВтЦїЪєгкdense predictionМмЙЙЁЃвђДЫfocal lossЫуЗЈгУРДНтОіВЛЭЌРрБ№жЎМфЪ§ОнВЛОљКтЕФЮЪЬтЁЃЂлСэЭтвЛИіЗЧГЃживЊЕФЮЪЬтОЭЪЧЪЙгУone-hotКмФбУшЪіВЛЭЌРрБ№жЎМфЙиСЊЖШЕФЙиЯЕЁЃLabel smothingЬсГідкбЕСЗЕФЪБКђ,НЋhard labelзЊЛЛГЩsoft label,етИіЗНЗЈПЩвдЪЙЕУФЃаЭИќМгЕФТГАєадЁЃЮЊСЫЕУЕНвЛИізюКУЕФsoft label, Islamв§ШыСЫжЊЪЖеєСѓЕФИХФюРДЩшМЦБъЧЉЯИЛЏЭјТчЁЃ


дкЩюЖШбЇЯАЕФбаОПжа,вЛаЉШЫжиЕуЙиаФШЅбАеввЛИігХауЕФМЄЛюКЏЪ§ЁЃвЛИігХауЕФМЄЛюКЏЪ§ПЩвдШУЬнЖШИќгааЇЕФНјааДЋВЅ,гыДЫЭЌЪБЫќВЛЛсдіМгЖюЭтЕФМЦЫуСПЁЃдк2010Фъ,NairКЭHintonЬсГіСЫReLUМЄЛюКЏЪ§ГфЗжЕиНтОіСЫЬнЖШЯћЪЇЕФЮЪЬт,етИіЮЪЬтдкДЋЭГЕФtanhКЭsigmoidМЄЛюКЏЪ§жаЛсОГЃгіЕНЁЃЫцКѓ,LReLU,PReLU,ReLU6,Scaled Exponential Linear?Unit(SELU),Swish,?hard-SwishКЭMishЕШЕШЯрМЬЬсГі,ЫќУЧвВгУРДНтОіЬнЖШЯћЪЇЕФЮЪЬтЁЃLReLUКЭPReLUжївЊгУРДНтОіЕБЪфГіаЁгкСуЕФЪБКђ,ReLUЕФЬнЖШЮЊСуЕФЮЪЬтЁЃReLU6КЭhard-SwishжївЊЮЊСПЛЏЭјТчЖјЩшМЦЁЃЖдгкЩёОЭјТчЕФздЙщвЛЛЏ,ЬсГіSELUМЄЛюКЏЪ§ШЅЪЕЯжетИіФПЕФЁЃашвЊзЂвтЕФЪЧSwishКЭMishЖМЪЧСЌајПЩЕМЕФМЄЛюКЏЪ§ЁЃ

3 ЗНЗЈ
ЮвУЧЙЄзїЛљБОЕФФПБъОЭЪЧдкЩњВњЯЕЭГКЭгХЛЏВЂаадЄЫужаМгПьЩёОЭјТчЕФЫйЖШ,ЖјЗЧНЕЕЭМЦЫуСПРэТлжИБъ(BFLOP)ЁЃЮвУЧЬсЙЉСЫСНИіЪЕЪБЩёОЭјТчЕФбЁдё:
(1)GPU дкОэЛ§Вужа,ЮвУЧЪЙгУЩйСПЕФзщ(1-8): CSPResNeXt50 / CSPDarknet53;
(2)VPU ЮвУЧЪЙгУЗжзщОэЛ§,ЕЋЪЧЮвУЧВЛЪЙгУSqueeze-and-excitement(SE)ФЃПщ,ОпЬхАќРЈвдЯТФЃаЭ:EfficientNet-lite / MixNet / GhostNet / MobileNetV3ЁЃ
3.1 ЭјТчМмЙЙЕФбЁдё

3.3 ЖюЭтЕФИФНј
ЮЊСЫШУМьВтЦїИќЪЪКЯдкЕЅИіGPUЩЯНјаабЕСЗ,ЮвУЧзіСЫвдЯТЖюЭтЕФЩшМЦКЭИФНј:
(1)ЮвУЧЬсГіСЫЪ§ОндіЙуЕФаТЕФЗНЗЈ:MosaicКЭSelf-Adversarial?Training(SAT);
(2)дкгІгУвХДЋЫуЗЈШЅбЁдёзюгХЕФГЌВЮЪ§;
(3)ЮвУЧИФНјСЫвЛаЉЯжгаЕФЫуЗЈ,ШУЮвУЧЕФЩшМЦИќЪЪКЯИпаЇЕФбЕСЗКЭМьВт - ИФНјSAM, ИФНјPANвдМАCross mini-Batch Normalization(CmBN);
здЪЪгІЖдПЙбЕСЗ(SAT)вВБэЪОСЫвЛИіаТЕФЪ§ОндіЙуЕФММЧЩ,ЫќдкЧАКѓСННзЖЮЩЯНјааВйзїЁЃдкЕквЛНзЖЮ,ЩёОЭјТчДњЬцдЪМЕФЭМЦЌЖјЗЧЭјТчЕФШЈжиЁЃгУетжжЗНЪН,ЩёОЭјТчздМКНјааЖдПЙбЕСЗ,ДњЬцдЪМЕФЭМЦЌШЅДДНЈЭМЦЌжаДЫДІУЛгаЦкЭћЮяЬхЕФУшЪіЁЃдкЕкЖўНзЖЮ,ЩёОЭјТчЪЙгУГЃЙцЕФЗНЗЈНјаабЕСЗ,дкаоИФжЎКѓЕФЭМЦЌЩЯМьВтЮяЬхЁЃ
3.4 YOLOv4

6 НсТл
ЮвУЧЬсГіСЫвЛИізюЯШНјЕФФПБъМьВтЦї,ЫќБШЫљгаМьВтЦїЖМвЊПьЖјЧвИќзМШЗЁЃетИіМьВтЦїПЩвдНідквЛПщ8-16GBЕФGPUЩЯНјаабЕСЗ,етЪЙЕУЫќПЩвдЙуЗКЕФЪЙгУЁЃOne-stageЕФanchor-basedЕФМьВтЦїЕФдЪМИХФюжЄУїЪЧПЩааЕФЁЃЮвУЧвбОбщжЄСЫДѓСПЕФЬиеї,ВЂЧвЦфгУгкЬсИпЗжРрЦїКЭМьВтЦїЕФОЋЖШЁЃетаЉЫуЗЈПЩвдзїЮЊЮДРДбаОПКЭЗЂеЙЕФзюМбЪЕМљЁЃ
ЛљБОзщМў
ЩЯЭМШ§ИіРЖЩЋЗНПђФкБэЪОYolov3ЕФШ§ИіЛљБОзщМў:
CBL:Yolov3ЭјТчНсЙЙжаЕФзюаЁзщМў,гЩConv+Bn+Leaky_reluМЄЛюКЏЪ§Ш§епзщГЩЁЃ
Res unit:НшМјResnetЭјТчжаЕФВаВюНсЙЙ,ШУЭјТчПЩвдЙЙНЈЕФИќЩюЁЃ
ResX:гЩвЛИіCBLКЭXИіВаВюзщМўЙЙГЩ,ЪЧYolov3жаЕФДѓзщМўЁЃУПИіResФЃПщЧАУцЕФCBLЖМЦ№ЕНЯТВЩбљЕФзїгУ,вђДЫОЙ§5ДЮResФЃПщКѓ,ЕУЕНЕФЬиеїЭМЪЧ608->304->152->76->38->19ДѓаЁЁЃ
ЦфЫћЛљДЁВйзї
Concat:еХСПЦДНг,ЛсРЉГфСНИіеХСПЕФЮЌЖШ,Р§Шч2626256КЭ2626512СНИіеХСПЦДНг,НсЙћЪЧ2626768ЁЃConcatКЭcfgЮФМўжаЕФrouteЙІФмвЛбљЁЃ
add:еХСПЯрМг,еХСПжБНгЯрМг,ВЛЛсРЉГфЮЌЖШ,Р§Шч104104128КЭ104104128ЯрМг,НсЙћЛЙЪЧ104104128ЁЃaddКЭcfgЮФМўжаЕФshortcutЙІФмвЛбљЁЃ
BackboneжаОэЛ§ВуЕФЪ§СП
УПИіResXжаАќКЌ1+2xXИіОэЛ§Ву,вђДЫећИіжїИЩЭјТчBackboneжавЛЙВАќКЌ1+(1+2x1)+(1+2x2)+(1+2x8)+(1+2x8)+(1+2x4)=52,дйМгЩЯвЛИіFCШЋСЌНгВу,МДПЩвдзщГЩвЛИіDarknet53ЗжРрЭјТчЁЃВЛЙ§дкФПБъМьВтYolov3жа,ШЅЕєFCВу,ВЛЙ§ЮЊСЫЗНБуГЦКє,ШдШЛАбYolov3ЕФжїИЩЭјТчНазіDarknet53НсЙЙЁЃ
ЭјТчНсЙЙЯъЯИПЩЪгЛЏ
ШчЯТЭМвд416x416x3ЪфШыЮЊР§

YoloV4ЕФ4ИіДДаТВПЗжзмЪі
ЪфШыЖЫ:етРяжИЕФДДаТжївЊЪЧбЕСЗЪБЖдЪфШыЖЫЕФИФНј,жївЊАќРЈMosaicЪ§ОндіЧПЁЂcmBNЁЂSATздЖдПЙбЕСЗ;
BackBoneжїИЩЭјТч:НЋИїжжаТЕФЗНЪННсКЯЦ№РД,АќРЈ:CSPDarknet53ЁЂMishМЄЛюКЏЪ§ЁЂDropblock;
Neck:ФПБъМьВтЭјТчдкBackBoneКЭзюКѓЕФЪфГіВужЎМфЭљЭљЛсВхШывЛаЉВу,БШШчYolov4жаЕФSPPФЃПщЁЂFPN+PANНсЙЙ;
Prediction:ЪфГіВуЕФУЊПђЛњжЦКЭYolov3ЯрЭЌ,жївЊИФНјЕФЪЧбЕСЗЪБЕФЫ№ЪЇКЏЪ§CIOU_Loss,вдМАдЄВтПђЩИбЁЕФnmsБфЮЊDIOU_nmsЁЃ
?
?
ВЮПМЮФЯз,ФкШнРДдДгквЛЯТВЮПМЮФЯз,НізїЮЊБОШЫбЇЯАМЧТМ!
https://zhuanlan.zhihu.com/p/137393450
https://blog.csdn.net/qq_38316300/article/details/105759305
https://blog.csdn.net/andyjkt/article/details/107590669
https://www.cnblogs.com/icetree/p/13111746.html
?
?