简介
feapder 是一款上手简单,功能强大的Python爬虫框架,使用方式类似scrapy,方便由scrapy框架切换过来,框架内置3种爬虫:
- AirSpider爬虫比较轻量,学习成本低。面对一些数据量较少,无需断点续爬,无需分布式采集的需求,可采用此爬虫。
- Spider是一款基于redis的分布式爬虫,适用于海量数据采集,支持断点续爬、爬虫报警、数据自动入库等功能
- BatchSpider是一款分布式批次爬虫,对于需要周期性采集的数据,优先考虑使用本爬虫。
feapder除了支持断点续爬、数据防丢、监控报警外,还支持浏览器渲染下载,自定义入库pipeline,方便对接其他数据库(默认数据库为Mysql,数据可自动入库,无需编写pipeline)
读音: [ˈfiːpdə]
- 官方文档:http://feapder.com
- 国内文档:https://boris-code.gitee.io/feapder
- github:https://github.com/Boris-code/feapder
- 更新日志:https://github.com/Boris-code/feapder/releases
环境要求:
- Python 3.6.0+
- Works on Linux, Windows, macOS
安装
From PyPi:
通用版
完整版:
pip3 install feapder[all]
通用版与完整版区别:
完整版支持基于内存去重
完整版可能会安装出错,若安装出错,请参考安装问题
小试一下
创建爬虫
feapder create -s first_spider
创建后的爬虫代码如下:
import feapder
class FirstSpider(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("https://www.baidu.com")
def parse(self, request, response):
print(response)
if __name__ == "__main__":
FirstSpider().start()
直接运行,打印如下:
Thread-2|2021-02-09 14:55:11,373|request.py|get_response|line:283|DEBUG|
-------------- FirstSpider.parse request for ----------------
url = https://www.baidu.com
method = GET
body = {'timeout': 22, 'stream': True, 'verify': False, 'headers': {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36'}}
<Response [200]>
Thread-2|2021-02-09 14:55:11,610|parser_control.py|run|line:415|DEBUG| parser 等待任务 ...
FirstSpider|2021-02-09 14:55:14,620|air_spider.py|run|line:80|INFO| 无任务,爬虫结束
代码解释如下:
- start_requests: 生产任务
- parse: 解析数据
将请求头转为json格式
爬虫采集中,我们经常需要携带网站的header等参数,比如:我们在浏览器检查工具看到某请求头为:
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cache-Control: max-age=0
Connection: keep-alive
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36
如果我们想在发请求时携带这个header,那么需要手动将其转为json格式。
使用
输入命令,回车
> feapder create -j
请输入需要转换的内容:(xxx:xxx格式,支持多行)

输出如下:
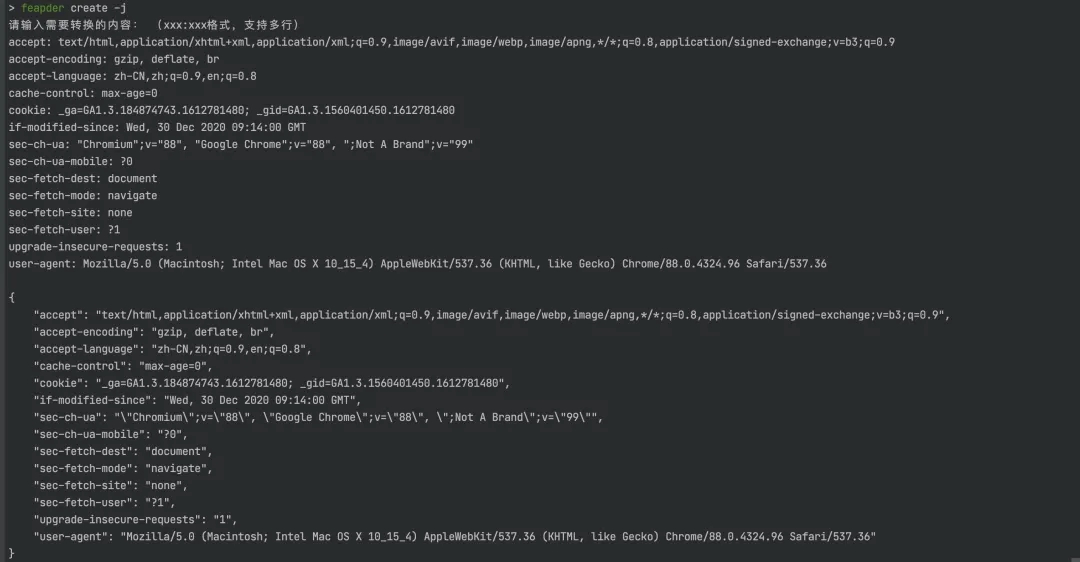
另外,feapder还支持创建有序字典,方便对比参数前后的变化
命令为:
js