cookie1,2021-06-10 10:00:02,url2
cookie1,2021-06-10 10:00:00,url1
cookie1,2021-06-10 10:03:04,1url3
cookie1,2021-06-10 10:50:05,url6
cookie1,2021-06-10 11:00:00,url7
cookie1,2021-06-10 10:10:00,url4
cookie1,2021-06-10 10:50:01,url5
cookie2,2021-06-10 10:00:02,url22
cookie2,2021-06-10 10:00:00,url11
cookie2,2021-06-10 10:03:04,1url33
cookie2,2021-06-10 10:50:05,url66
cookie2,2021-06-10 11:00:00,url77
cookie2,2021-06-10 10:10:00,url44
cookie2,2021-06-10 10:50:01,url55
LAG(col,n,DEFAULT) гУгкЭГМЦДАПкФкЭљЩЯЕкnаажЕЁЃ
ЕквЛИіВЮЪ§ЮЊСаУћЃЌЕкЖўИіВЮЪ§ЮЊЭљЩЯЕкnааЃЈПЩбЁЃЌФЌШЯЮЊ1ЃЉЃЌЕкШ§ИіВЮЪ§ЮЊФЌШЯжЕЃЈЕБЭљЩЯЕкnааЮЊNULLЪБКђЃЌШЁФЌШЯжЕЃЌШчВЛжИЖЈЃЌдђЮЊNULLЃЉ
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAG(createtime,1,'1970-01-01 00:00:00') OVER(PARTITION BY cookieid ORDER BY createtime) AS last_1_time,
LAG(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS last_2_time
FROM user_url;
НсЙћШчЯТЃК

НтЪЭЃК
last_1_time: жИЖЈСЫЭљЩЯЕк1ааЕФжЕЃЌdefaultЮЊ'1970-01-01 00:00:00'
cookie1ЕквЛааЃЌЭљЩЯ1ааЮЊNULL,вђДЫШЁФЌШЯжЕ 1970-01-01 00:00:00
cookie1ЕкШ§ааЃЌЭљЩЯ1аажЕЮЊЕкЖўаажЕЃЌ2021-06-10 10:00:02
cookie1ЕкСљааЃЌЭљЩЯ1аажЕЮЊЕкЮхаажЕЃЌ2021-06-10 10:50:01
last_2_time: жИЖЈСЫЭљЩЯЕк2ааЕФжЕЃЌЮЊжИЖЈФЌШЯжЕ
cookie1ЕквЛааЃЌЭљЩЯ2ааЮЊNULL
cookie1ЕкЖўааЃЌЭљЩЯ2ааЮЊNULL
cookie1ЕкЫФааЃЌЭљЩЯ2ааЮЊЕкЖўаажЕЃЌ2021-06-10 10:00:02
cookie1ЕкЦпааЃЌЭљЩЯ2ааЮЊЕкЮхаажЕЃЌ2021-06-10 10:50:01
гыLAGЯрЗД
LEAD(col,n,DEFAULT) гУгкЭГМЦДАПкФкЭљЯТЕкnаажЕЁЃ
ЕквЛИіВЮЪ§ЮЊСаУћЃЌЕкЖўИіВЮЪ§ЮЊЭљЯТЕкnааЃЈПЩбЁЃЌФЌШЯЮЊ1ЃЉЃЌЕкШ§ИіВЮЪ§ЮЊФЌШЯжЕЃЈЕБЭљЯТЕкnааЮЊNULLЪБКђЃЌШЁФЌШЯжЕЃЌШчВЛжИЖЈЃЌдђЮЊNULLЃЉ
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LEAD(createtime,1,'1970-01-01 00:00:00') OVER(PARTITION BY cookieid ORDER BY createtime) AS next_1_time,
LEAD(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS next_2_time
FROM user_url;
НсЙћШчЯТЃК

ШЁЗжзщФкХХађКѓЃЌНижЙЕНЕБЧАааЃЌЕквЛИіжЕЁЃ
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
FIRST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS first1
FROM user_url;
НсЙћШчЯТЃК

ШЁЗжзщФкХХађКѓЃЌНижЙЕНЕБЧАааЃЌзюКѓвЛИіжЕЁЃ
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS last1
FROM user_url;
НсЙћШчЯТЃК

ШчЙћЯывЊШЁЗжзщФкХХађКѓзюКѓвЛИіжЕЃЌдђашвЊБфЭЈвЛЯТЃК
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS last1,
FIRST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime DESC) AS last2
FROM user_url
ORDER BY cookieid,createtime;
зЂвтЩЯЪіSQLЃЌЪЙгУЕФЪЧ FIRST_VALUE ЕФЕЙађШЁГіЗжзщФкХХађзюКѓвЛИіжЕЃЁ
НсЙћШчЯТЃК

ДЫДІвЊЬиБ№зЂвтorder by
ШчЙћВЛжИЖЈORDER BYЃЌдђНјааХХађЛьТвЃЌЛсГіЯжДэЮѓЕФНсЙћ
SELECT cookieid,
createtime,
url,
FIRST_VALUE(url) OVER(PARTITION BY cookieid) AS first2
FROM user_url;
НсЙћШчЯТЃК
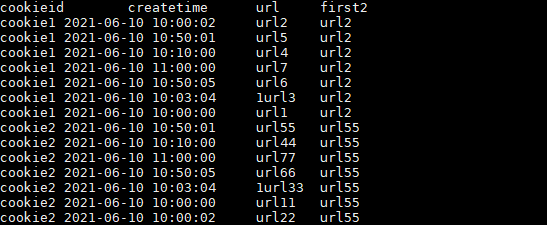
ЩЯЪі url2 КЭ url55 ЕФcreatetimeМДВЛЪєгкзюППЧАЕФЪБМфвВВЛЪєгкзюППКѓЕФЪБМфЃЌЫљвдНсЙћЪЧЛьТвЕФЁЃ
4. CUME_DIST
ЯШДДНЈвЛеХдБЙЄаНЫЎБэЃКstaff_salary
CREATE EXTERNAL TABLE staff_salary (
dept string,
userid string,
sal int
);
БэжаМгШыШчЯТЪ§ОнЃК
d1,user1,1000
d1,user2,2000
d1,user3,3000
d2,user4,4000
d2,user5,5000
ДЫКЏЪ§ЕФНсЙћКЭorder byЕФХХађЫГађгаЙиЯЕЁЃ
CUME_DISTЃКаЁгкЕШгкЕБЧАжЕЕФааЪ§/ЗжзщФкзмааЪ§ЁЃ orderФЌШЯЫГађ
ЃКе§ађ
БШШчЃЌЭГМЦаЁгкЕШгкЕБЧАаНЫЎЕФШЫЪ§ЃЌЫљеМзмШЫЪ§ЕФБШР§ЁЃ
SELECT
dept,
userid,
sal,
CUME_DIST() OVER(ORDER BY sal) AS rn1,
CUME_DIST() OVER(PARTITION BY dept ORDER BY sal) AS rn2
FROM staff_salary;
НсЙћШчЯТЃК

НтЪЭЃК
rn1: УЛгаpartition,ЫљгаЪ§ОнОљЮЊ1зщЃЌзмааЪ§ЮЊ5ЃЌ
ЕквЛааЃКаЁгкЕШгк1000ЕФааЪ§ЮЊ1ЃЌвђДЫЃЌ1/5=0.2
ЕкШ§ааЃКаЁгкЕШгк3000ЕФааЪ§ЮЊ3ЃЌвђДЫЃЌ3/5=0.6
rn2: АДееВПУХЗжзщЃЌdpet=d1ЕФааЪ§ЮЊ3,
ЕкЖўааЃКаЁгкЕШгк2000ЕФааЪ§ЮЊ2ЃЌвђДЫЃЌ2/3=0.6666666666666666
5. GROUPING SETSЁЂGROUPING__IDЁЂCUBEЁЂROLLUP
етМИИіЗжЮіКЏЪ§ЭЈГЃгУгкOLAPжаЃЌВЛФмРлМгЃЌЖјЧвашвЊИљОнВЛЭЌЮЌЖШЩЯзъКЭЯТзъЕФжИБъЭГМЦЃЌБШШчЃЌЗжаЁЪБЁЂЬьЁЂдТЕФUVЪ§ЁЃ
ЛЙЪЧЯШДДНЈвЛИігУЛЇЗУЮЪБэЃКuser_date
CREATE TABLE user_date (
month STRING,
day STRING,
cookieid STRING
);
БэжаМгШыШчЯТЪ§ОнЃК
2021-03,2021-03-10,cookie1
2021-03,2021-03-10,cookie5
2021-03,2021-03-12,cookie7
2021-04,2021-04-12,cookie3
2021-04,2021-04-13,cookie2
2021-04,2021-04-13,cookie4
2021-04,2021-04-16,cookie4
2021-03,2021-03-10,cookie2
2021-03,2021-03-10,cookie3
2021-04,2021-04-12,cookie5
2021-04,2021-04-13,cookie6
2021-04,2021-04-15,cookie3
2021-04,2021-04-15,cookie2
2021-04,2021-04-16,cookie1
grouping setsЪЧвЛжжНЋЖрИіgroup by ТпМаДдквЛИіsqlгяОфжаЕФБуРћаДЗЈЁЃ
ЕШМлгкНЋВЛЭЌЮЌЖШЕФGROUP BYНсЙћМЏНјааUNION ALLЁЃ
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM user_date
GROUP BY month,day
GROUPING SETS (month,day)
ORDER BY GROUPING__ID;
зЂЃКЩЯЪіSQLжаЕФGROUPING__IDЃЌЪЧИіЙиМќзжЃЌБэЪОНсЙћЪєгкФФвЛИіЗжзщМЏКЯЃЌИљОнgrouping setsжаЕФЗжзщЬѕМўmonthЃЌdayЃЌ1ЪЧДњБэmonthЃЌ2ЪЧДњБэdayЁЃ
НсЙћШчЯТЃК

ЩЯЪіSQLЕШМлгкЃК
SELECT month,
NULL as day,
COUNT(DISTINCT cookieid) AS uv,
1 AS GROUPING__ID
FROM user_date
GROUP BY month
UNION ALL
SELECT NULL as month,
day,
COUNT(DISTINCT cookieid) AS uv,
2 AS GROUPING__ID
FROM user_date
GROUP BY day;
ИљОнGROUP BYЕФЮЌЖШЕФЫљгазщКЯНјааОлКЯЁЃ
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM user_date
GROUP BY month,day
WITH CUBE
ORDER BY GROUPING__ID;
НсЙћШчЯТЃК

ЩЯЪіSQLЕШМлгкЃК
SELECT NULL,NULL,COUNT(DISTINCT cookieid) AS uv,0 AS GROUPING__ID FROM user_date
UNION ALL
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM user_date GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM user_date GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__ID FROM user_date GROUP BY month,day;
ЪЧCUBEЕФзгМЏЃЌвдзюзѓВрЕФЮЌЖШЮЊжїЃЌДгИУЮЌЖШНјааВуМЖОлКЯЁЃ
БШШчЃЌвдmonthЮЌЖШНјааВуМЖОлКЯЃК
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM user_date
GROUP BY month,day
WITH ROLLUP
ORDER BY GROUPING__ID;
НсЙћШчЯТЃК

АбmonthКЭdayЕїЛЛЫГађЃЌдђвдdayЮЌЖШНјааВуМЖОлКЯЃК
SELECT
day,
month,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM user_date
GROUP BY day,month
WITH ROLLUP
ORDER BY GROUPING__ID;
НсЙћШчЯТЃК

етРяЃЌИљОнШеКЭдТНјааОлКЯЃЌКЭИљОнШеОлКЯНсЙћвЛбљЃЌвђЮЊгаИИзгЙиЯЕЃЌШчЙћЪЧЦфЫћЮЌЖШзщКЯЕФЛАЃЌОЭЛсВЛвЛбљЁЃ
ДАПкКЏЪ§ЪЕМЪгІгУ
1. ЕкЖўИпЕФаНЫЎ
ФбЖШМђЕЅЁЃ
БраДвЛИі SQL ВщбЏЃЌЛёШЁ Employee БэжаЕкЖўИпЕФаНЫЎЃЈSalaryЃЉЁЃ
+----+--------+
| Id | Salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
Р§ШчЩЯЪі Employee БэЃЌSQLВщбЏгІИУЗЕЛи 200 зїЮЊЕкЖўИпЕФаНЫЎЁЃШчЙћВЛДцдкЕкЖўИпЕФаНЫЎЃЌФЧУДВщбЏгІЗЕЛи nullЁЃ
+---------------------+
| SecondHighestSalary |
+---------------------+
| 200 |
+---------------------+
етЕРЬтПЩвдгУ row_number КЏЪ§НтОіЁЃ
ВЮПМДњТыЃК
SELECT
*
FROM(
SELECT Salary, row_number() over(order by Salary desc) rk
FROM Employee
) t WHERE t.rk = 2;
ИќМђЕЅЕФДњТыЃК
SELECT DISTINCT Salary
FROM Employee
ORDER BY Salary DESC
LIMIT 1 OFFSET 1
OFFSETЃКЦЋвЦСПЃЌБэЪОДгЕкМИЬѕЪ§ОнПЊЪМШЁЃЌ0ДњБэЕк1ЬѕЪ§ОнЁЃ
2. ЗжЪ§ХХУћ
ФбЖШМђЕЅЁЃ
БраДвЛИі SQL ВщбЏРДЪЕЯжЗжЪ§ХХУћЁЃ
ШчЙћСНИіЗжЪ§ЯрЭЌЃЌдђСНИіЗжЪ§ХХУћЃЈRankЃЉЯрЭЌЁЃЧызЂвтЃЌЦНЗжКѓЕФЯТвЛИіУћДЮгІИУЪЧЯТвЛИіСЌајЕФећЪ§жЕЁЃЛЛОфЛАЫЕЃЌУћДЮжЎМфВЛгІИУгаЁАМфИєЁБЁЃ
+----+-------+
| Id | Score |
+----+-------+
| 1 | 3.50 |
| 2 | 3.65 |
| 3 | 4.00 |
| 4 | 3.85 |
| 5 | 4.00 |
| 6 | 3.65 |
+----+-------+
Р§ШчЃЌИљОнЩЯЪіИјЖЈЕФ Scores БэЃЌФуЕФВщбЏгІИУЗЕЛиЃЈАДЗжЪ§ДгИпЕНЕЭХХСаЃЉЃК
+-------+------+
| Score | Rank |
+-------+------+
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 2 |
| 3.65 | 3 |
| 3.65 | 3 |
| 3.50 | 4 |
+-------+------+
ВЮПМДњТыЃК
SELECT Score,
dense_rank() over(order by Score desc) as `Rank`
FROM Scores;
3. СЌајГіЯжЕФЪ§зж
ФбЖШжаЕШЁЃ
БраДвЛИі SQL ВщбЏЃЌВщевЫљгажСЩйСЌајГіЯжШ§ДЮЕФЪ§зжЁЃ
+----+-----+
| Id | Num |
+----+-----+
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 1 |
| 6 | 2 |
| 7 | 2 |
+----+-----+
Р§ШчЃЌИјЖЈЩЯУцЕФ Logs БэЃЌ 1 ЪЧЮЈвЛСЌајГіЯжжСЩйШ§ДЮЕФЪ§зжЁЃ
+-----------------+
| ConsecutiveNums |
+-----------------+
| 1 |
+-----------------+
ВЮПМДњТыЃК
SELECT DISTINCT `Num` as ConsecutiveNums
FROM
(
SELECT Num,
lead(Num, 1, null) over(order by id) n2,
lead(Num, 2, null) over(order by id) n3
FROM Logs
) t1
WHERE Num = n2 and Num = n3
4. СЌајNЬьЕЧТМ
ФбЖШРЇФбЁЃ
аДвЛИі SQL ВщбЏ, евЕНЛюдОгУЛЇЕФ id КЭ nameЃЌЛюдОгУЛЇЪЧжИФЧаЉжСЩйСЌај 5 ЬьЕЧТМеЫЛЇЕФгУЛЇЃЌЗЕЛиЕФНсЙћБэАДее id ХХађЁЃ
Бэ AccountsЃК
+----+-----------+
| id | name |
+----+-----------+
| 1 | Winston |
| 7 | Jonathan |
+----+-----------+
Бэ LoginsЃК
+----+-------------+
| id | login_date |
+----+-------------+
| 7 | 2020-05-30 |
| 1 | 2020-05-30 |
| 7 | 2020-05-31 |
| 7 | 2020-06-01 |
| 7 | 2020-06-02 |
| 7 | 2020-06-02 |
| 7 | 2020-06-03 |
| 1 | 2020-06-07 |
| 7 | 2020-06-10 |
+----+-------------+
Р§ШчЃЌИјЖЈЩЯУцЕФAccountsКЭLoginsБэЃЌжСЩйСЌај 5 ЬьЕЧТМеЫЛЇЕФЪЧid=7ЕФгУЛЇ
+----+-----------+
| id | name |
+----+-----------+
| 7 | Jonathan |
+----+-----------+
ЫМТЗЃК
- ШЅжиЃКгЩгкУПИіШЫПЩФмвЛЬьПЩФмВЛжЙЕЧТНвЛДЮЃЌашвЊШЅжи
- ХХађЃКЖдУПИіIDЕФЕЧТМШеЦкХХађ
- ВюжЕЃКМЦЫуЕЧТМШеЦкгыХХађжЎМфЕФВюжЕЃЌевЕНСЌајЕЧТНЕФМЧТМ
- СЌајЕЧТМЬьЪ§МЦЫуЃКselect id, count(*) group by id, ВюжЕЃЈЮБДњТыЃЉ
- ШЁГіЕЧТМ5ЬьвдЩЯЕФМЧТМ
- ЭЈЙ§БэКЯВЂЃЌШЁГіidЖдгІгУЛЇУћ
ВЮПМДњТыЃК
SELECT DISTINCT b.id, name
FROM
(SELECT id, login_date,
DATE_SUB(login_date, ROW_NUMBER() OVER(PARTITION BY id ORDER BY login_date)) AS diff
FROM(SELECT DISTINCT id, login_date FROM Logins) a) b
INNER JOIN Accounts ac
ON b.id = ac.id
GROUP BY b.id, diff
HAVING COUNT(b.id) >= 5
зЂвтЕуЃК
- DATE_SUBЕФгІгУЃКDATE_SUB (DATE, X)ЃЌзЂвтЃЌXЮЊе§Ъ§БэЪОЕБЧАШеЦкЕФЧАXЬьЃЛ
- ШчКЮевСЌајШеЦкЃКЭЈЙ§ХХађгыЕЧТМШеЦкжЎМфЕФВюжЕЃЌвђЮЊХХађСЌајЃЌвђДЫШєЕЧТМШеЦкСЌајЃЌдђВюжЕвЛжТЃЛ
- GROUP BYКЭHAVINGЕФгІгУЃКЭЈЙ§idКЭВюжЕЕФGROUP BYЃЌгУCOUNTевЕНСЌајЬьЪ§Дѓгк5ЬьЕФidЃЌзЂвтCOUNTВЛЪЧвЛЖЈвЊГіЯждкSELECTКѓЃЌПЩвджБНггУдкHAVINGжа
5. ИјЖЈЪ§зжЕФЦЕТЪВщбЏжаЮЛЪ§
ФбЖШРЇФбЁЃ
Numbers БэБЃДцЪ§зжЕФжЕМАЦфЦЕТЪЁЃ
+----------+-------------+
| Number | Frequency |
+----------+-------------|
| 0 | 7 |
| 1 | 1 |
| 2 | 3 |
| 3 | 1 |
+----------+-------------+
дкДЫБэжаЃЌЪ§зжЮЊ 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 3ЃЌЫљвджаЮЛЪ§ЪЧ (0 + 0) / 2 = 0ЁЃ
+--------+
| median |
+--------|
| 0.0000 |
+--------+
ЧыБраДвЛИіВщбЏРДВщевЫљгаЪ§зжЕФжаЮЛЪ§ВЂНЋНсЙћУќУћЮЊ median ЁЃ
ВЮПМДњТыЃК
select
avg(cast(number as float)) as median
from
(
select Number,
Frequency,
sum(Frequency) over(order by Number) - Frequency as prev_sum,
sum(Frequency) over(order by Number) as curr_sum
from Numbers
) t1, (
select sum(Frequency) as total_sum
from Numbers
) t2
where
t1.prev_sum <= (cast(t2.total_sum as float) / 2)
and
t1.curr_sum >= (cast(t2.total_sum as float) / 2)
bk




