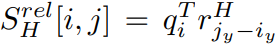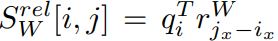ע��������֮Attention Augmented Convolutional Networks
ԭʼ���ӣ�https://www.yuque.com/lart/papers/aaconv

��������
We propose to augment convolutional operators with this self-attention mechanism by concatenating convolutional feature maps with a set of feature maps produced via self-attention.
��Ҫ����
�����˽��������������������:
- �ֲ���:locality via a limited receptive field
- �ȱ���:translation equivariance via weight sharing
- The Convolution Operator is Translation Equivariant meaning it preserves Translations however the CNN processing allows for Translation Invariance which is achieved by means of a proper (i.e. related to spatial features) dimensionality reduction. https://aboveintelligent.com/ml-cnn-translation-equivariance-and-invariance-da12e8ab7049
- While convolutions are translation equivariant and not invariant, an approximative translation invariance can be achieved in neural networks by combining convolutions with spatial pooling operators. https://chriswolfvision.medium.com/what-is-translation-equivariance-and-why-do-we-use-convolutions-to-get-it-6f18139d4c59
������Щ���Ա�֤�����������ͼ���ϲ�����ģ��ʱ������Ҫ�Ĺ���ƫ��(inductive biase). ���Ǿ����ľֲ�����(the local nature of the convolutional kernel)�谭���䲶��ȫ�ֵ���������Ϣ(global context), ����Щ��Ϣ����ͼ��ʶ���Ǻܱ�Ҫ��. ���Ǿ�������Ҫ������. (convolution operator is limited by its locality and lack of understandingof global contexts)
���ڲ����뽻����ϵ(long range interaction)��, �����Self-attention���ֵĺܲ���(has emerged as a recent advance). ��ע��������Ĺؼ�˼�������ɴ����ص�Ԫ�����ֵ�ļ�Ȩƽ��ֵ. ��ͬ�ھ����������߳ػ�����, ��ЩȨ���Ƕ�̬�ĸ�����������, ͨ�����ص�Ԫ֮��������Ժ���������(produced dynamically via a similarity function between hidden units). ��������ź�֮��Ľ����������źű���, ���������ھ�����, ��Ԥ�������ǵ����λ�ö�����.
���Ա��ij��Խ���ע��������Ӧ�õ�����������, ��ʵ�ֳ����뽻��. ���б����Ӿ�����(discriminative visual tasks)��, ����ʹ����ע�����滻��ͨ�ľ���. ����a novel two-dimensional relative self-attention mechanism, ����ע��(being infused with)���λ����Ϣ��ͬʱ���Ա���translation equivariance, ʹ��dz��ʺ�ͼ��.
��ȡ��������Ϊ�������㵥Ԫ���汻֤�����о�������. ������Ҫע�����, �ڿ���ʵ���з���, ����ע�����;������������������Ի����õĽ��. ��˲�û����ȫ��������, �������ʹ��self-attention mechanism����ǿ����(augment convolutions), ����ǿ���ֲ��Եľ�������ͼ�ͻ���self-attention�������ܹ���ģ������������(capable of modeling longer range dependencies)������ͼƴ����������ս��.
�ڶ��ʵ����, ע������ǿ������ʵ����һ�µ�����, ���������ȫ����ע��ģ��(���þ����Dz���), ����Կ�����ע������ǿģ�͵�һ���������, ��ImageNet�Ͻ������ǵ���ȫ�����ṹ�Բ�, �������ע�������һ������ͼ������ǿ������ļ���ԭ��(a powerful standalone computational primitive).
����primitive�������, �ҵ���һ�ν���: ������ָ����ϵͳ��������ĸ���.
https://stackoverflow.com/a/8022435
For me, it means something that cannot be decomposed (people use also the atomic word sometimes in that sense, but atomic is often also used for explanation on concurrency or parallelism with a different meaning).?
For instance, on Unix (or Linux) the system calls, as seen by the application are primitive or atomic, they either happen or not (sometimes, they got interrupted and give an EINTR or ERESTART error).
And inside an interpreter, or even in the formal specification, of a language, the primitive are those operations which you cannot define, and which the interpreter deals with specially. Very often, cons is a primitive operation for Lisp dialects.
�����ᵽ��������һЩvisual tasks�е�ע�����Ĺ���:
- reweigh feature channels using signals aggregated from entire feature maps
- Squeezeand-Excitation [SENet]
- Gather-Excite [http://papers.nips.cc/paper/8151-gather-excite-exploiting-feature-context-in-convolutional-neural-networks.pdf]
- refine convolutional features independently in the channel and spatial dimensions
- BAM [Bam: bottleneck attention module]
- CBAM [Cbam: Convolutional block attention module]
- the additive use of a few non-local residual blocks that employ self-attention in convolutional architectures
- non-local neural networks
��������еķ���, ����Ҫ����Ľṹ�������ڶ�Ӧ��(counterparts)��ȫ����ģ�͵�Ԥѵ��, �����������綼ʹ����self-attention mechanism. ����multi-head attention��ʹ��ʹ��ģ��ͬʱ��ע�ռ��ӿռ�������ӿռ�. (��ͷע�������ǽ�����������ͨ������Ϊ��ͬ����, ��ͬ���ڽ��е����ı任, ���Ի�ø��Ӷ���������������)
����, Ϊ����ǿͼ���ϵ���ע�����ı�������, ������չ[Selfattention with relative position representations, Music transformer]�е������ע��������ά��ʽ, ��ʹ�ÿ�������ԭ��(in a principled way)��ģ��ƽ�Ƶȱ���(translation equivariance).
�����Ľṹ����ֱ�Ӳ������������ͼ, ������ͨ���ӷ�(�����dz˷�)[Non-local neural networks, Self-attention generative adversarial networks]���ſ�[Squeeze-and-excitation networks, Gather-excite: Exploiting feature context in convolutional neural networks, Bam: bottleneck attention module, Cbam: Convolutional block attention module]����У��������. ��һ�����������ص���ע����ͨ���ı���, ��������ȫ��������ȫע��ģ����һϵ�мܹ�(a spectrum of architectures, ranging from fully convolutional to fully attentional models).
��Ҫ�ṹ
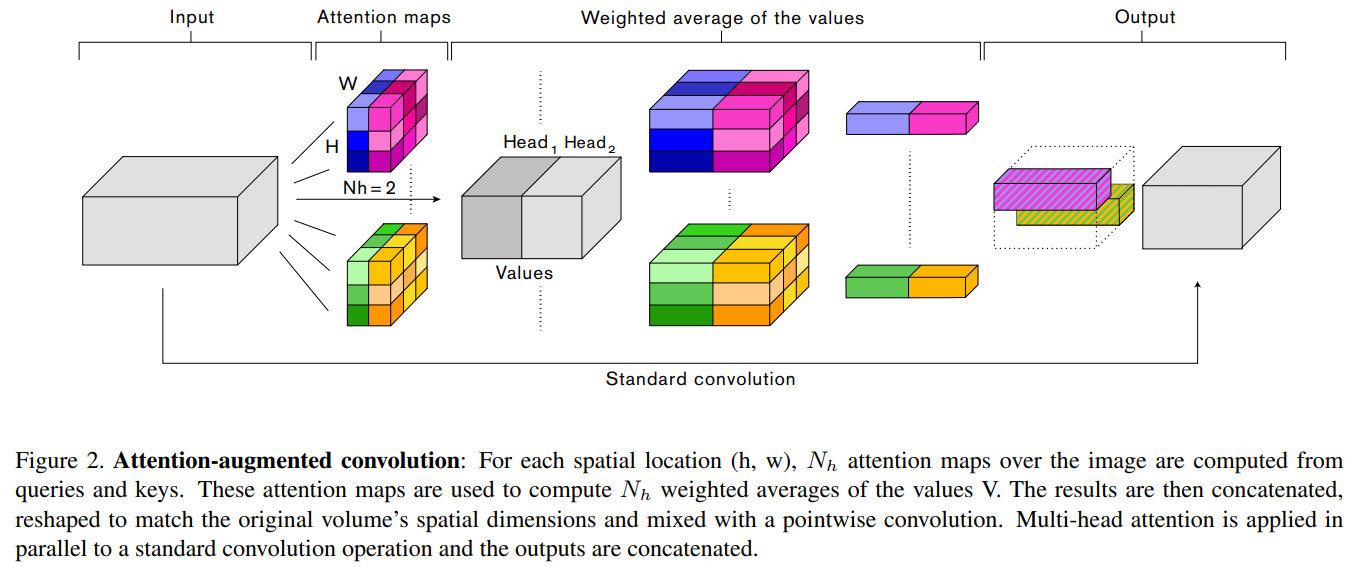
- H, W, Fin: ��������ͼ��height, weight, ͨ����
- Nh, dv, dk:heads������, values�����(Ҳ��������ͼͨ����), queries��keys�����(�⼸����������MHA, multi-head attention��һЩ����), ������Ҫ��, dv��dk������Ա�Nh����, ����ʹ��dhv��dhk����Ϊÿ��head��ֵ����ȺͲ�ѯ/�������
ͼ�����ݶ�ͷע�����ļ���
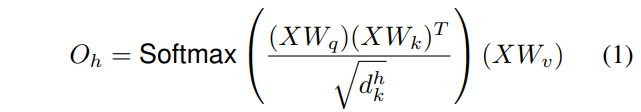
��ͷ�ļ�����ʽ
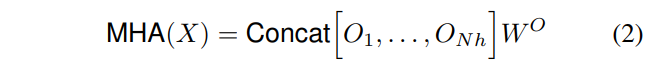
��ͷ���ɵ�ͷƴ�Ӷ���
in_tensor\((H,W,F_{in})\) =(flatten)=> X\((HW,F_{in})\)(We omit the batch dimension for simplicity.)- ����transformer�ṹ�����ͷע����
- ����head h��Ӧ����ע�������Ϊʽ��1��ʾ, �����\(W_q\)/\(W_k\)/\(W_v\)�ֱ���״Ϊ\((F_{in}, d^h_q)/(F_{in}, d^h_k)/(F_{in}, d^h_v)\), �ֱ�����ӳ������X����ѯ\(Q=XW_q\) ����\(K=XW_k\) ��ֵ\(V=XW_v\) , �ֱ����״Ϊ\((HW, d^h_q)/(HW, d^h_k)/(HW, d^h_v)\)?
- ����head�����ƴ�ӵ�һ��, Ȼ����ʽ��2���д���, �����\(W^O \in \mathbb{R}^{d_v \times d_v}\)(����֪��, �����\(N_h\)��\(O\)��ƴ��, ʵ�������Ϊ\(d_v\), Ҳ����\(d_v=N_h \times d^h_v\)), ����MHA�����������״Ϊ\((H, W, d_v)\)��ƥ��ԭʼ�Ŀռ�ά��
- multi-head attention
- ���㸴�Ӷȣ�\(O((HW)^2d_k)\)(����ֻ��Ҫ���Ǵ�ͷ\((XW_q)(XW_k)^T\)�ļ���)
- �ռ临�Ӷȣ�\(O((HW)^2N_h)\)(���������Nh��ͷ�Ľ��)
��άλ��Ƕ��Two-dimensional Positional Embeddings
�����"��ά"ʵ�����������ԭʼ������Ե�һά��Ϣ�Ľṹ����, ����������Ƕ�άͼ������.
����û����ʽ��λ����Ϣ������, ������ע�������㽻����:\(MHA(\pi(X))=\pi(MHA(X))\), �����\(\pi\)��ʾ��������λ�õ������û�. �ⷴӳ����self-attention���� permutation equivariant. ����������ʹ�ö���ģ��߶Ƚṹ��������(����ͼ��)����, ���Ǻ���Ч.
���ʹ����ʽ�Ŀռ���Ϣ����ǿ����ͼ��λ�ñ����Ѿ��������������ص�����:
- Image Transformer extends the sinusoidal waves first introduced in the original Transformer to 2 dimensional inputs.
- CoordConv concatenates positional channels to an activation map.
�����µ�ʵ���з���, ��ͼ������Ŀ������, ��Щ���뷽����������, �����ǽ����������Ȼ��Щ���Կ��Դ����û��ȱ���, ����ȴ���ܱ�֤ͼ��������Ҫ��ƽ�Ƶȱ���(permutation equivariant(�û��ȱ���), translation equivariance(ƽ�Ƶȱ���)). Ϊ��, ������չ�����е����λ�ñ���[Self attention with relative position representations]����ά��, ���һ���Music Transformer���һ���ڴ���Ч��ʵ��.
���λ��Ƕ��Relative positional embeddings
Introduced in [Self attention with relative position representations] for the purpose of language modeling, relative self-attention augments self-attention with relative position encodings and enables translation equivariance while preventing permutation equivariance.
����ͨ������������ԵĿ�����Եĸߵ���Ϣ, ��ʵ�ֶ�ά�����ע����.
��������\(i=(i_x, i_y)\)��������\(j=(j_x, j_y)\)��attention logit���㷽ʽ����(The attention logit for how much pixel i attends to pixel j is computed as):
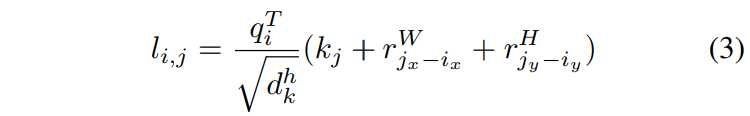
- \(q_i\)��ʾ λ��Ϊ\(i\) ��query vector, Ҳ����Q�е�һ����Ϊ\(d^h_k\)��ʸ��Ԫ��.
- \(k_j\)��ʾ λ��Ϊ\(j\) ��key vector, Ҳ����K�е�һ����Ϊ\(d^h_k\)��ʸ��Ԫ��.
- \(r^W_{j_x-i_x}\)��\(r^H_{j_y-i_y}\)��ʾ������Կ���\(j_x-i_x\)����Ը߶�\(j_y-i_y\)ѧϰ����Ƕ���ʾ, ���Ծ�Ϊdhk���ȵ�ʸ��.
- \(r\)��Ӧ�����λ�ò�������\(r^W\)��\(r^H\)�ֱ���\((2W-1, d^h_k)\)��\((2H-1, d^h_k)\)��С��.
����ͷh����������:
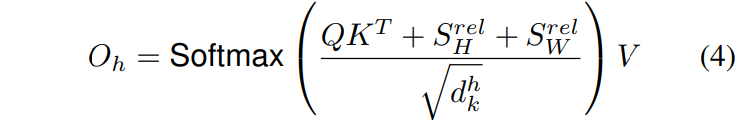
���������\(S\)����\(HW \times HW\)�ľ���, ��ʾ���ſ���ά�ȵ����λ��logits
��Ϊ������Կ�����Ϣ, ��������\(S^{rel}_W[i, j]=S^{rel}_W[i, j+W]\),\(S^{rel}_H[i, j]=S^{rel}_H[i, j+H]\). �����Ͳ���ҪΪ���е�(i, j)�Լ���logits��, �������������������(�������Լ�������): ���ڶ�ά����, ����������ΪW����(����), Ҳ����x����, ������ΪH����(����)��y��, ��������һ��\(j\)�̶��ĵ�\(i\):
- SW����\((j_x-i_x)\%W=[(j+nW)_x-i_x]\%W\), ����������������ƶ���λ��, ��λ��ͬһ��;
- SH����\((j_y-i_y)\%H=[(j+nH)_y-i_x]\%H\), ����������������ƶ�\(nH\)��λ��, ��Ȼ��ͬһ��.
��������ע��������ʽʵ���ϲ�ͬ��ԭʼ�ο�����Self attention with relative position representations�о����ڴ�ռ��Ϊ\(O((HW)^2d^h_k)\)(���Ƕ��\(r_{ij} \in \mathbb{R}^{HW \times HW \times d^h_k}\))�����, ���ǻ���MUSIC TRANSFORMER�������memory efficient relative masked attention algorithm��һ��2D��չ, ��չΪ��unmasked relative self-attention over 2 dimensional inputs��, �Ӷ��洢���ı����\(O(HWd^h_k)\)(���λ��Ƕ��\(r_{ij}\)����ֳ���������, ��\(r^H \in \mathbb{R}^{(2H-1) \times d^h_k}, r^W \in \mathbb{R}^{(2W-1 )\times d^h_k}\), ������ͷ��������ʽ���й���). ����ÿ��, ʵ����ֻ��Ҫ���Ӷ����\((2(H + W) ? 2)d^h_k\)����������ģ���ŸߺͿ�����Ծ��뼴��.
Attention Augmented Convolution
���������ʹ��ע������ǿ�ľ�����Ҫ������:
- use an attention mechanism that can attend jointly to spatial and feature subspaces (each head corresponding to a feature subspace)
- introduce additional feature maps rather than refining them
AAConv����Ҫ����:
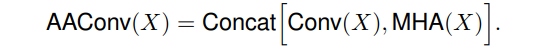
Similarly to the convolution, the proposed attention augmented convolution
- is equivariant to translation
- can readily operate on inputs of different spatial dimensions
�������Ա�һ��ľ���\((F_{out}, F_{in}, k, k)\)������AAConv�IJ�����:
- ����\(v=\frac{d_v}{F_{out}}\)��ΪMHA���ֵ������ͨ�������ܵ�AAConv���ͨ�����ı�ֵ;
- ����\(\kappa = \frac{d_k}{F_{out}}\)��ΪMHA��Key��������ܵ�AAConv���ͨ�����ı�ֵ.
- ʹ��\(1 \times 1\)���������Ա任�õ�Q\K\V, �����в�����\((d_v+d_k+d_q)F_{in} = (2d_k+d_v)F_{in}=(v+2\kappa)F_{out}F_{in}\)
- ʹ��һ�������\(1\times1\)�������ڻ�϶��ͷ�Ĺ���(mix the contribution of different heads), �ⲿ�ֲ�����Ϊ\(d_vd_v=(vF_{out})^2\);
- ����ע��������, ����һ���ֱ�����, ��ǰ��ʽ���е�
Conv, �������Ϊ:\(k^2(F_{out} - d_v)F_{in} = k^2(1 - v)F_{out}F_{in}\);
- ����, ���������λ��Ƕ��;���ƫ��֮��, ����Ľṹ�IJ�����ԼΪ:\(F_{in}F_{out}(2\kappa+v+v^2\frac{F_{out}}{F_{in}}+k^2-k^2v)=F_{in}F_{out}(2\kappa+v(1-k^2)+k^2+v^2\frac{F_{out}}{F_{in}})\)
- ��������ھ����IJ����ı仯��Ϊ\(\Delta_{params}\sim F_{in}F_{out}(2\kappa+v(1-k^2)+v^2\frac{F_{out}}{F_{in}})\), �����滻3x3����ʱ, �������ٲ�����, ���滻1x1����ʱ, ��������������.
Attention Augmented Convolutional Architectures
- ����ʵ����, AAConv�����BN�������������ע����������ͼ�Ĺ���.
- ÿ���в��ʹ��һ��AAConv.
- ����QK�Ľ�����нϴ���ڴ�ռ��, �����ǰ��մ��dz��˳��ʹ��, ֱ���ﵽ�ڴ�����.
- To reduce the memory footprint of augmented networks, we typically resort to a smaller batch size and sometimes additionally downsample the inputs to self-attention in the layers with the largest spatial dimensions where it is applied(����ָ��Ӧ������ע��������ǰ��ֱ��²������ϲ���). Downsampling is performed by applying 3x3 average pooling with stride 2 while the following upsampling (requiredfor the concatenation) is obtained via bilinear interpolation.
ʵ����
λ�ñ���
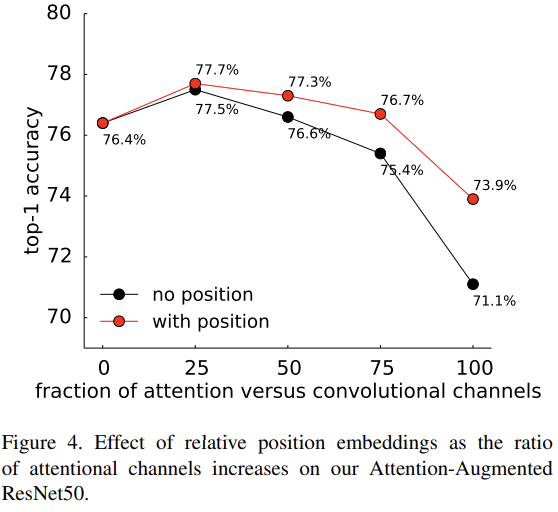
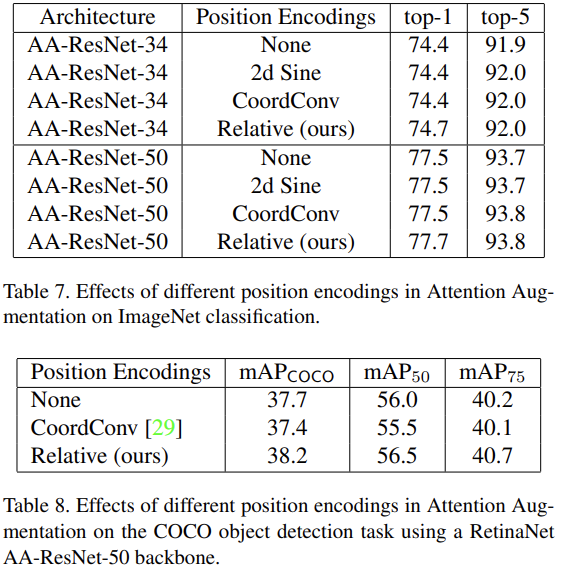
- the position-unaware version of self-attention (referred to as None),
- a two-dimensional implementation of the sinusoidal positional waves (referred to as 2d Sine) as used in [32],
- CoordConv [29] for which we concatenate (x, y, r) coordinate channels to the inputs of the attention function,
- our proposed two-dimensional relative position encodings (referred to as Relative).
δ����̽��
- Several open questions from this work remain. In future work, we will focus on the fully attentional regime and explore how different attention mechanisms trade off computational efficiency versus representational power. For instance, identifying a local attention mechanism may result in an efficient and scalable computational mechanism that could prevent the need for downsampling with average pooling [Stand-aloneself-attention in vision models].
- Additionally, it is plausible that architectural design choices that are well suited when exclusively relying on convolutions are suboptimal when using self-attention mechanisms. As such, it would be interesting to see if using Attention Augmentation as a primitive in automated architecture search procedures proves useful to find even better models than those previously found in image classification [55], object detection [12], image segmentation [6] and other domains [5, 1, 35, 8].
- Finally, one can ask to which degree fully attentional models can replace convolutional networks for visual tasks.
����ʾ��
�������������е�tensorflowʵ��, ��ʹ��pytorch������.
import torch
from einops import rearrange
from torch import nn
def rel_to_abs(x):
"""
Converts tensor from relative to aboslute indexing.
Details can be found at: https://www.yuque.com/lart/ugkv9f/oazsec
:param x: B Nh L 2L-1
:return: B Nh L L
"""
B, Nh, L, _ = x.shape
# Pad to shift from relative to absolute indexing.
col_pad = torch.zeros(B, Nh, L, 1)
x = torch.cat([x, col_pad], dim=3)
flat_x = x.reshape(B, Nh, L * 2 * L)
flat_pad = torch.zeros(B, Nh, L - 1)
flat_x = torch.cat([flat_x, flat_pad], dim=2)
# Reshape and slice out the padded elements.
final_x = flat_x.reshape(B, Nh, L + 1, 2 * L - 1)
final_x = final_x[:, :, :L, L - 1:]
return final_x
def relative_logits_1d(x, rel_k):
"""
Compute relative logits along one dimenion.
:param x: B Nh Hd L
:param rel_k: 2L-1 Hd
"""
rel_logits = torch.einsum("bndl, rd -> bnlr", x, rel_k)
rel_logits = rel_to_abs(rel_logits) # B Nh L 2L-1 -> B Nh L L
return rel_logits
class RelativePosEmbedding(nn.Module):
"""
Compute relative_logits.
For ease, we 1) transpose height and width, 2) repeat the above steps and 3) transpose to eventually
put the logits in their right positions.
"""
def __init__(self, h, w, dim):
super(RelativePosEmbedding, self).__init__()
self.h = h
self.w = w
self.rel_emb_w = torch.randn(2 * w - 1, dim)
nn.init.normal_(self.rel_emb_w, dim ** -0.5)
self.rel_emb_h = torch.randn(2 * h - 1, dim)
nn.init.normal_(self.rel_emb_h, dim ** -0.5)
def forward(self, x):
"""
:param x: B Nh Hd HW
:return: B Nh HW HW
"""
Nh = x.shape[1]
# Relative logits in width dimension first.
rel_logits_w = relative_logits_1d(
rearrange(x, "b nh hd (h w) -> b (nh h) hd w", h=self.h, w=self.w), self.rel_emb_w
)
rel_logits_w = rearrange(rel_logits_w, "b (nh h) w0 w1 -> b nh h () w0 w1", nh=Nh)
# Relative logits in height dimension next.
rel_logits_h = relative_logits_1d(
rearrange(x, "b nh hd (h w) -> b (nh w) hd h", h=self.h, w=self.w), self.rel_emb_h
)
rel_logits_h = rearrange(rel_logits_h, "b (nh w) h0 h1 -> b nh h0 h1 w ()", nh=Nh)
return rearrange(rel_logits_h + rel_logits_w, "b nh h0 h1 w0 w1 -> b nh (h0 w0) (h1 w1)")
class AbsolutePosEmbedding(nn.Module):
"""
Given query q of shape [batch heads tokens dim] we multiply
q by all the flattened absolute differences between tokens.
Learned embedding representations are shared across heads
"""
def __init__(self, h, w, dim):
super().__init__()
scale = dim ** -0.5
self.abs_pos_emb = nn.Parameter(torch.randn(h * w, dim) * scale)
nn.init.normal_(self.abs_pos_emb, scale)
def forward(self, x):
"""
:param x: B Nh Hd HW
:return: B Nh HW HW
"""
return torch.einsum("bndx, yd -> bhxy", x, self.abs_pos_emb)
class SelfAttention2D(nn.Module):
def __init__(self, in_dim, key_dim, value_dim, nh, hw, pos_mode="relative"):
super(SelfAttention2D, self).__init__()
self.dkh = key_dim // nh
self.dvh = value_dim // nh
self.nh = nh
self.key_dim = key_dim
self.value_dim = value_dim
self.kqv_proj = nn.Conv2d(in_dim, 2 * key_dim + value_dim, 1)
self.out_proj = nn.Conv2d(value_dim, value_dim, 1)
if pos_mode == "relative":
self.position_embedding = RelativePosEmbedding(h=hw[0], w=hw[1], dim=self.dkh)
elif pos_mode == "absolute":
self.position_embedding = AbsolutePosEmbedding(h=hw[0], w=hw[1], dim=self.dkh)
else:
self.position_embedding = nn.Identity()
def split_heads_and_flatten(self, _x):
return rearrange(_x, "b (nh hd) h w -> b nh hd (h w)", nh=self.nh)
def forward(self, x):
"""
:param x: B C H W
"""
# Compute q, k, v
k, q, v = self.kqv_proj(x).split([self.key_dim, self.key_dim, self.value_dim], dim=1)
q = q * self.dkh ** -0.5 # scaled dot-product
# After splitting, shape is [B, Nh, dkh or dvh, HW]
q, k, v = map(self.split_heads_and_flatten, (q, k, v))
# [B, Nh, HW, HW]
logits = torch.einsum("bndx, bndy -> bnxy", q, k)
logits += self.position_embedding(q)
weights = logits.softmax(-1)
attn_out = torch.einsum("bnxy, bndy -> bndx", weights, v)
attn_out = rearrange(attn_out, "b nd hd (h w) -> b (nd hd) h w", h=x.shape[2], w=x.shape[3])
# Project heads
attn_out = self.out_proj(attn_out)
return attn_out
class AugmentedConv2d(nn.Module):
def __init__(self, in_dim, out_dim, kernel_size, key_dim, value_dim, num_heads, hw, pos_mode):
super(AugmentedConv2d, self).__init__()
self.std_conv = nn.Conv2d(in_dim, out_dim - value_dim, kernel_size, padding=kernel_size // 2)
self.attention = SelfAttention2D(
in_dim, key_dim=key_dim, value_dim=value_dim, nh=num_heads, hw=hw, pos_mode=pos_mode
)
def forward(self, x):
conv_out = self.std_conv(x)
attn_out = self.attention(x)
return torch.cat([conv_out, attn_out], dim=1)
if __name__ == "__main__":
m = AugmentedConv2d(
in_dim=4, out_dim=64, kernel_size=3, key_dim=32, value_dim=48, num_heads=2, hw=(10, 10), pos_mode="relative"
)
print(m(torch.randn(4, 4, 10, 10)).shape)
һЩ�ɻ�
- permutation equivariance(�û��ȱ���), translation equivariance(ƽ�Ƶȱ���)���ߵIJ�����ʲô?
����֪ʶ
����self-attention������������, query Q/key K/value V, ���߾����ʾ�ĺ�����ʲô��? ��������ժ��https://www.cnblogs.com/rosyYY/p/10115424.html:
- Q��K��V�а����Ķ���ԭʼ���ݵ�Ƕ���ʾ
- QΪʲô��query��
- ����Ϊÿ����Ҫ��һ��Ƕ���ʾȥ"��ѯ"��������Ƕ���ʾ֮���match�̶�, Ҳ����attention��С
- K��V��ʾ��ֵ, ��������Ľ���, ���������ɲ���, ��
��Seq2seq��Attentionģ�͵�Self Attention(��) - ����Ͷ�ʻ���ѧϰ������ - ֪�� https://zhuanlan.zhihu.com/p/47470866 ���д��ᵽ:"key��value����Դ���� Key-Value Memory Networks for Directly Reading Documents. ��NLP��������, Key, Valueͨ������ָ��ͬһ������������(word embedding vector)". �������������.
�������
- ����:https://arxiv.org/pdf/1904.09925.pdf
- ����:https://github.com/leaderj1001/Attention-Augmented-Conv2d
- ����:https://www.jiqizhixin.com/articles/2019-04-26-7
- multi-head attention:https://www.cnblogs.com/rosyYY/p/10115424.html
- ��Seq2seq��Attentionģ�͵�Self Attention(��) - ����Ͷ�ʻ���ѧϰ������ - ֪�� https://zhuanlan.zhihu.com/p/47470866
- The Illustrated Transformer:https://jalammar.github.io/illustrated-transformer/
- ����:https://blog.csdn.net/qq_42208267/article/details/84967446
- ��Ȼ���Դ����е���ע��������(Self-attention Mechanism):https://www.cnblogs.com/robert-dlut/p/8638283.html
- https://kexue.fm/archives/4765
bk