def func(st):
for i in range(1,int(len(st)/2)+1):
for j in range(len(st)):
if st[j:j+i] == st[j+i:j+2*i]:
k = j + i
while st[k:k+i] == st[k+i:k+2*i] and k<len(st):
k = k + i
st = st[:j] + st[k:]
return st
df["评论内容"] = df["评论内容"].apply(func)
数据可视化操作
俗话说:“字不如表,表不如图”。爬取到的数据,最终做可视化的呈现,才能够让大家对数据背后的规律,有一个清晰的认识。下面我们从以下几个方面来进行数据可视化分析。
- 评论数随时间的变化趋势
- 二十四小时内的评论数的变化趋势
- 星级评分的饼图
- 大家主要都在评论一些啥
关于数据可视化工具,我就不用pyecharts了,我还是回归原始,用最原始的matplotlib库进行数据可视化的展示。毕竟我们没有什么复杂的展示,代码越简短越好。
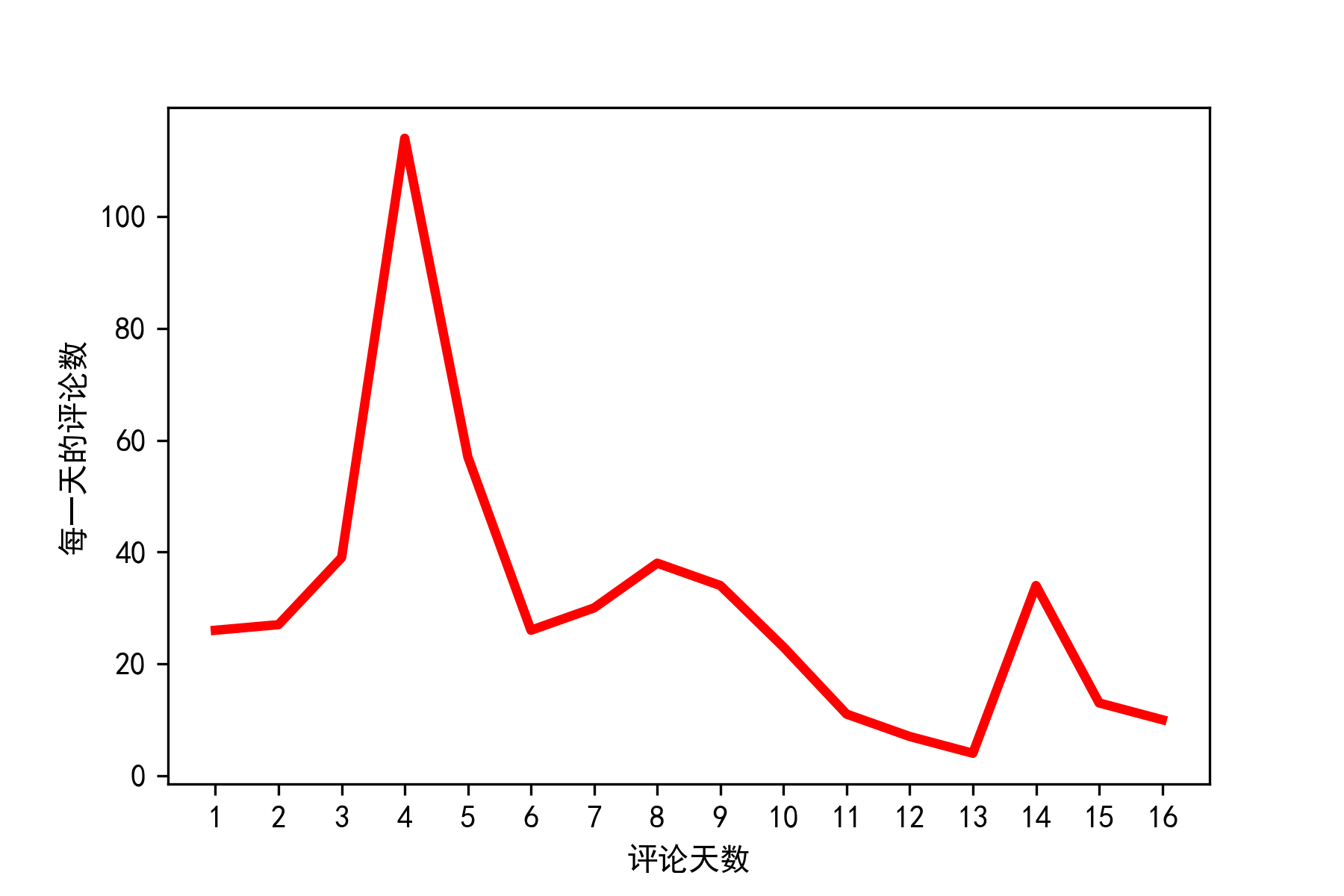
1)评论数随时间的变化趋势
从图中可以看出:短评数量在12月4日之前,一直处于上升趋势,在12月4日达到顶峰。和文章最开始的说明一致,前面几天观众对于该剧的期待值较高,但是在12月4日后,突然出现断崖式下降,说明随着该剧的更新,大家有所失望了。
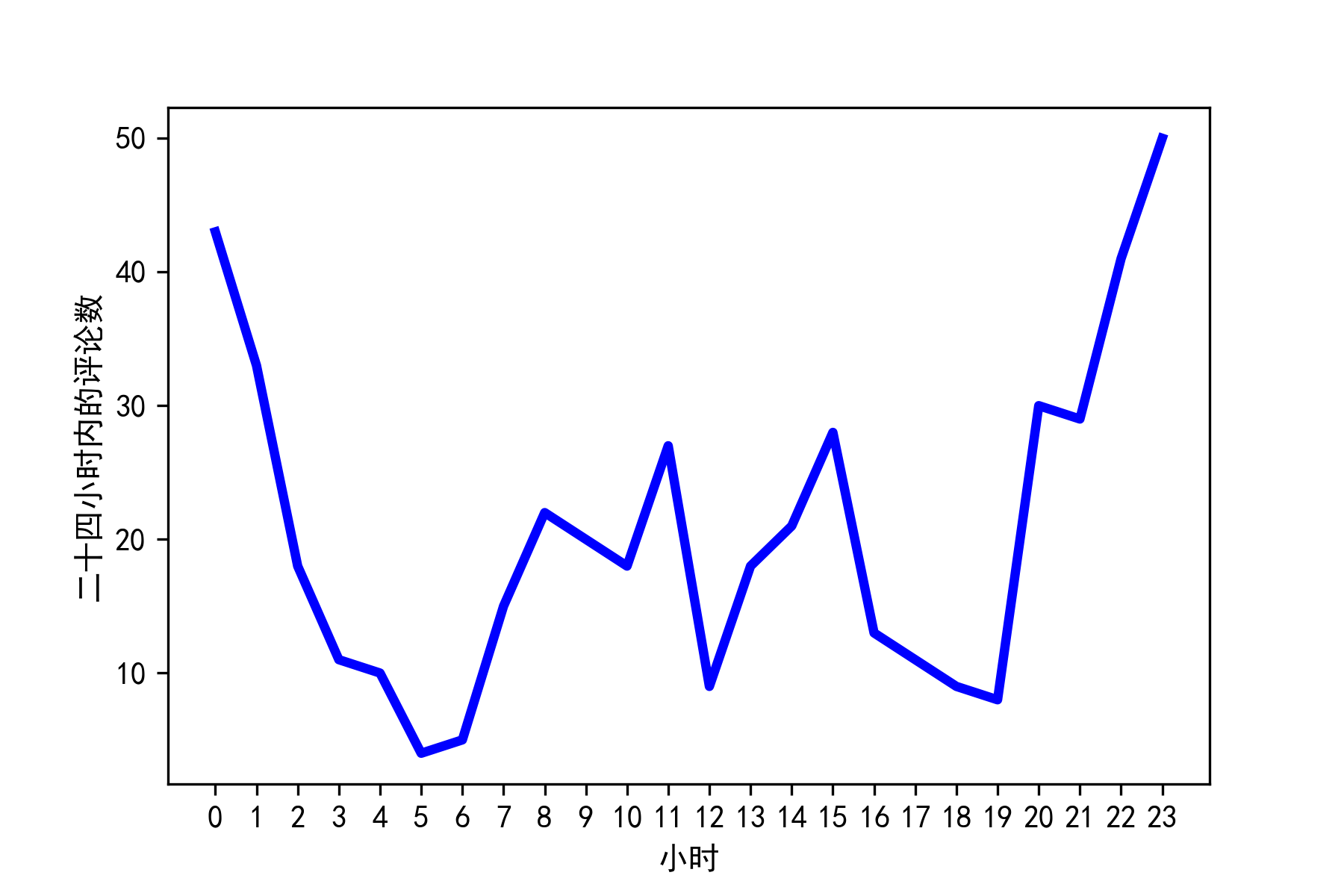
2)二十四小时内的评论数的变化趋势
最近总听到周围有人在讨论这部剧,下面就来看看大家都是在啥时候追剧呢?从24小时图中可以看出:晚上7-24点,评论急剧上升,大多数人都是6点下班,可能吃个饭到7点左右,或者直接在下班过程中,就开始了一天的追剧。这里还有一波早高峰5-8点,难道睡不着?早上还要起来刷刷据,然后上班。这里还有两个时间段:上午10-11点,中午12-15点,大家可以分析下,肯定有相当一部分小伙伴,正在摸鱼工作呀🤭
3)星级评分的饼图
剧究竟好不好,看看观众的评分少不了,这也是观众最直观的想法。
- 1星:很差
- 2星:较差
- 3星:还行
- 4星:推荐
- 1星:力荐
从下图中可以看出:大家对于该剧的哦=评价还是很低的,1星和2星基本占据了整个饼图,也就是说该剧并没有得到大家的认可。
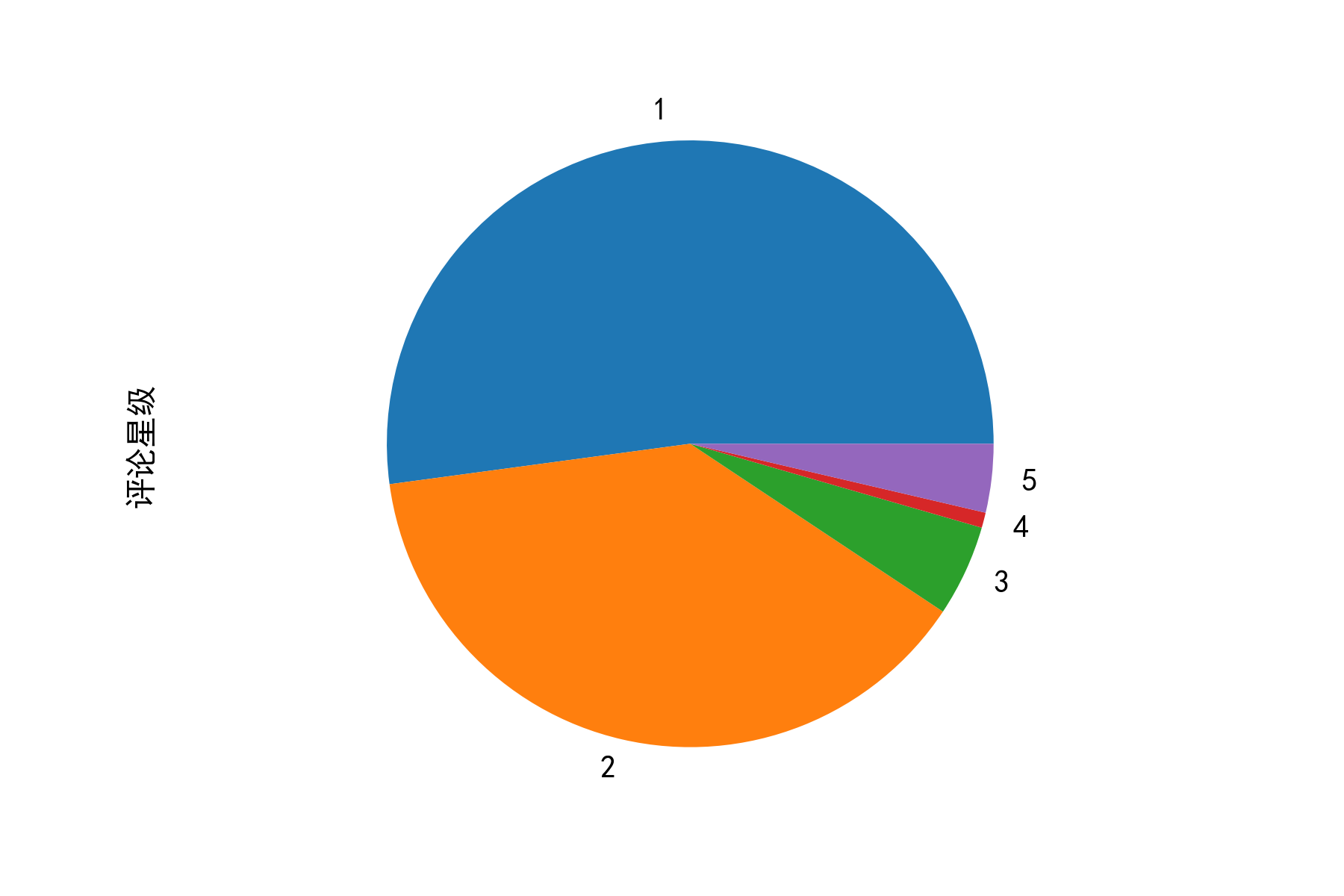
4)大家主要都在评论一些啥
其实大家对于该剧最大的争论点,还是由张鲁一饰演的嬴政。40岁的张鲁一,竟然饰演13岁的少年嬴政,然后向36岁朱珠饰演的赵姬分享喜讯,这个角色显色很不协调。很多人支护:难道请不起小演员吗?
还有一部分人,对该剧的剧情和台词很是吐槽,嬴政称如果吕不韦是自己的生父,愿意跟他一起离开秦国浪迹天涯,这真的是少年老成的嬴政能说出来的话吗?
《大秦赋》是“大秦帝国”系列的第四部,原名为《大秦帝国之天下》,播出时改为了《大秦赋》。于是很多人将这部剧和2009年播出的《大秦帝国》作比较,以此来讽刺该剧。

好了,今天的分享就到此为止。如果你有更多的时间,更多的分析思路,可以下去拓展哦!