Т»ЎўКЧПИОТГЗТӘХТөҪДҝұк
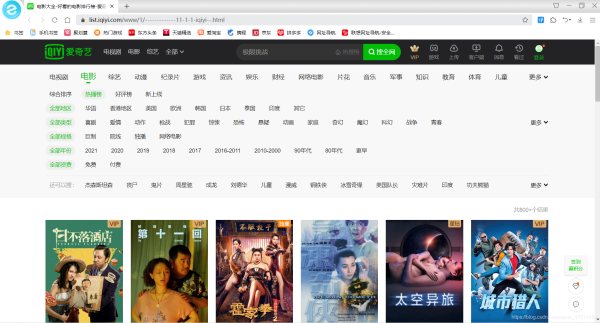
ХТөҪДҝұкПИ·ЦОцТ»ПВНшТіЈЁurl:https://list.iqiyi.com/www/1/-------------11-1-1-iqiyiЁC.html),әЬРТФЛХвёцЦ»УРТ»ёцНшТіЈ¬І»РиТӘ·ӯТіЎЈ
¶юЎўF12ІйҝҙНшТіФҙҙъВл
ХТөҪДҝұкЈ¬·ЦОцИзәО»сИЎРиТӘөДКэҫЭЎЈХТөҪhrefУлөзУ°ГыіЖ
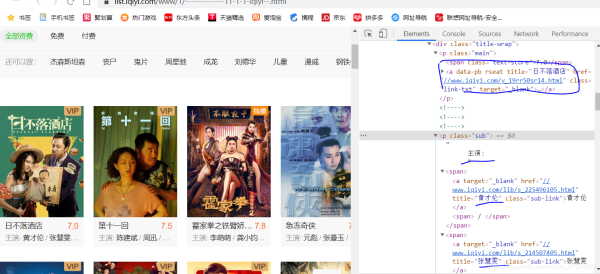
ИэЎўҪшРРҙъВлКөПЦЈ¬»сИЎПлТӘЧКФҙЎЈ
'''
ЕАИЎ°®ЖжТХөзУ°УлөШЦ·В·ҫ¶
ІЩЧчІҪЦи
1Ј¬»сИЎөҪurlДЪИЭ
2,cssСЎФсЖдСЎФсДЪИЭ
3Ј¬ұЈҙжЧФјәРиТӘКэҫЭ
'''
#өјИлЕАіжРиТӘөД°ь
import requests
from bs4 import BeautifulSoup
#requestsУлBeautifulSoupУГАҙҪвОцНшТіөД
import time
#ЙиЦГ·ГОКНшТіКұјдЈ¬·АЦ№ЧФјәIP·ГОК¶аБЛұ»ПЮЦЖҫЬҫш·ГОК
import re
class Position():
def __init__(self,position_name,position_require,):#№№ҪЁ¶ФПуКфРФ
self.position_name=position_name
self.position_require=position_require
def __str__(self):
return '%s%s/n'%(self.position_name,self.position_require)#ЦШФШ·Ҫ·ЁҪ«КдИлұдБҝёДіЙЧЦ·ыҙ®РОКҪ
class Aiqiyi():
def iqiyi(self,url):
head= {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47"
} #ДЈДвөД·юОсЖчН·
html = requests.get(url,headers=head)
#headers=hard ИГҪЕұҫТФдҜААЖчөД·ҪКҪИҘ·ГОКЈ¬УРТ»Р©НшЦ·ҪыЦ№ТФpythonөД·ҙЕА»ъЦЖЈ¬ХвҫНКЗЖдЦРТ»ёц
soup = BeautifulSoup(html.content, 'lxml', from_encoding='utf-8') # BeautifulSoupҙтҝҙНшТі
soupl = soup.select(".qy-list-wrap") # ІйХТұкЗ©Ј¬УГcssСЎФсЖчЈ¬СЎФсЧФјәРиТӘКэҫЭ ҪшРРСЎФсТіГжөЪТ»ҙОДЪИЭЈЁұкЗ©ТӘХТөҪОЁТ»өДЈ¬ХТidәГЈ¬Из№ыГ»УРҝјВЗЖдЛыұкЗ©ИзclassЈ©
results = [] # ҙҙҪЁТ»ёцБРұнУГАҙҙжҙўКэҫЭ
for e in soupl:
biao = e.select('.qy-mod-li') # ҪшРР¶юҙОЙёСЎ
for h in biao:
p=Position(h.select_one('.qy-mod-link-wrap').get_text(strip=True),
h.select_one('.title-wrap').get_text(strip=True))#өчУГАаЧӘ»»ЈЁјМРшИэҙОЙёСЎСЎФсЧФјәРиТӘДЪИЭЈ©
results.append(p)
return results # ·ө»ШДЪИЭ
def address(self,url):
#ұЈҙжНшЦ·
head = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47"
} # ДЈДвөД·юОсЖчН·
html = requests.get(url, headers=head)
soup = BeautifulSoup(html.content, 'lxml', from_encoding='utf-8') # BeautifulSoupҙтҝҙНшТі
alist = soup.find('div', class_='qy-list-wrap').find_all("a") # ІйХТdivҝйДЈҝйПВөД aұкЗ©
ls=[]
for i in alist:
ls.append(i.get('href'))
return ls
if __name__ == '__main__':
time.sleep(2)
#ЙиЦГ2Гл·ГОКТ»ҙО
a=Aiqiyi()
url = "https://list.iqiyi.com/www/1/-------------11-1-1-iqiyi--.html"
with open(file='e:/Б·П°.txt ', mode='a+') as f: # e:/Б·П°.txt ОӘОТөзДФРВҪЁөДОДјюЈ¬a+ОӘёшДЪИЭҪшРРМнјУЈ¬ө«І»ҪшРРёІёЗФӯДЪИЭЎЈ
for item in a.iqiyi(url):
line = f'{item.position_name}\t{item.position_require}\n'
f.write(line) # ІЙУГ·Ҫ·Ё
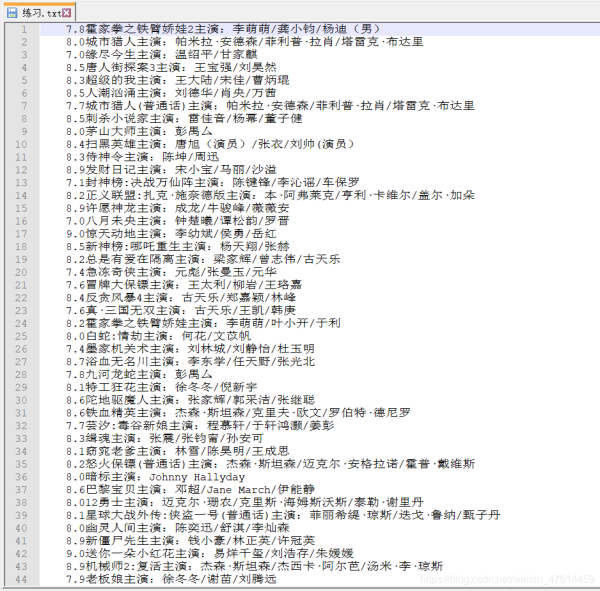
print("ПВФШНкіЙ")
with open(file='e:/өШЦ·.txt ', mode='a+') as f: # e:/Б·П°.txt ОӘОТөзДФРВҪЁөДОДјюЈ¬a+ОӘёшДЪИЭҪшРРМнјУЈ¬ө«І»ҪшРРёІёЗФӯДЪИЭЎЈ
for item in a.address(url):
line=f'https{item}\n'
f.write(line) # ІЙУГ·Ҫ·Ё
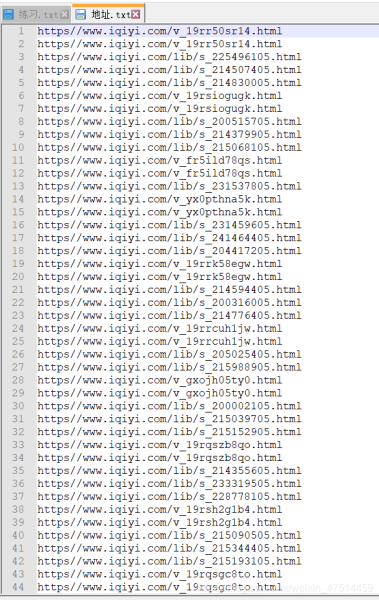
print("ПВФШНкіЙ")
ЛДЎўІйҝҙПЦПу
js