���룬���߸߲�������٣�û�������������ˮ̫�ʲô�߲������������Ķ�����������ģ�����̫���ᣬû���Ǹ����������ղ�ס��ϵͳֻ�м�QPS�����Ŀ��־��У���PK������PK��

�ҹ�ע�Ĵ��и����ˣ��ڸɻ����µ���������ôһС����

�ҳ������жĵijɷ֣����ȥһ������Ȼ�ǹ�档˵��ģ����ݿ��������Ǻ����������ģ�����ƶ����ֹ�������ѵij嶯��
��Ϊһ���߲��������⺺�����Խ��ѧ���Ŀγ̺�һЩ���ϵ�����������һ�¶��ڸ߲�������ʶ������ʵս�Dz�����ʵս�ģ�ֻ�ܶ�����Ƥ�����ӡ�
ʲô�Ǹ߲���
�߲���ָ����ϵͳͬʱ�����ܶ�����
�߲�����һ���������Ķ��������磬�����ĸ߲��������У��Ա���˫11������ʱ����Ʊ������V���ȵ����ŵȣ���Щ���ͳ��������Ƕ�Ȼ��������������ҵ��չ�ķ�չ�����֡���2020���Ա�˫11ȫ���������������ֵ�ﵽ�˾��˵�58.3���/�룬4��ǰ��2016�꣬������ִ�����ķ�֮һ������ǰ���꣬������ݲ��ɿ������ǿ϶���û��ô�����ˡ�
�߲�����ҵ�������ˣ���֮�����ľ���Ҫ֧������߲���ҵ���ļܹ���������ҪΪҵ�����ҵ�Ƽ�����չ���߲����ļܹ�Ҳ����ij�����ڤ˼����������һ�����������������ҵ��ķ�չ���ݽ�����һ������������������ɽ���ŵ�����˾����
�ǵ��������߲����أ�
���������û�о���������飬ֻ�������Dz��еģ�Ҫ��Ͼ���ij���������˵10W QPS����ɱ�Ǹ߲�������1W QPS����Ϣ���Ͳ��Ǹ߲�������Ϣ�������漰���ӵ��Ƽ�ģ�ͺ����˹����ԣ�����ҵ�������ܱ���ɱ��������10����ֹ��ҵ����һ����ִ�и��ӶȲ�һ��������������Ҳû�����塣
�ܽ���ǣ��߲������ƣ���Ҫ�;����ҵ�����ϵġ��߲����������߲����ܹ���
�߲���Ŀ��
���Ŀ��
�߲���������ζ��ֻ������ܡ��Ӻ�۽Ƕȿ����߲���ϵͳ��Ƶ�Ŀ���������������ܡ��߿��ã��Լ��߿���չ��������ν�ġ����ߡ������߲��ǹ����ģ������֧�ŵġ�
1�������ܣ�����������ϵͳ�IJ��д���������������Ӳ��Ͷ���£����������ζ�Ž�ʡ�ɱ���ͬʱ������Ҳ��ӳ���û����飬��Ӧʱ��ֱ���100�����1�룬���û��ĸ�������ȫ��ͬ�ġ�
2���߿��ã���ʾϵͳ�������������ʱ�䡣һ��ȫ�겻ͣ�������ϣ���һ����������������¹ʡ�崻����û��϶�ѡ��ǰ�ߡ����⣬���ϵͳֻ������90%���ã�Ҳ��������ҵ��
3������չ����ʾϵͳ����չ�����������߷�ʱ�ܷ��ڶ�ʱ����������ݣ���ƽ�ȵسнӷ�ֵ����������˫11������������ȵ��¼���

��3��Ŀ������Ҫͨ�̿��ǵģ���Ϊ���ǻ������������Ҳ���Ӱ�졣
����˵������ϵͳ����չ����������Ҫ��������Ƴ���״̬�ģ����ּ�Ⱥ��Ʊ�֤�˸���չ�ԣ���ʵҲ���������ϵͳ�����ܺͿ����ԡ�
�ٱ���˵��Ϊ�˱�֤�����ԣ�ͨ����Է���ӿڽ��г�ʱ���ã��Է������߳������������������ϵͳѩ�����dz�ʱʱ�����óɶ��ٺ����أ�һ�㣬���ǻ�ο�������������ܱ��ֽ������á�
����Ŀ��
����ָ��
����ָ��ͨ������ָ����Զ���Ŀǰ���ڵ��������⣬Ҳ�Ǹ߲�����Ҫ��ע��ָ�꣬���ܺ��������泣�õ�һЩָ����
- QPS/TPS/HPS��QPS��ÿ���ѯ����TPS��ÿ����������HPS��ÿ��HTTP����������õ�ָ����QPS��
��Ҫע����ǣ���������QPS�Dz�ͬ�ĸ����������ָϵͳͬʱ�ܴ�����������������Ӧ��ϵͳ�ĸ���������
������ = QPS?ƽ����Ӧʱ��
-
��Ӧʱ�䣺���������յ���Ӧ���ѵ�ʱ�䣬����һ��ϵͳ����һ��HTTP������Ҫ100ms�����100ms����ϵͳ����Ӧʱ�䡣
-
ƽ����Ӧʱ�䣺��ã�����ȱ�ݺ����ԣ��������������С����� 1 ����������� 9900 ���� 1ms��100 ���� 100ms����ƽ����Ӧʱ��Ϊ 1.99ms����Ȼƽ����ʱ�������� 0.99ms������ 1%�������Ӧʱ���Ѿ������� 100 ����
-
TP90��TP99 �ȷ�λֵ������Ӧʱ�䰴�մ�С��������TP90 ��ʾ���ڵ� 90 ��λ����Ӧʱ�䣬 ��λֵԽ��������Խ���С�

-
RPS��������������λʱ���ڴ�������������ͨ����QPS�Ͳ�����������
ͨ�����趨����Ŀ��ʱ��������������Ӧʱ�䣬����������������ÿ�� 1 ��������£�AVG ������ 50ms ���£�TP99 ������ 100ms ���¡����ڸ߲���ϵͳ��AVG �� TP ��λֵ����ͬʱҪ���ǡ�
���⣬���û�����Ƕ�������200 ���뱻��Ϊ�ǵ�һ���ֽ�㣬�û��о������ӳ٣�1 ���ǵڶ����ֽ�㣬�û��ܸ��ܵ��ӳ٣����ǿ��Խ��ܡ�
��ˣ�����һ�������ĸ߲���ϵͳ��TP99 Ӧ�ÿ����� 200 �������ڣ�TP999 ���� TP9999 Ӧ�ÿ����� 1 �����ڡ�
-
PV���ۺ����������ҳ����������ߵ������һ���ÿ���24Сʱ�ڷ��ʵ�ҳ��������
-
UV�������ÿ� ����һ��ʱ�䷶Χ����ͬ�ÿͶ�η�����վ��ֻ����Ϊһ�������ķÿ͡�
-
������ ���������С��Ҫ��ע����ָ�꣬��ֵ������ҳ���ƽ����С��
����վ��������ʹ������Ĺ�ʽ�����Լ��㣺
����վ����=pv/ͳ��ʱ�䣨���㵽�룩*ƽ��ҳ���С����λkB��*8
��ֵһ����ƽ��ֵ�ı�����
QPS�����ڲ�����������QPS��ÿ��HTTP����������������������ϵͳͬʱ��������������:
��ֵÿ����������QPS�� = (��PV�� * 80%) /��6Сʱ���� * 20%��
������ָ��
�߿�������ָϵͳ���нϸߵ��������������������� = ƽ������ʱ�� / ϵͳ������ʱ�䣬һ��ʹ�ü��� 9 ������ϵͳ�Ŀ����ԡ�
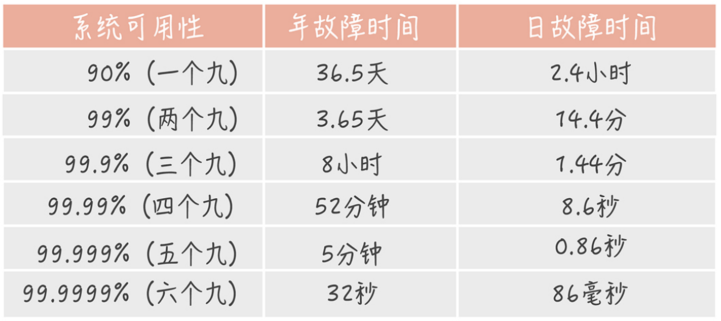
���ڴ����ϵͳ��2��9�ǻ������ã�����ﲻ����������ά���ܾ�Ҫ�������ˣ���3��9�ǽϸ߿��ã�4��9�Ǿ����Զ��ָ������ĸ߿��á�Ҫ��ﵽ3��9��4��9�����ѣ�������Ӱ�����طdz��࣬���ѿ��ƣ���Ҫ��Ӳ�ļ������������豸�ʽ�Ͷ�룬����ʦҪ�߱������ģ�������Ҫ��������
����չ��ָ��
���ͻ����������������ʱ����ܹ������ķ�ʽ�������ӻ������������ϵͳ�Ĵ���������
����ҵ��Ⱥ�����������˵����չ�� = ������������ / �������ӱ������������չ�����ǣ���Դ���Ӽ�������������������ͨ����˵����չ����Ҫά���� 70%���ϡ�
���ǴӸ߲���ϵͳ������ܹ��Ƕ���������չ��Ŀ�겻�����ǰѷ�����Ƴ���״̬�����ˣ���Ϊ���������� 10 ����ҵ�������Կ������� 10 �����������ݿ���ܾͳ�Ϊ���µ�ƿ����
�� MySQL ������״̬�Ĵ洢����ͨ������չ�ļ����ѵ㣬����ܹ���û��ǰ���ù滮����ֱ��ˮƽ��֣����ͻ��漰���������ݵ�Ǩ�ơ�
������Ҫվ������ܹ��ĽǶȣ�����������ҵ��������ĽǶ�������ϵͳ����չ�� ������˵�����ݿ⡢���桢�����ĵ����������ؾ��⡢�����������ȵȶ���ϵͳ��չʱ��Ҫ���ǵ����ء�����Ҫ֪ ��ϵͳ��������ijһ������֮����һ�����ػ��Ϊ���ǵ�ƿ���㣬�Ӷ�����Եؽ�����չ��
�߲����ܹ��ݽ�
˭����������������˾�����ܹ�Ҳ���Ǽ�������֧�ָ߲�������������һ������ļܹ��ݽ������ӡ����Ա�����ʵڹ���ˡ��õļܹ��ǽ������ģ�����������ġ���
���������ԡ��Ա�������ʮ�꡷�������Ա�2003��2012��ļܹ��ݽ���
������վ
�����Ա����Ŷ���Աֻ��ʮ��������������ǧ���ѷ����ҵ���ᣬ����Ҫ�����ߵ�ʱ��Խ��Խ�ã�ʵ�����˲���һ���£�����ô�Ա�����Щţ������ô�������أ�
������һ����
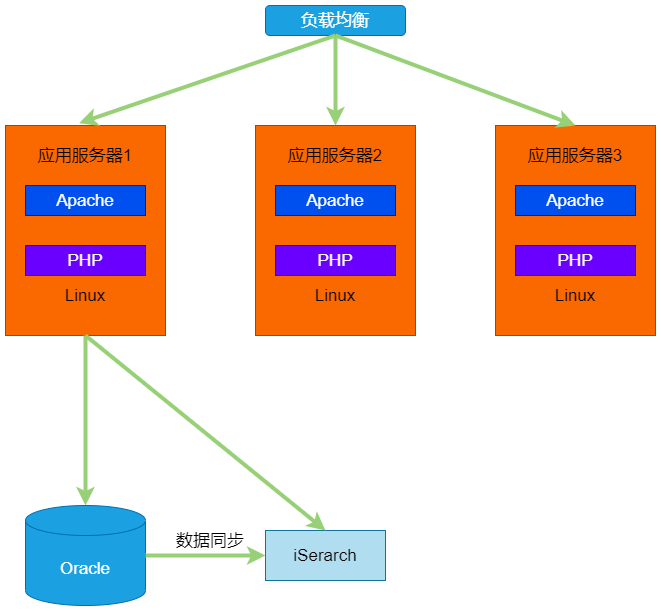
�����Ա���������һ���ܹ�����վ�� LAMP��Linux+Apache+MySQL+PHP��������ϵͳ�ļܹ����£�

�������վ�������ģ�

������Ʒ�����Ƚ�ռ�����ݿ���Դ�������������˰���Ͱ͵���������iSearch��
Oracle/֧����/����
�Ա����ٷ�չ�������ͽ�����Ѹ���������������������µ����⡪��MySQL����ס�ˡ���ô�죿Ҫ���������û�У��Ա�����Oracle���ݿ⣬��Ȼ���Ҳ���ǵ��Ŷ�����Oracle��ţ��ԭ��
�滻�����ݿ�֮��ļܹ���
�Ƚ�����˼�ģ���ʱ�����������õ����ӳأ���������һ����Դ�����ӳش�������SQLRelay�����������������������ô����أ�������ά������ʦ24Сʱ��������������Ͻ�����SQL Relay����????
����Ϊ���Ż��洢��������NAS��Network Attached Storage�����總���洢����NetApp �� NAS �洢��Ϊ�����ݿ�Ĵ洢�豸������ Oracle RAC��Real Application Clusters��ʵʱӦ�ü�Ⱥ����ʵ�ָ��ؾ��⡣
Java ʱ�� 1.0
2004�꣬�Ա��Ѿ�������һ���ʱ�䣬�����ᵽ��SQLRelay�����������ˣ����ݿ����Ҫ��Oracle�����Ծ��������������ԡ�
�ڲ���������ҵ��չ������£�ƽ����������ļܹ����Ե�ʱ���Ա���Ȼ�Ǹ�����ս�Ե����顣������ô�죿�Ա��Ľ������������Sun��˾�Ĵ��С�
��ʱ������struts1.x���ںܶ����⣬�����Ա�������һ��MVC��ܡ�Sun��ʱ����EJB���������ܹ���Ҳ������EJB��
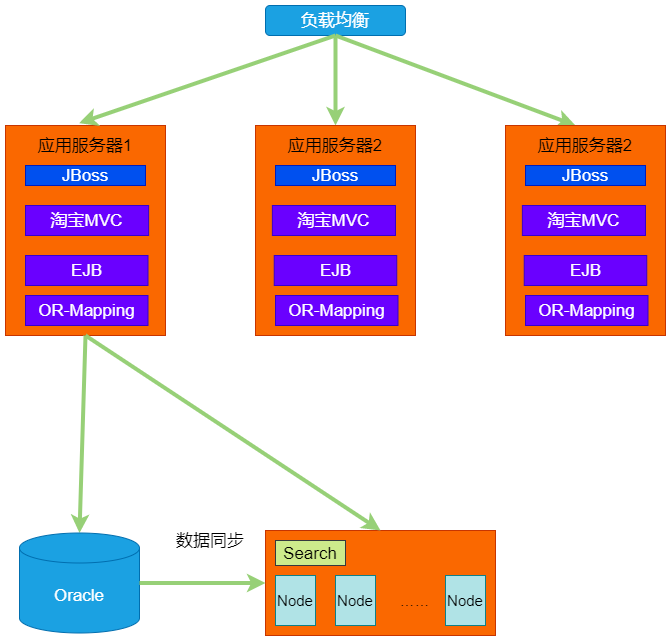
Java ʱ�� 2.0
��֮ǰ���Ա��ļܹ��ļܹ���Ҫ˼·���ǡ�������ҵ��ķ�չ������2005 �꣬�����Ѿ����ѽ�������ˣ���Ҫ�������ܹ����е������Ż�����Ҫ�ۺϿ������������ܡ��ɱ������⡣
��Javaʱ��2.0����Ҫ���˶����ݷֿ⡢����EJB������Spring�����뻺�桢����CDN�ȡ�
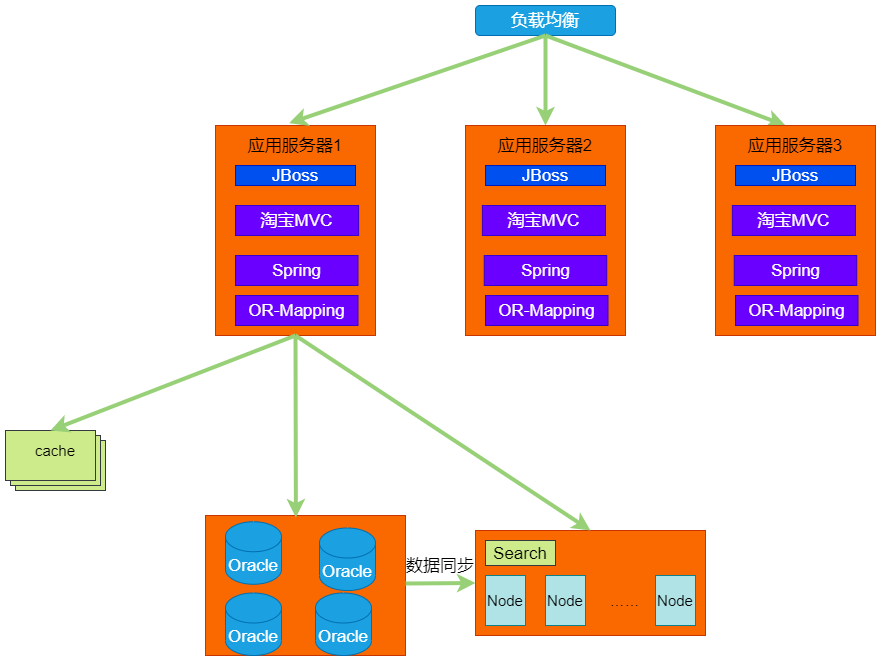
Javaʱ��3.0
Javaʱ��3.0������ص�����Ա���ʼ������תΪ�����С�����ʼ���������Լ��ĺ��ļ��������绺��洢����Tair���ֲ�ʽ�洢ϵͳTFS����������iSearchҲ���������������������м������Ա��ܹ���
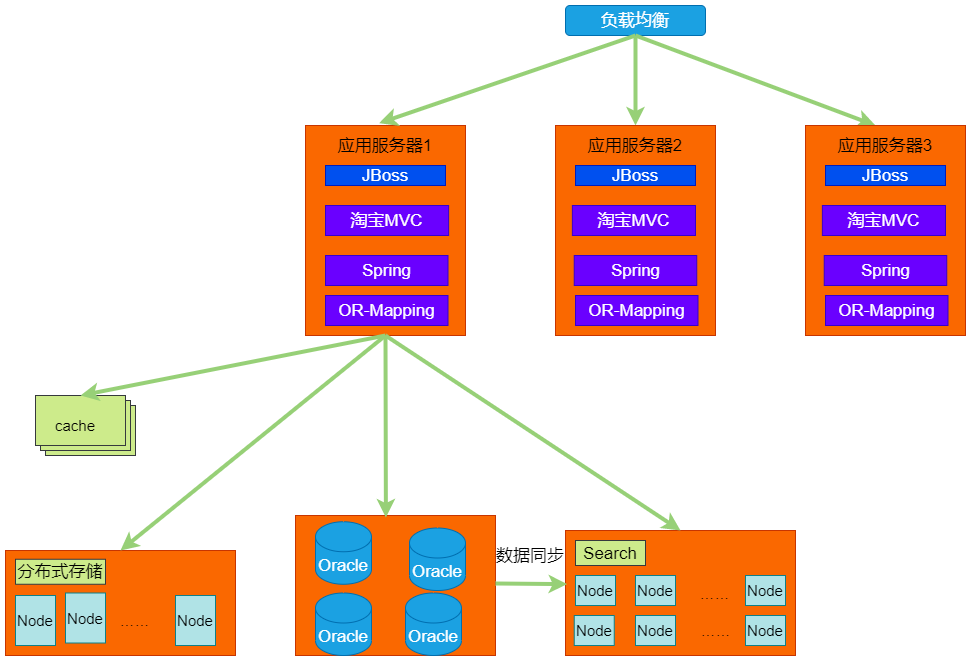
�ֲ�ʽʱ��1.0
����2008���ʱ���Ա���ҵ���һ����չ��
������վϵͳ�������Ѿ�����ƿ������Ʒ����1�ڸ����ϣ�PV��2.5�ڸ����ϣ���Ա�������� 5000�������ʱOracle�����ӳ��������������ˣ����ݿ���������˼��ޣ���ʹ�ϲ�ϵͳ�ӻ���Ҳ���������ݣ�����ֻ�аѵײ�Ļ������������֣��ӵײ㿪ʼ���ݣ��ϲ������չ������������Ժ��������������
�Ա���ʼ��ҵ��ģ����ֺͷ����졣�����ֳ�����Ʒ���ġ���Ʒ���ĵȵȡ�ͬʱ������һЩ���е��м������ֲ�ʽ���ݿ��м�����ֲ�ʽ��Ϣ�м���ȵȡ�
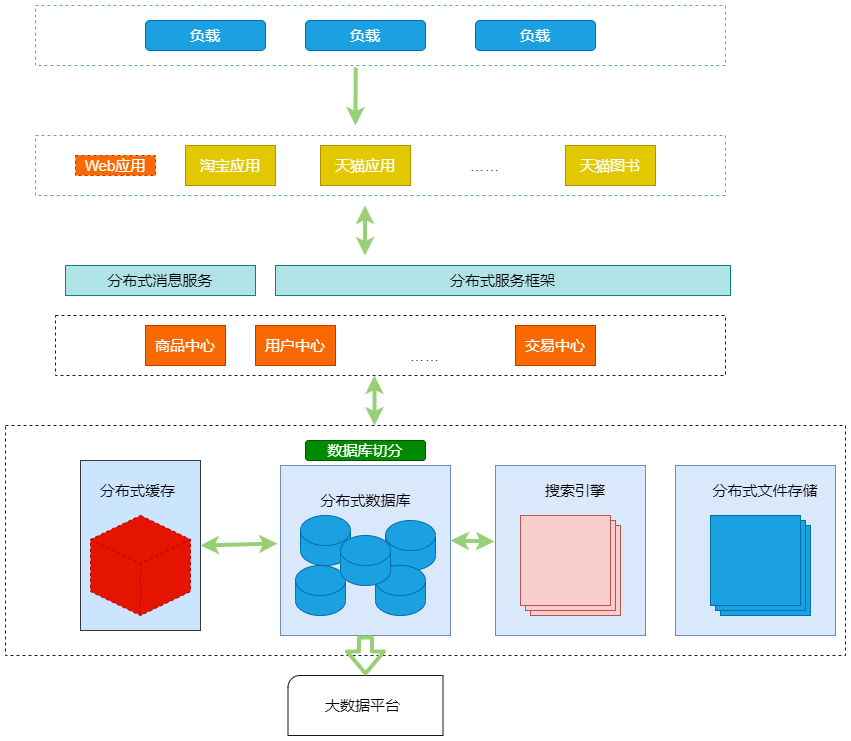
���Ա�������ʮ�꡷�Ȿ��ֻ��������2012�꣬Ҳ���Ƿֲ�ʽʱ������ͼ�Ǹ��ݲο���8������һ��ͼ��
ת����2012�ֿ����ʮ�꣬��ʮ�꣬����Ͱ����뼫ʢʱ����������Ҳ�Ƿ�����ӿ�����˱��������ȸ�ϸ�����������������������������������ƽ̨�������� ������Ա�������ʮ�꡷����������дһ��ʮ�꣬һ��Ҳ�Ƿdz����ʡ�
���ղο���10�������������Ա�����ʼ���ݽ�����ƽ̨�ܹ�����������ʵ�����ң�������ʱ�����Ա����������ڲ��ļܹ����Ӷ�����дһ�����ˡ����Խ������ļܹ��ݽ��ο�����˸߲����ֲ�ʽ�ܹ��ݽ�֮·����һ��ţ�����Ա�Ϊģ�������еļܹ��ݽ�����Ȼ�����Ա������ļܹ������ݽ�����Ҳ��ֵ�ý����
�����������Թ�������ܹ������ֲ�ʽʱ��2.0���������Ǹ�ϸ���ȡ����������ķ����������һ���������������˼��˵�����������ϸ��ϱ���˵��ƵĶ����������������ĸ�����������Լ�����������һ�������������ۣ��Ժ�������˵������ʦ�����ֲ���ѭ����ܹ���Ƶ�ԭ���ˡ��ţ���˵��һ�㲻���ϣ�������ȥ����������ۡ�
������ʱ��
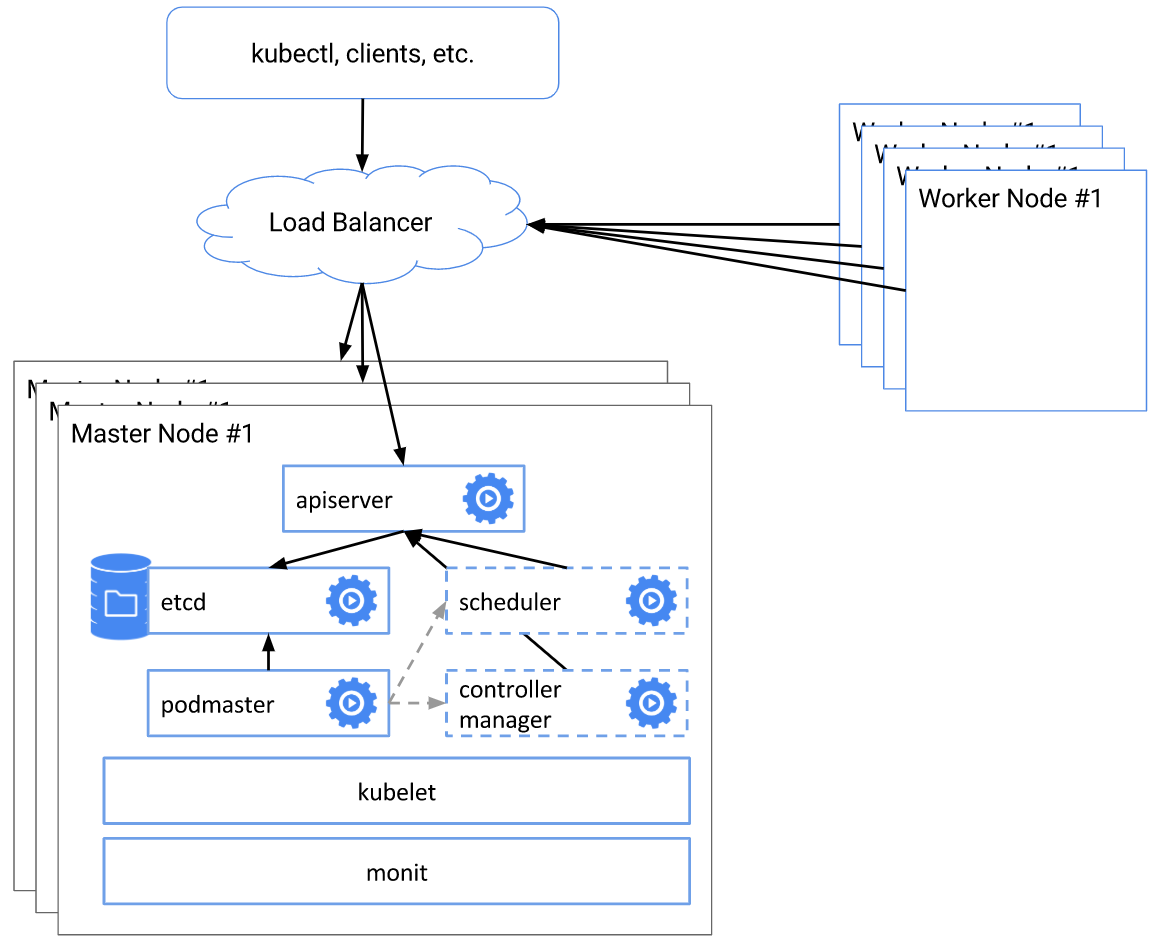
ǰ�����е�������������Docker�������е���������������Kubernetes(K8S)��Ӧ��/������Դ��ΪDocker����ͨ��K8S����̬�ַ��Ͳ�����Docker���������Ϊһ�����������Ӧ��/�������С�IJ���ϵͳ���������Ӧ��/��������д��룬���л�������ʵ�ʵ���Ҫ���úá�������������ϵͳ�����Ϊһ������Ϳ��Էַ�����Ҫ������ط���Ļ����ϣ�ֱ������Docker����Ϳ��ѷ�����������ʹ����IJ������ά��ü�
�ڴ�ٵ�֮ǰ�����������еĻ�����Ⱥ�ϻ��ֳ�������������Docker������ǿ��������ܣ���ٹ���Ϳ��Թرվ��Ի����ϵ������������Ӱ�졣
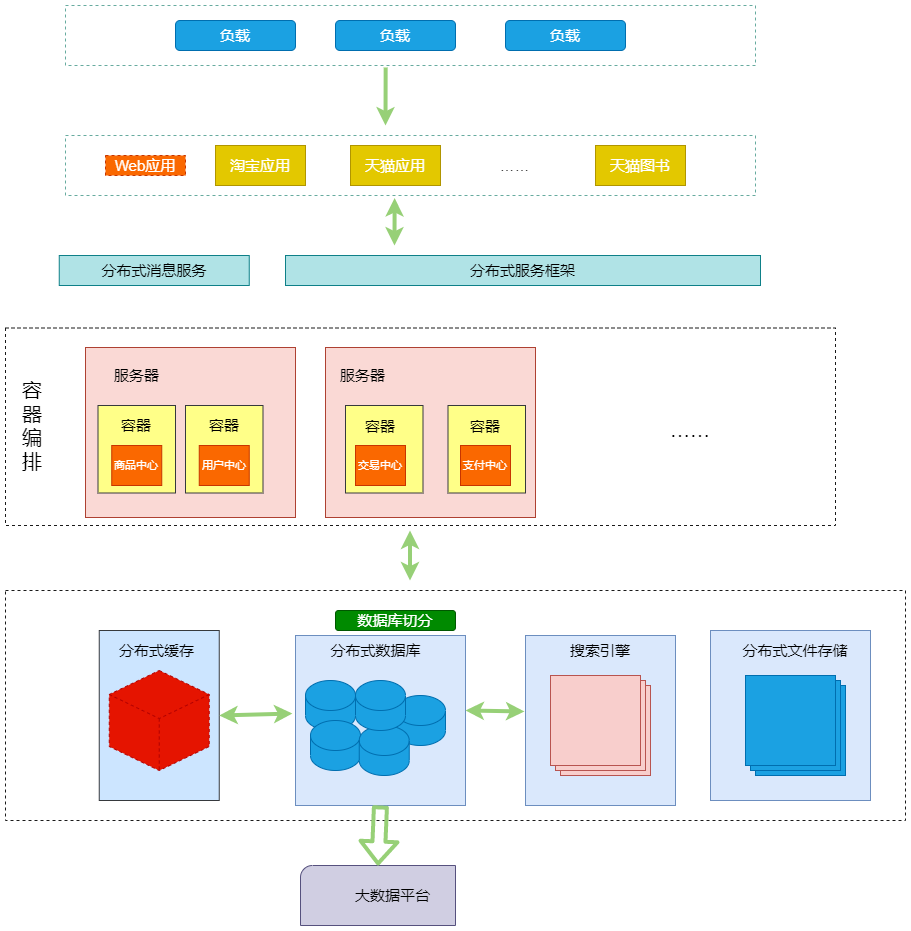
��ƽ̨ʱ��
�ڷ���ʱ���Ա��Ѿ��ݽ�������ƽ̨�ܹ���
��ν����ƽ̨�����ǰѺ���������Դ��ͨ��ͳһ����Դ����������Ϊһ����Դ���壬��֮�Ͽɰ��趯̬����Ӳ����Դ����CPU���ڴ桢����ȣ�������֮���ṩͨ�õIJ���ϵͳ���ṩ���õļ����������Hadoop����ջ��MPP���ݿ�ȣ����û�ʹ�ã������ṩ�����õ�Ӧ�ã��û�����Ҫ��ϵӦ���ڲ�ʹ����ʲô���������ܹ��������������Ƶת������ʼ������˲��͵ȣ���
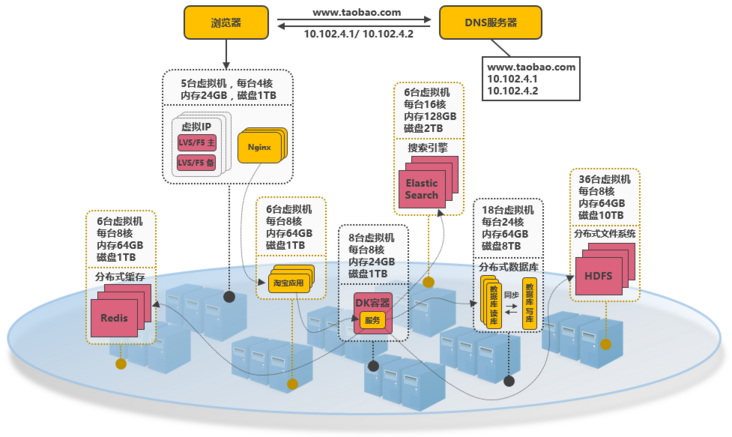
���ܽ�һ�����߲����ļܹ�ij�̶ֳ����DZƳ����ģ�һ����˭���뵽�Ա���������php����Ϊ����������ݿ����ӳص����⡣�ܹ��ݽ�������������ˮ����������ˮ������ʦ���ᣬ˵�������ף����澿�����˶��ٻ����˶��ٿӡ��������˿�����ƽ���ﲨ������ˮ����??��
�߲����ܹ�ʵ��
����ϵͳ��ס����IJ�������Ҫ������������
-
������չ��
1������������Ӳ�����ܣ�ͨ�������ڴ桢 CPU�������洢���������߽����� ������SSD�ȶ�Ӳ���ķ�ʽ������
2�������������������ܣ�ʹ�û������IO������ʹ�ò��������첽�ķ�ʽ������������
-
������չ�����������ܻ���ڼ��ޣ��������ջ���Ҫ���������չ��ͨ����Ⱥ�����Խ�һ����߲�������������
1�����÷ֲ�ܹ������Ǻ�����չ��ǰ�ᣬ��Ϊ�߲���ϵͳ����ҵ���ӣ�ͨ���ֲ㴦�����Լ������⣬����������������չ��
2���������ˮƽ��չ����״̬ˮƽ���ݣ���״̬����Ƭ·�ɡ�ҵ��Ⱥͨ������Ƴ���״̬�ģ������ݿ�ͻ�����������״̬�ģ������Ҫ��Ʒ��������ô洢��Ƭ����ȻҲ����ͨ������ͬ������д����ķ������������ܡ�
��һ����������Ҫȥ��ʮ���������Ǵ��ģ���õĽ���������Ǵ��㡪����������������ʱ��͵���취�ˡ���һ���취����Ŭ��������Ȼ��ȫ����װ��Ҳ�����е�ϣ���������������չ���ڶ����취�����У���һ�������˶࣬��ͽ���ʮ�Ÿ��ֵܣ�Ȼ�����Ƕ�ʮ��������ʮ�����������¿���ȥ�ܴ�Ĺ��ˣ�����Ǻ�����չ�����е����������õİ취�����Ҹ��Ű�ס��ÿ�ξͷ�һ����������һ���ٷ���һ���������������������������

���ǿ�һ��һ����ŵ�֧�����ߵĵ��ͼܹ���
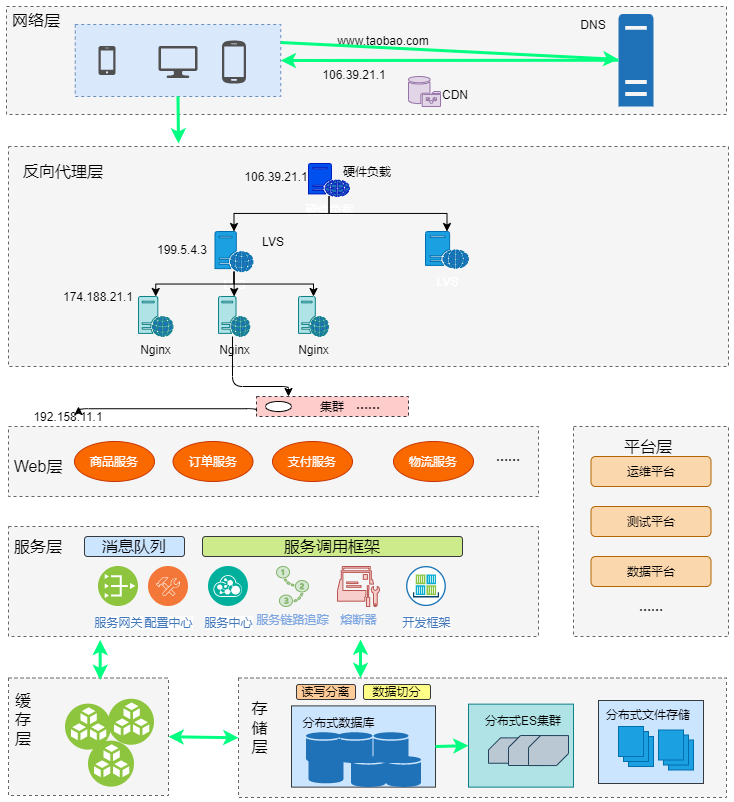
�����������Ǵ������£���һ�£������һЩ�ؼ�������
�����
�����
�ѻ����������ܵģ����ѻ����������ܵġ�
����Ŭ������������ܹ�������������ṩ�ķ����ܹ����ٺ�����չ��������չ�Ļ���ͬ����Ҫ��һ�������ġ�һ�����ܵĻ�����
���������ĸ���������Ҫ��ʮ��������Ŭ��������Ҷʦ������ͻȻ���ֶ���ĺ��Ӷ������ˣ�������2����ʱ���㻹�ǵý��ֵܡ�
һ�㹷����ȫ�����ض��л��������ܹⱱ�������������Ѳ�ͬ�ط�������ֵ���ͬ�Ļ������ٷֵ���ͬ�ļ�Ⱥ���ٷֵ���ͬ�Ļ�������ôһ�ȣ����ڷ����ܿ��ķ���֮���ˡ����Ǵ������һ�£���ô�������������������
- ͨ��QPS��PV���㲿���������̨��
��̨������ÿ��PV���㣺
��ʽ1��ÿ����PV = QPS * 3600 * 6
��ʽ2��ÿ����PV = QPS * 3600 * 8
���������㣺
���������� = ceil( ÿ����PV / ��̨������ÿ����PV )
ԭ����ÿ��80%�ķ��ʼ�����20%��ʱ�����20%ʱ�������ֵʱ��
��ʽ��( ��PV�� * 80% ) / ( ÿ������ * 20% ) = ��ֵʱ��ÿ��������(QPS)
��������ֵʱ��ÿ��QPS / ��̨������QPS = ��Ҫ�Ļ�����
һ���д�����ҵ��Ĺ�˾��ʵ���˶����������ͬ�Ƕ��������Ƕ���������������ȡ�Ϊ�˱�֤�����ԣ��ƴ����ֵĹ�˾��Ԥ�����������࣬һ��ᱣ֤�������Ǽ����ֵ�������������������Ҫ��Լ�ɱ��ģ�Ҳ���Կ��ǵ�ǰ���е���ƽ̨��֮ǰ�ȵ��¼���ʱ�����ʹӰ��������˲����Ʒ�������
DNS
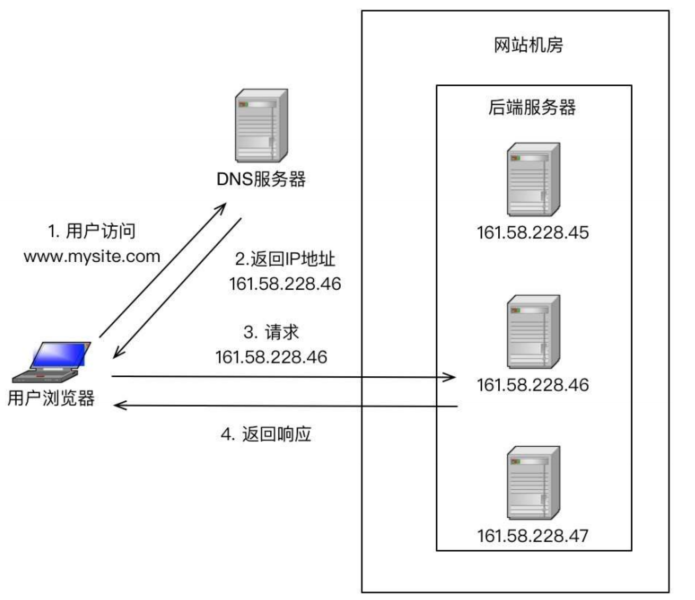
DNS������ַ��ĵ�һ���ؿڣ�ʵ�ֵ��ǵ�������ľ��⡣dns-server��һ�����������˶������ip��ÿ��DNS��������������dns-server��ͨ���᷵�����û�����ȽϽ���ip���û���ȥ����ip�����磬�������û����ʱ����Ļ������Ͼ����û������Ͼ�����Դ��
һ�㲻��ʹ��DNS������������ĸ��ؾ��⣬��Ϊ�첻��IP��Դʵ��̫�����ˣ�����ٶ�����������Ҫ����̨�����������ܸ�ÿ�����������ù���IP��һ��ֻ�������Ĺ���IP�Ľڵ㣬Ȼ��������Щ�ڵ�������������ĸ��ؾ��⣬�������������Ļ���ֻ��Ҫ���þ�����IP�����ˡ�
DNS���ؾ�����ŵ���ͨ�ã�ȫ��ͨ�ã����ɱ��ͣ�����������ע��DNS���ɣ���
ȱ��Ҳ�Ƚ����ԣ���Ҫ�����ڣ�
-
DNS �����ʱ��Ƚϳ�����ʹ��ij̨ҵ������� DNS ��������ɾ�������ڻ����ԭ�����кܶ��û�����������Ѿ���ɾ���Ļ�����
-
DNS ������DNS ���ܸ�֪��˷�������״̬��ֻ�ܸ������ò��Խ��и��ؾ��⣬�������������ĸ��ؾ�����ԡ�����˵ij̨���������ñ���������Ҫ�úܶ࣬��������˵Ӧ�ö����һЩ����������� DNS ��������һ�㡣
���Զ���ʱ�Ӻ������е�ҵ����ʵ���Ĺ�˾���᳢ܻ��ʵ��HTTP-DNS�Ĺ��ܣ���ʹ��HTTP Э��ʵ��һ��˽�е� DNS ϵͳ��HTTP-DNS ��ҪӦ����ͨ�� App �ṩ�����ҵ���ϣ���Ϊ�� App �˿���ʵ�����ķ��������ʲ��ԣ������ Web ҵ��ʵ�������ͱȽ��鷳һЩ����Ϊ URL �Ľ����������������ɵģ�ֻ�� Javascript �ķ��ʿ����� App ����ʵ�ֱȽ����Ŀ��ơ�
CDN
CDN��Ϊ�˽���û��������ʱ�ġ����һ���ЧӦ��������һ�֡��Կռ任ʱ�䡱�ļ��ٲ��ԣ��������ݻ��������û�����ĵط����û����ʵ��ǻ�������ݣ�������վ��ʵʱ���ʵ����ݡ�
����CDN������������Ӫ�̵Ļ�������Щ��Ӫ�������ն��û��������ṩ�̣�����û�����·�ɵĵ�һ���͵�����CDN����������CDN�д���������������Դʱ����CDNֱ�ӷ��ظ�����������·��������Ӧ���ӿ��û������ٶȡ�
�����Ǽ�CDN��������ʾ��ͼ��
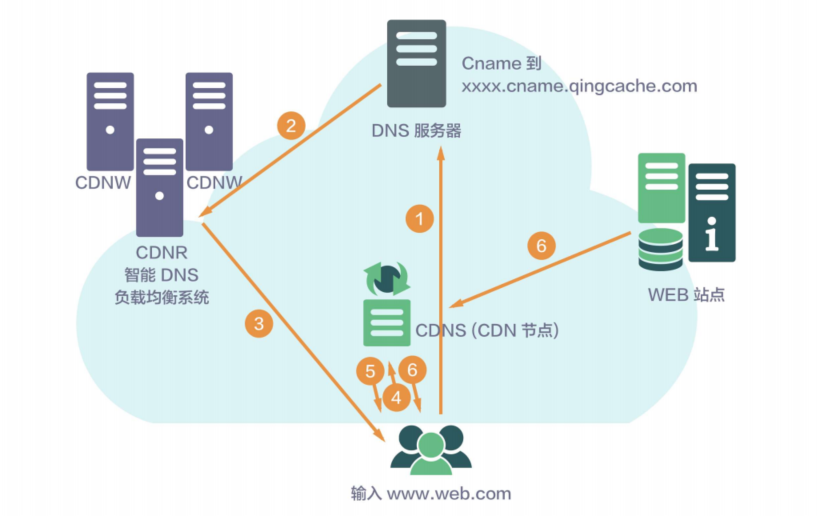
CDN�ܹ������һ���Ǿ�̬��Դ����ͼƬ���ļ���CSS��Script�ű�����̬��ҳ�ȣ�������Щ�ļ�����Ƶ�Ⱥܸߣ����仺����CDN�ɼ��������ҳ�Ĵ��ٶȡ�
���������
���ǰ���һ��з�������㣬Ҳ���Խн���㡢���߸��ز㡣��һ������������ڣ���ϵͳ�������ܹؼ���һ�㡣
�����Ǹ��������������ʮ������������ʮ�Ÿ��ֵܣ������������������������һ��������������̫��������������ǰ�棬���˲�䱻ʮ������
�����������������зַ�����֤�����䵽ÿ�������ϵ������Ƿ����ܿ��ķ�Χ֮�ڡ�
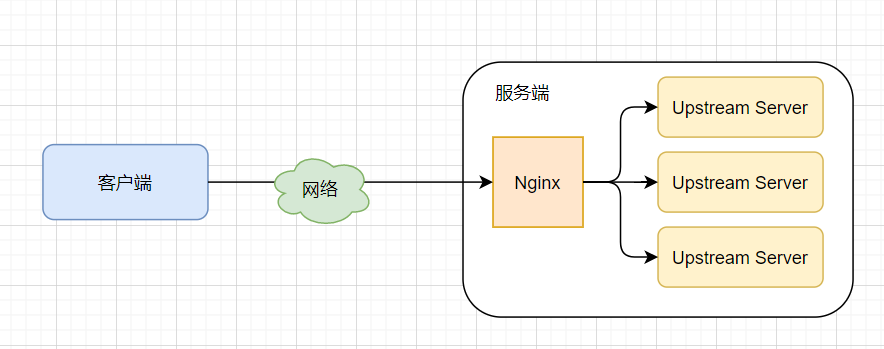
Nginx��LVS��F5
DNS ����ʵ�ֵ�������ĸ��ؾ��⣬�� Nginx�� LVS�� F5 ����ͬһ�ص��ڻ�������ĸ��ؾ��⡣���� Nginx �������� 7 �㸺�ؾ��⣬LVS ���ں˵� 4 �㸺�ؾ��⣬F5 ��Ӳ���� 4 �㸺�ؾ��⡣
������Ӳ����������������ܣ�Ӳ��ԶԶ����������Ngxin ����������һ��� Linux ��������װ�� Nginx ����ܵ� 5 �� / �룻LVS ��������ʮ����˵�ɴﵽ 80�� / �룻F5 �����ǰ����� 200 �� / �뵽 800 �� / �붼�С�
Ӳ����Ȼ���ܸߣ����ǵ�̨Ӳ���ijɱ�Ҳ�ܸߣ�һ̨����˵� F5 ���Ǽ�ʮ�����������ͬ����������������ɱ��Ļ���ʵ����Ӳ�����ؾ����豸���ܻ�����ˣ��������ÿ�봦�� 100 ��������һ̨ F5 ���ˣ����� Nginx, ����Ҫ 20 ̨���������������� F5 �ijɱ������͡����ͨ������£��������Ҫ�ߣ��������������ؾ��⣻�������Ҫ����{���Ƽ���Ӳ�����ؾ��⡣
4 ��� 7 ������������Э�������ԡ�Nginx ֧�� HTTP�� E-mail Э�飬�� LVS �� F5 �� 4�㸺�ؾ��⣬��Э���أ���������Ӧ�ö����������������졢���ݿ�ȡ�Ŀǰ�ܶ��Ʒ����̶��Ѿ��ṩ�˸��ؾ���IJ�Ʒ�����簢���Ƶ� SLB��UCIoud �� ULB �ȣ���С��˾ֱ�ӹ��ɡ�
���ڿ������ԣ�һ��ֻ��Ҫ��ע��Nginx��һ��������ˡ�

���ؾ�����ͼܹ�
�������ᵽ�ĸ��ؾ�����ƣ���ʹ���У��������ʹ�á�
DNS���ؾ�������ʵ�ֵ�������ĸ��ؾ��⣬Ӳ�������ؾ�������ʵ�ּ�Ⱥ����ĸ��ؾ��⣻�������ؾ�������ʵ�ֻ�������ĸ��ؾ��⡣

����ϵͳ�ĸ��ؾ����Ϊ���㡣
- ���������ؾ��⣺www.xxx.com �����ڱ��������ݡ��Ϻ��������������û�����ʱ��DNS ������û��ĵ���λ�������������ĸ������� IP��ͼ�з����˹��ݻ����� IP ��ַ�������û��ͷ��ʵ����ݻ����ˡ�
- ��Ⱥ�����ؾ��⣺���ݻ����ĸ��ؾ����õ��� F5 �豸��F5 �յ��û�������м�Ⱥ����ĸ��ؾ��⣬���û����� 3 �����ؼ�Ⱥ�е�һ�������Ǽ��� F5 ���û������� �����ݼ�Ⱥ 2�� ��
- ��������ĸ��ؾ��⣺���ݼ�Ⱥ 2 �ĸ��ؾ����õ��� Nginx, Nginx �յ��û�������û���������Ⱥ�����ij̨�������������������û���ҵ��������ҵ����Ӧ��
Nginx���ؾ���
������Ҫ������Nginx��һ��ĸ��أ�ͨ��LVS �� F5�����㶼����������ά����ʦ�ܿء�
���ڸ��ؾ���������Ҫ���ĵļ����������£�
-
���η��������ã�ʹ�� upstream server�������η�����
-
���ؾ����㷨�����ö�����η�����ʱ�ĸ��ؾ�����ơ�
-
ʧ�����Ի��ƣ����õ���ʱ�����η����������ʱ���Ƿ���Ҫ�����������η�������
-
������������飺���η������Ľ������/������顣
upstream server����ֱ�ӷ��������η���������˼���Ǹ��ؾ�����������ã����DZ�nginx���������ʵ���ʵķ�������
���ؾ����㷨
���ؾ����㷨�����϶࣬Nginx��Ҫ֧�����¼��ָ��ؾ����㷨��
1����ѯ��Ĭ�ϣ�
ÿ������ʱ��˳����һ���䵽��ͬ�ĺ�˷���������ij̨�������������Զ�������ϵͳ��ʹ�û����ʲ���Ӱ�졣
2��weight����ѯȨֵ��
weight��ֵԽ����䵽�ķ��ʸ���Խ�ߣ���Ҫ���ں��ÿ̨���������ܲ����������¡����߽���Ϊ�����ӵ���������ò�ͬ��Ȩֵ���ﵽ������Ч�ĵ�����������Դ��
3��ip_hash
ÿ��������IP�Ĺ�ϣ������䣬ʹ����ͬһ��IP�ķÿ̶�����һ̨��˷����������ҿ�����Ч�����̬��ҳ���ڵ�session�������⡣
4��fair
�� weight��ip_hash�������ܵĸ��ؾ����㷨��fair�㷨���Ը���ҳ���С�ͼ���ʱ�䳤�����ܵؽ��и��ؾ��⣬Ҳ���Ǹ��ݺ�˷���������Ӧʱ�� ������������Ӧʱ��̵����ȷ��䡣Nginx������֧��fair�������Ҫ���ֵ����㷨������밲װupstream_fairģ�顣
5��url_hash
�����ʵ�URL�Ĺ�ϣ�������������ʹÿ��URL����һ̨��˷����������Խ�һ����ߺ�˻����������Ч�ʡ�Nginx������֧��url_hash�������Ҫ���ֵ����㷨������밲װNginx��hash��������
ʧ������
Nginx����ʧ��������Ҫ�����������ã�upstream server �� proxy_pass��
ͨ���������η������� max_fails�� fail_timeout����ָ��ÿ�����η���������fail_timeoutʱ����ʧ����max_fail����������Ϊ�����η�����������/����Ȼ��ժ�������η�������fail_timeoutʱ�����ٴν��÷��������뵽������η������б��������ԡ�
�������
Nginx �����η������Ľ������Ĭ�ϲ��õ��Ƕ��Բ��ԣ�Nginx ��ҵ���ṩ��healthcheck �� �� �� �� �� �� �� �� ���� Ȼ Ҳ �� �� �� �� nginx_upstream_check_module( https://github.com/yaoweibin/nginx_upstream_check module ) ģ������������������顣
nginx_upstream_check_module ֧�� TCP ������ HTTP ������ʵ�ֽ�����顣
��������
�����ַ�
�����ַ��Ͳ���˵�ˣ������Ѿ����ˣ��ǽ����Ļ������ܡ�
�����л�
��������˵��һ������˼�����飬���ǹ�˾��������һ�������е���һ��������������������й���ʦ��άƽ̨һƬƮ�죬ȫ��˾����Χ�ۣ���ά�ŶӾͺܶ����ӡ�

�����л�������ijЩ����£�����������ϡ����˱��ڶϡ����������Ϲ�����������Ҷȷ�����A/B����ά���Գ�������Ҫ�������е���ͬ�Ļ������������ȵȡ�
�������������ᵽ�ĸ��ؾ�����ͼܹ�����ͬ�㼶�ĸ��ظ����л���ͬ�㼶��������
- DNS���л�������ڡ�
- HttpDNS����Ҫ APP �����£��ڿͻ��˷����������ڣ��ƹ���Ӫ�� LocalDNS��ʵ�ָ����������ȡ�
- LVS/HaProxy���л����ϵ� Nginx ����㡣
- Nginx���л����ϵ�Ӧ�ò㡣
���⣬��ЩӦ��Ϊ�˸������л����������� Nginx ��������л���ͨ�� Nginx ����һЩ�����л�����û��ͨ���� LVS/HaProxy ���л���
����
�����DZ�֤ϵͳ���õ�һ����Ҫ�ֶΣ���ֹ�����ɵ�����ֱ�Ӵ��ڷ����ϣ������㷨��Ҫ������Ͱ��©Ͱ��
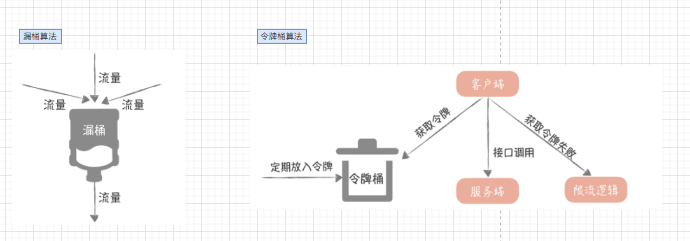
�����ںܶ��������������������������������Ϣ����������Redis��������Щ��Ҫ��ҵ���ϵ�������
����������Ҫ���۵��ǽ�����������ֱ�������������������
���� Nginx�������������ʹ�� Nginx�Դ�������ģ�飺����������ģ�� ngx_http_limit_conn_module ��©Ͱ�㷨ʵ�ֵ���������ģ�� ngx_http_limit_req_moduleo
������ʹ�� OpenResty�ṩ�� Lua����ģ�� ua-resty-limit-trafficӦ�Ը����ӵ�����������
limmit_conn������ij�� key ��Ӧ���ܵ����������������������������� IP������ά�Ƚ���������limit_req������ij�� key��Ӧ�������ƽ�����ʽ�������,�������÷���ƽ��ģʽ��delay ) ������ͻ��ģʽ��nodelay )��
��������
�ܶ�ʱ��һ����վ�кܶ���������������������ֱ���Ƕ����������
�����ڽ���㣬������IJ�������У�飬�������У�鲻�Ϸ�����ֱ�Ӿܾ������߰������ר�����������Ƿ�����ķ���
�����ʹ��Nginx��ʵ�ʳ������ܻ�ʹ��OpenResty�������� user-agent ���˺�һЩ����IP (ͨ��ͳ�� IP ��������������ֵ���������Ƿ������̶����飬������������һ���̶ȵ���ɱ����Ϊ��˾�Ĺ��� IP �����������ͬһ�������ʹ��ͬһ���������� IP ������վ����ˣ����Կ��� IP+Cookie �ķ�ʽ�����û��������ֲ��ʶ�û����ݵ�Ψһ Cookie�����ʷ���ǰ����ֲ Cookie, ���ʷ���ʱ��֤�� Cookie, ���û�л��߲���ȷ������Կ��Ƿ������̶����飬������ʾ������֤�����ʡ�

����
����Ҳ�DZ�֤�߿��õ�һ��������������˼·�ǡ�������˧�������ۿ��Ų��ܱ�֤ȫ�ֿ��õ�����£�������������һЩ����Ҫ�ķ���
����һ���Ϊ����㼶��������Ӧ�ò���н�����ͨ�������������ý�������ֵ��һ���ﵽ��ֵ�����ݲ�ͬ�Ľ������Խ��н�����
Ҳ���ѽ�������ǰ�õ�����㣬�ڽ�������ù��ܽ���������Ȼ�����������Զ�/�˹����������Ӧ�÷��������ʱ��ͨ������㽵�������Ա�����ν�������ٴ�˷��Ӷ���Ӧ�÷������㹻��ʱ��ָ�����
Web��
����һϵ�еĸ��ؾ��⣬�û�����������web��ķ���web������ɣ���������������web�������и��û��ṩ����
��Ⱥ
һ������ҵ��ģ�飬�����ֲ�ͬ�ķ���һ����������ʵ����ɼ�Ⱥ��
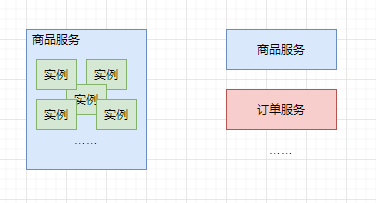
Ϊ�˸�����ϣ������ٽ���Ⱥ���з��飬����һ������������⣬Ҳ����Ӱ���������顣��Ƚϳ��ʵ���ɱ��ͨ���Ὣ��ɱ�ķ���Ⱥ����ͨ�ķ���Ⱥ���и��롣
��������Ⱥ�����������Ҫ������״̬����֡�����
- ��״̬����Ƶ�Ӧ������״̬�ģ���ôӦ�ñȽ�������ˮƽ��չ��
- ��֣���Ƴ��ڿ��Բ��ò�֣����Ǻ��ڷ��������ʱ�Ϳ��Կ��ǰ����ܲ��ϵͳ����ֵ�ά��Ҳ�Ƚ�������ʵ�������ѡ���������ϵͳά�ȡ�����ά�ȡ���дά�ȡ�AOP ά�ȡ�ģ��ά�ȵȵȡ�
- ������ָ��������ƣ���������أ�����һ�㶼�÷������������⡣�����������Զ�̵��ã����ÿ��Ǹ��ؾ��⡢�����֡�������롢����������������ʺڰ������ȡ���������ϸ����Ҫ���ǣ��糬ʱʱ�䡢���Ի��ơ�����·�ɡ����ϲ����ȡ�
Web������
��������һ������� Web ���������ɱ��dz��ߣ�����ҵ��������ô�����Ŀ�Դ Web �����������Ի�������ҵ�����϶��� "��������" ����ѡһ�����еĿ�Դ���������ɡ���һ��Ĺ�˾�����ܻ��ڿ�Դ�������Ļ����ϣ�����Լ���ҵ���ص������ο����������Ա��� Tengine,��һ�㹫˾������ֻ��Ҫ����Դ�����������Ż�һ�²���������һ�����þͲ���ˡ�
��������ѡ����Ҫ�Ϳ���������أ����磬Java ���� Tomcat��JBoss��Resin ��,PHP/Python ���� Nginx��
Web������������֮���һ�㲻���Ϊƿ��������Java�����е�Web������TomcatĬ�����õ������������ 150������û�й�ϵ����Ⱥ��������ˡ�
����
�������������ſ�ʼ�������ģ������� Docker Ϊ�������� BAT ����Ĺ�˾�Ѿ��н϶��Ӧ�á�
����������˵����ά�����˸����Եı仯��Docker �����죬������ռ��Դ����ʱ������ֹͣ������Docker �����Զ�����ά�����ܻ���ά��Ϊ������ʽ��
����������Ҳ�����ʺϵ�ǰ���е�����������������̺�Ӧ�ó�����뵽��С��ʵ���ʹ�ø��ٵ���Դ������ݵز��𡣽���������ż��������Ը�������ٵش����߿��ü�Ⱥ��
�����
�������
һ�㣬��������˾����ָ��һ����ļ�������Ȼ��ʹ��ͳһ�Ŀ�����ܡ����磬Java ��صĿ������ SSH��SpringBoot, Ruby �� Ruby on Rails, PHP �� ThinkPHP, Python ��Django �ȡ�
��ܵ�ѡ����һ���ܵ�ԭ����ѡ����Ŀ�ܣ�����äĿ���¼���!
����һ�����˿�����ԣ���������Ҫ��������������������֮�¡����ڿ������ԺͿ�ܵ�ʹ�ã�һ��Ҫ����˽���������ԺͿ�ܵ����ԡ�
��JavaΪ���������ߵĿ����У��漰��һ�����ܽ��ܵķ�����ã������ṩ��������JNI�ļ���������˵����C���Ա�д���룬�ṩapi��Java���ã��ֲ���Java���û��ô�ײ�����ƣ���������������ٶȡ�
�ڷ�������ճ������IJ��棬����������Щ������������ܣ�
- ����������ͨ�����߳̽����������л���
- ����IO�������������ݿ�ͻ����������д��RPC�������ӿ�֧�֡�����ͨ���������ݵķ�ʽ�ɵ�RPC���á�
- ����IOʱ�����ݰ���С������������������ͨ��Э�顢���ʵ����ݽṹ��ȥ���ӿ��еĶ����ֶΡ����ٻ���key�Ĵ�С��ѹ������value�ȡ�
- �������Ż������罫��������ִ�����̵��ж���ǰ�á�Forѭ���ļ������Ż������߲��ø���Ч���㷨
- ���ֳػ�������ʹ�úͳش�С�����ã�����HTTP����ء��̳߳أ�����CPU�ܼ��ͻ���IO�ܼ������ú��IJ����������ݿ��Redis���ӳصȡ�
- JVM�Ż���������������������Ĵ�С��GC�㷨��ѡ��ȣ������ܼ���GCƵ�ʺͺ�ʱ��
- ��ѡ����д�ٵij������ֹ��������߿���ͨ���ֶ����ķ�ʽ��������ͻ��
����ͨ����Щ��������߿����ԣ�
- ���ú��ʵij�ʱʱ�䡢���Դ��������ƣ���ҪʱҪ��ʱ���������ض������ݵȣ���ֹ�ѷ����᷽�����
- ������ƣ�ͨ������key�����ر��ȷ�ʽʵ�ַ���
- �ݵ���ƣ��ڽӿڲ���ʵ���ݵ����
��������
��ϵͳ���������ʱ��ϵͳ��ĵ���һ�㶼��ֱ��ͨ�������ļ���¼�ڸ�ϵͳ�ڲ��ģ�����ϵͳ���������Ժ����ַ�ʽ�ʹ��������ˡ�
����˵�ܹ��� 10 ��ϵͳ���� A ϵͳ�� X �ӿڣ�A ϵͳʵ����һ���½ӿ� Y, �ܹ����õ��ṩԭ�� X �ӿڵĹ��ܣ����Ҫ�����е� 10 ��ϵͳ���л��� Y �ӿڣ����� 10 ��ϵͳ�ļ�ʮ�ϰ�̨�������ö�Ҫ�ģ�Ȼ�������������֪���Ч���Ǻܵ͵ġ�
�������ĵ�ʵ����Ҫ���÷�������ϵͳ��
- ����������ϵͳ (Service Name System)
����������룬��������������뵽 DNS, �� Domain Name System��û�������ߵ������ǻ������Ƶġ�
DNS �����ý���������Ϊ IP ��ַ����Ҫԭ�������ǼDz�ס̫������� IP, ����������ס����������ϵͳ��Ϊ�˽� Service ���ƽ���Ϊ "host + port + �ӿ�����" �����Ǻ� DNSһ����������������Ļ�������
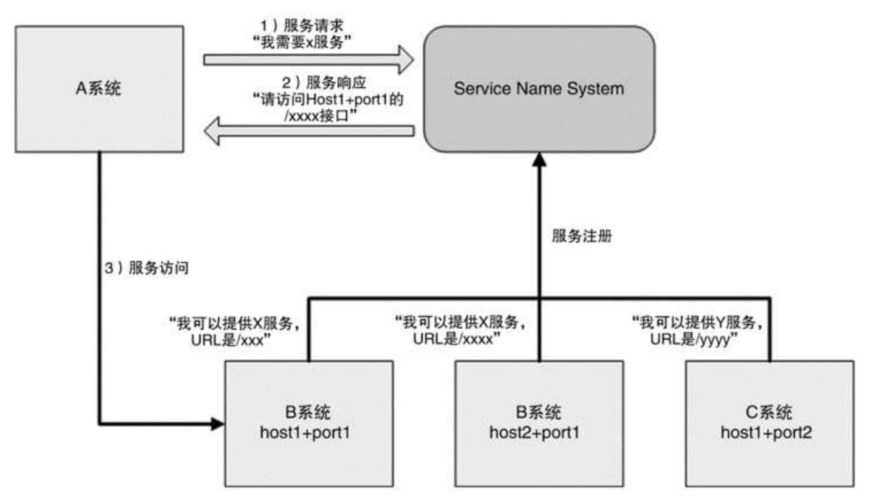
������ļܹ��£�ʵ��������ܵij�֮Ϊע�����ģ�������Java������ϵ�£���Դ��ע��������Nacos��Ecuraka�ȡ�
��������
�������ľ��Ǽ��й���������������á�
�ڷ����ʱ����������Թ����Լ������ã�û�����⣬���ǵ�����ɰ���ǧ���ٸ�������������һ���Ƚ�ͷ�۵��¡�
���Խ��������ij���ɹ�����������������ö��ϵͳ������Ч�ʸߡ�
������ܹ���ϵ�£��������ĵĿ�Դ������SpringCloud��SpringCloud Config�������Nacos�ȡ�